

目次
ポケモンのデータを取得するPokeAPI
今回は皆さんご存知の「ポケモン」に関するデータを、APIを利用して簡単に手元で扱えるようにする方法をご紹介します
アニメやゲームで有名なポケットモンスター(ポケモン)ですが、2021年現在、897匹ものモンスターが存在しています
そして各ポケモンそれぞれにユニークな能力、見た目が与えられています
今回は「Python」のAPI機能を利用して、ポケモンの情報を簡単に取得する方法をご説明します
PokeAPI
ポケモンの情報を取得できるPoke APIの公式サイトはこちらから
※リファレンスはしっかりしていますが、全て英語で書かれています
事前準備
APIでのデータ取得に必要なrequestsと、DataFrameの処理に必要なPandasを事前にインポートしておきましょう
import requests
import pandas as pdPokeAPIを利用しポケモンの基本情報を取得する
まずはポケモンの基本的な情報(名前やタイプ、ステータス)をAPIから取得します
※単純にコードを記述するだけではなく、それぞれ説明していきます
最終的には繰り返し処理を用いて、全ポケモン分のデータを取得しますが、まずはNo1のフシギダネのデータから取得しましょう
① エンドポイント(URL)の確認
まずはPokeAPIのエンドポイント(URL)を指定します
基本は下記のURLを利用します
そこからポケモンの情報を取得したい場合は/pokemonをURLに追加したり、
進化に関する情報を取得したい場合は/evolution-chainをURLを追加したりします
さらに上記URLの末尾に「ポケモン固有のID」か「英語のポケモン名」を指定すれば、そのポケモンの情報を取得することができます
「ピカチュウ」は「ID=25」で「pikachu」という名前です

Pythonの繰り返し処理を実施するために、ポケモンのURL指定は数値(1.2.3…)で指定します
② GETリクエストでデータを取得
さっそくフシギダネのデータを取得していきましょう
# 事前にrequestsをインポートしておく
import requests
# フシギダネ(No.1)の基本情報を取得するエンドポイント(URL)
url = "https://pokeapi.co/api/v2/pokemon/1"
# GETリクエストでデータを取得し、JSON形式に変える
response = requests.get(url)
pokemon_data = response.json()
# データを見る
pokemon_data
JSON形式でフシギダネのデータを取得することができました
ただし/pokemon では「名前」や「タイプ」「高さ」などのデータに加えて、「ゲーム時の情報」や「形」など必要以上に細かいデータが入っています
③ 取得したいデータの指定
JSON形式のデータは取得できたので、あとは必要なデータを絞るために添え字で情報を限定します
名前を取得するためにpokemon_dataのJSON形式の変数に対し、下記を指定します
# JSON形式の変数に対し、名前を指定する
pokemon_data['name']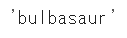
「bulbasaur」という文字列が出てきました
これは英語名で、日本語では「フシギダネ」のことです

他にもデータを取得してみます(ID、名前、高さ、重さ)
また変数に格納してprintで出力してみます
# ID、名前、高さ、重さを変数に格納する
id = pokemon_data['id']
name = pokemon_data['name']
height = pokemon_data['height']
weight = pokemon_data['weight']
print(id,name,height,weight)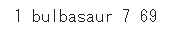
④ DataFrameに格納
データ分析に適した形に変換するために、JSON形式で取得できたデータをPandasのDataframeに格納していきます
繰り返し処理でも利用するため変数をかませる方法を使用しています
# 事前に変数を作成
result = []
# 情報を変数に格納
id = pokemon_data['id']
name = pokemon_data['name']
height = pokemon_data['height']
weight = pokemon_data['weight']
# resultという変数に、上記情報を追加(append)する
result.append([id,name,height,weight])
# resultをDataFrameの形式に変換
df = pd.DataFrame(result,columns=['id','name','height','weight'])
df.head()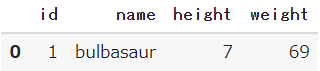
appendを利用し、JSON形式で取得したデータをDataFrameに格納する処理を実施しました
⑤ 繰り返し処理で複数のポケモンの情報を取得
forを利用して「No.1:フシギダネ」から「No.10:キャタピー」の情報を取得します
また繰り返し処理の過程でDataFrameへ都度格納していくと、最終的に各ポケモンのデータが取得できます
# 取得するポケモン数を決めておく(今回は10匹)
number = 10
result = []
# forを利用し、1から10までの繰り返し処理を実施
for i in range(1,number+1):
# URLの末尾にrangeの数値を入れる
url = "https://pokeapi.co/api/v2/pokemon/" + str (i)
response = requests.get(url)
pokemon_data = response.json()
id = pokemon_data['id']
name = pokemon_data['name']
height = pokemon_data['height']
weight = pokemon_data['weight']
result.append([id,name,height,weight])
df = pd.DataFrame(result,columns=['id','name','height','weight'])
df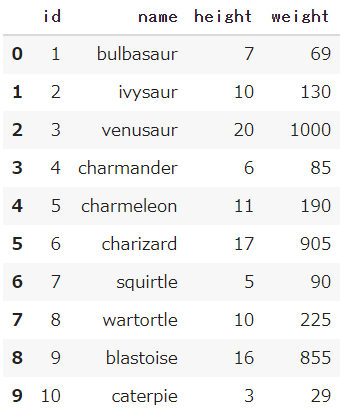
上記手法では変数をカラム分書く必要があるため、もっと簡単にかける方法を利用します
また「types:タイプ」「stats:ステータス」「sprites:ポケモン画像」を追加で取得します
number = 10
# 必要なカラムをリストで用意しておく
required_tags = ['id','name','height','weight','types','stats','sprites']
result = []
for i in range(1,number+1):
url = "https://pokeapi.co/api/v2/pokemon/" + str (i)
response = requests.get(url)
pokemon_data = response.json()
# JSON形式の変数からKeyを順に取り出し、先ほどのリストに当てはまらなかったら削除(不要なKeyを消す)
for key in list(pokemon_data.keys()):
if key not in required_tags:
del pokemon_data[key]
result.append(pokemon_data)
df = pd.DataFrame(result)
df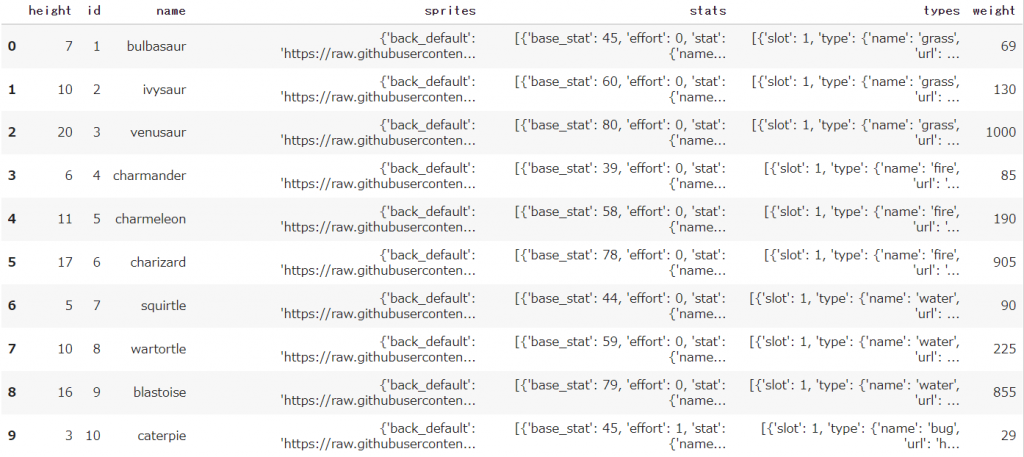
この書き方だと取得するカラム数が増えたとしても、簡潔に記述することが可能です
また新しく追加したカラムをよく見ると、単純なデータではなく「ネストされた値」になっています
⑥ ネストされた値を取得する
先ほど設定したDataFrameの「stats」というカラムを見ると、さらに複雑な形をしています
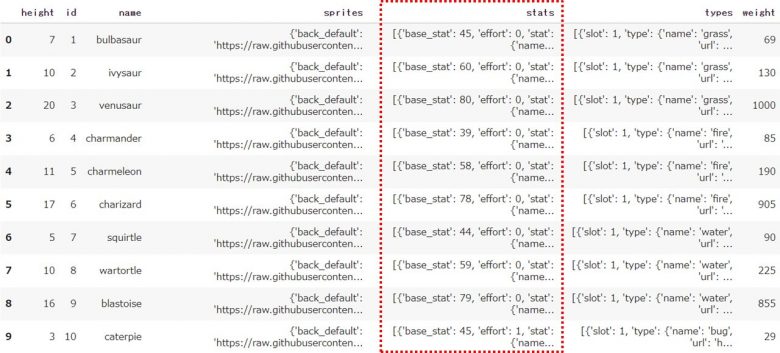
「stats」だけを取り出してみます
df['stats']
ここから「フシギダネ」のNo.1を指定するためには[0]添え字を付けます
# フシギダネを指定
df['stats'][0]
さらに複雑な形式になっていますが、一段目にhp(体力)・二段目にattack(こうげき)というように
ポケモンのステータスがそれぞれの段に格納されています
詳細化していくと、どんどん情報が絞られていきます
# フシギダネのこうげきステータスを指定
df['stats'][0][1]
# フシギダネのこうげきステータスの値(base_stat)を指定
df['stats'][0][1]['base_stat']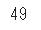
最終的に「こうげき:49」という値を取得することができました
かなり細かい指定方法になってしまいしたが、これをDataFrameとして格納していきます
先ほどのDataFrameの「stats」の情報を、別の変数として取り出します
結合ができるように「id」の情報も合わせて取得しておきましょう
# 事前にリストを準備
stats_list = []
# 先ほどのDataFrameのデータ数をshapeで取得し、必要情報をリストに追加
for i in range(df.shape[0]):
stats_list.append([
df['id'][i],
df['stats'][i][0]['base_stat'], #hp
df['stats'][i][1]['base_stat'], #attack
df['stats'][i][2]['base_stat'], #defense
df['stats'][i][3]['base_stat'], #special-attack
df['stats'][i][4]['base_stat'], #special-defense
df['stats'][i][5]['base_stat'], #speed
df['sprites'][i]['other']['official-artwork']['front_default'] #ポケモン画像
])
# 別名のDataFrameとして追加しておく
df_stats = pd.DataFrame(stats_list,columns=['id','hp','attack','defense','special-attack','special-defense','speed','png'])
df_stats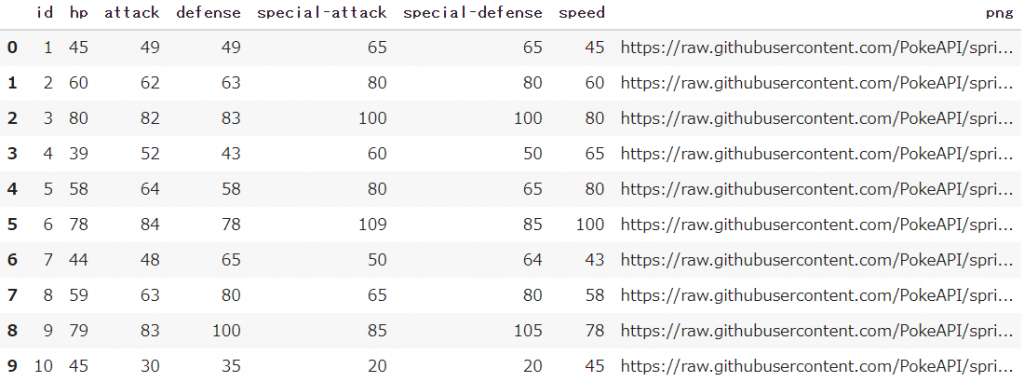
⑦ 基本情報とステータスをIDで結合
最初に取得していたデータ(df)と、ステータスを分解したデータ(df_stats)をIDで結合します
df = df.merge(df_stats, on='id', how='left')
df.dtypes
データ数が多いためdtypesでカラム名のみ可視化しています
「name:名前」や「height:高さ」に加えて、「hp:体力」や「attack:こうげき」などの情報が追加されました
 【Python】merge|2つのデータを結合する方法
【Python】merge|2つのデータを結合する方法 ⑧ 情報が無い場合の分岐処理
「ステータス」に関しては必ずデータが存在していましたが、データがある場合とない場合があるものも存在します
例えばポケモンの「タイプ」は1種類だけ持っている場合と、2種類持っている場合があります
リザードン(charizard)は「ほのお」と「ひこう」の2種類持ちです

# リザードン(「ほのお」と「ひこう」の2種類のタイプ持ち)
df['types'][5]
図のように「fire:ほのお」と「flying:ひこう」の二段のデータが存在します
今回問題になるのが、タイプが1つだけの場合です
リザードンの進化前であるヒトカゲ(charmander)は「ほのお」タイプのみです

# ヒトカゲ(「ほのお」タイプのみ)
df['types'][3]
繰り返し処理を実施する際に2つ目のタイプが無い場合は、指定してしまうとエラーが出てしまいます
そこでtry・exceptを活用して、2つ目のタイプが無い場合はNullを入れる処理を実施します
# Numpyを準備する
import numpy as np
type_list = []
for i in range(df.shape[0]):
# タイプ1とタイプ2をリストに入れる(最初の処理)
try:
type_list.append([
df['id'][i],
df['types'][i][0]['type']['name'],
df['types'][i][1]['type']['name']
])
# タイプ1とNullをリストに入れる(最初の処理で失敗したときの処理)
except:
type_list.append([
df['id'][i],
df['types'][i][0]['type']['name'],
np.nan
])
df_types = pd.DataFrame(type_list,columns=['id','type1','type2'])
df_types
※IDとタイプしか出力されないため、名前を取得しております
タイプが1つしかない ヒトカゲ(charmander) の「type2」はNaNになっています
⑨ ポケモンの日本語名を取得
ポケモンの英語名だと分かりにくいため、日本語名を取得します
エンドポイント(URL)は/pokemon-speciesを利用します
required_tags = ['id','name','names']
result = []
x = 0
while x < number:
x=x +1
url = "https://pokeapi.co/api/v2/pokemon-species/" + str (x)
response = requests.get(url)
pokemon_data = response.json()
for key in list(pokemon_data.keys()):
if key not in required_tags:
del pokemon_data[key]
result.append(pokemon_data)
result
df_species = pd.DataFrame(result)
df_species.head()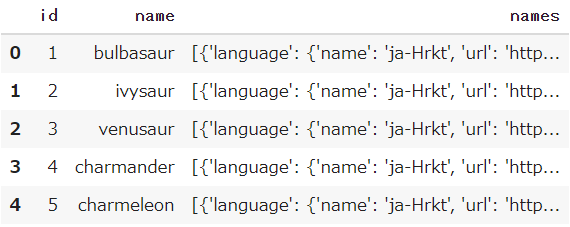
「names」には各国のポケモンの呼び方が存在しています
df_species['names'][0]
繰り返し処理で日本語名とIDのDataFrameを作成します
name_list = []
for i in range(df_species.shape[0]):
name_list.append([
df_species['id'][i],
df_species['names'][i][0]['name']
])
df_name = pd.DataFrame(name_list,columns=['id','ja_name'])
df_name.head()
IDをキーとして結合をすれば完成です
df = df.merge(df_name, on='id', how='left')まとめ
今回はPythonのAPIを利用して簡単に手元で扱えるようにする方法をご紹介してきました
PokeAPIを利用することで簡単にポケモンの情報を取得することができます
繰り返し処理を全ポケモン分で実施することで、全てのポケモンの情報を取得します
最終的にはこのようなデータが完成しました
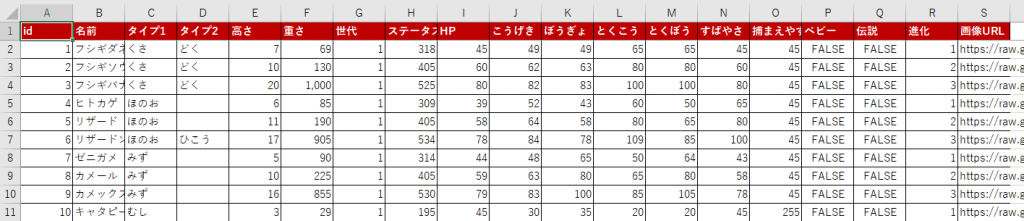
Excelデータもご用意しているので、ぜひ手元で確認してみてください
 ポケモンで学ぶPython|#1 セットアップを始めよう
ポケモンで学ぶPython|#1 セットアップを始めよう 

