 Smart-Hint
Smart-Hint 
目次
機械学習のバリデーション(検証)を行う
機械学習で予測モデルを作成する目的は、「未知のデータ」に対して精度の高い予測を行うことです
その予測モデルがどのくらいの精度なのか?を正しく検証するにはどうすればよいのでしょうか?
今回は機械学習の予測において精度を検証する「バリデーション(検証)」についてご紹介します
また次の記事でバリデーションを実施する、Pythonのtrain_test_splitとKFoldの活用方法もご紹介します
バリデーションのイメージ
バリデーション(検証)のイメージをご説明します
予測モデルをすでに手元にある「分かっているデータ」を使って作成し、分からないデータに対して「予測」を実施します

もちろん「予測したい」データは分からないので、「すでに分かっている」データを使ってモデル検証していきます
分かっているデータの一部を、「分からないふり」をして予測をしていきます

これなら正解があるので答え合わせができるようになります

実際には「12」だった人に対して「14」と予測しています
今回は「そこそこの精度」としていますが、評価指標については別記事で説明しています
バリデーションの2つの手法
バリデーションの手法として、2つの有名な手法が存在しています
- hold-out法
- クロスバリデーション
2つともすでに手元にあるデータを使って、モデルの評価を行います
それぞれPythonの関数、クラスも合わせてご紹介します
hold-out法
まずは「hold-out法」についてご説明します
学校のデータを説明変数とし、点数を目的変数としています
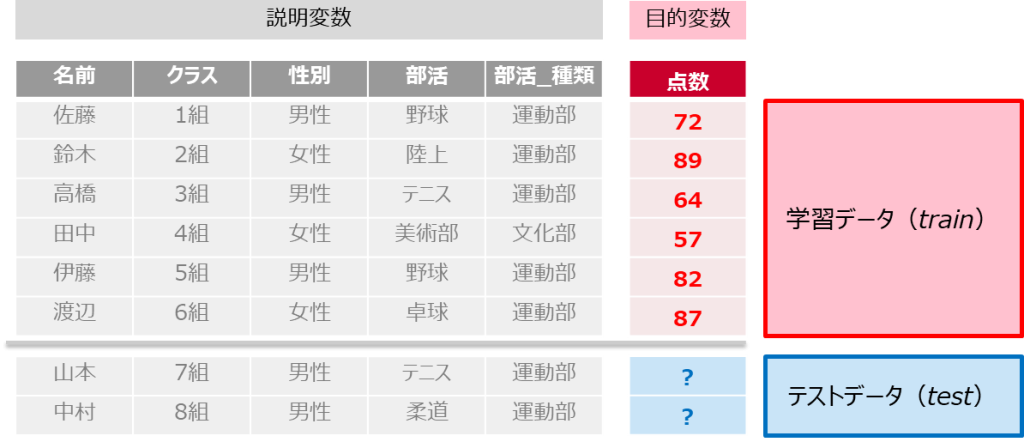
すでに点数が分かっている「学習データ」と、点数を予測したい「テストデータ」が存在しています
hold-out法では「学習データ」の一部を学習に使わず、バリデーション(検証)用に取っておきます
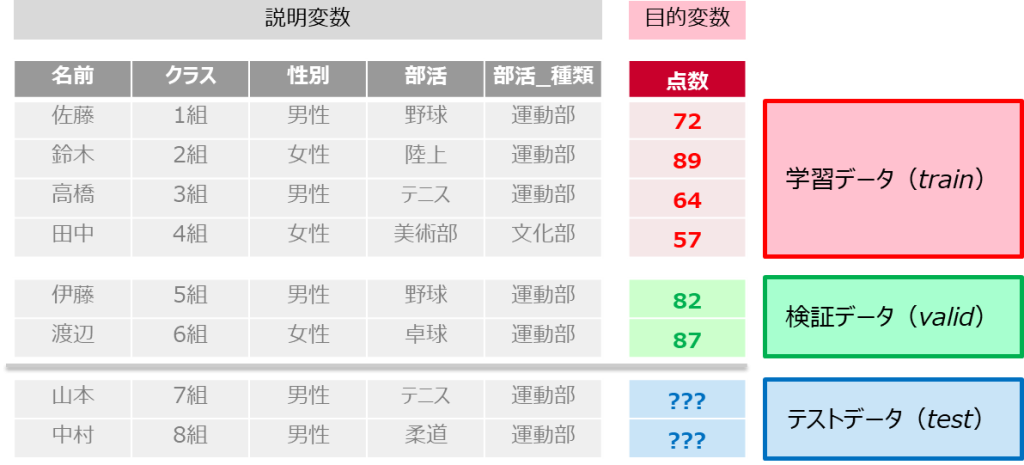
残りの「学習データ」でモデルを学習したうえで、「バリデーション(検証)データ」でモデルを評価します
これにより未知のテストデータに対して予測をする、いわゆる「模擬試験」を実施することができるのです
クロスバリデーション
続いて「クロスバリデーション」は「hold-out法」を複数回繰り返し評価を行います
データの偏りによる影響を小さくし、全ての学習データで評価を行うことが可能です

学習データを複数分割(イメージでは3分割)して、その分割した数だけ評価を行います
そして分割した分のスコアを平均して、最終的な評価を行います
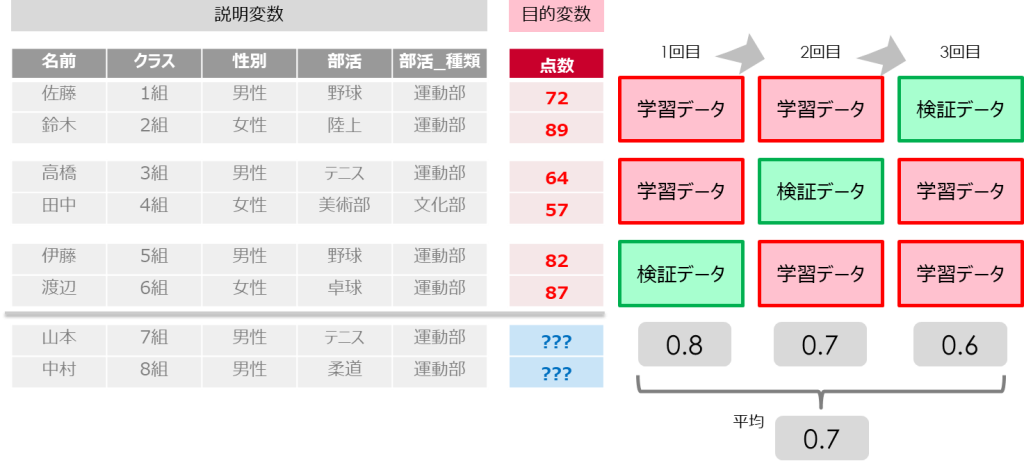
クロスバリデーションは分割の数を増やせば増やすほど、多くの学習データを利用できるため、精度が高くなります(全体と近い評価になる)
一方でデータ量が増えることで時間が多くかかってしまうため、4回くらいが目安として利用されることが多いです
Pythonでの実施方法
「hold-out法」をPythonで行うにはtrain_test_splitを利用します
「クロスバリデーション」をPythonで行うにはKFoldを利用します
 【機械学習】学習-テストデータに分割(hold-out法)|train_test_split
【機械学習】学習-テストデータに分割(hold-out法)|train_test_split
 【機械学習】KFoldでクロスバリデーションを実施する方法|KFold
【機械学習】KFoldでクロスバリデーションを実施する方法|KFold
まとめ
今回は機械学習のモデルを評価する際のテクニックとして「バリデーション(検証)」をご紹介してきました
「hold-out法」と「クロスバリデーション」の手法は非常に便利で、機械学習でよく利用されるため覚えておいてください


