 Smart-Hint
Smart-Hint 
目次
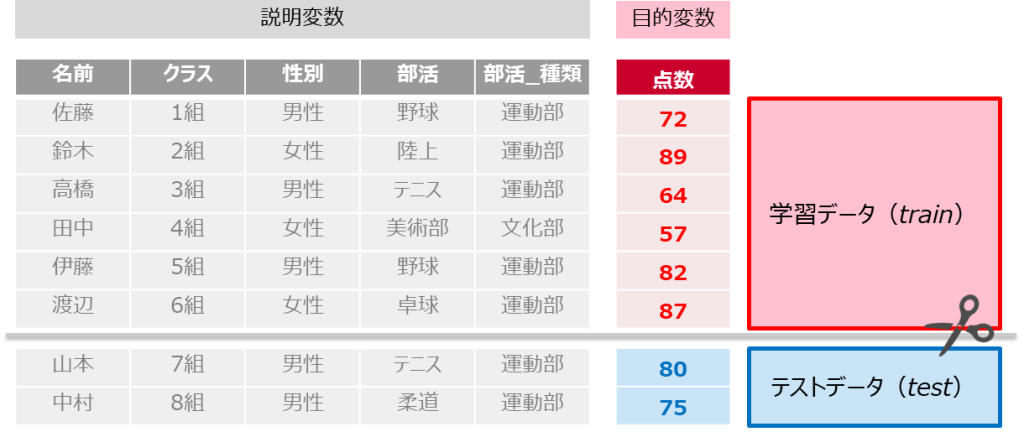
学習データ-テストデータに分割する
機械学習でモデル作成を行う際に、精度検証をする目的で学習用データ(train)とテスト用データ(test)に分割することがよくあります
今回はその中でも「hold-out法」として知られている分割の方法を、train_test_splitを使い実施してきます
事前準備
今回の主役であるtrain_test_splitをインポートしておきます
またSeabornから、タイタニック号のデータを取得しておきます
またPandas/ Numpyも合わせてインポートしておきます
from sklearn.model_selection import train_test_split
import seaborn as sns
import pandas as pd
import numpy as np
df = sns.load_dataset('titanic')
df.head()
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介します
train_test_splitの使い方
train_test_splitはNumPy配列ndarrayを2分割することができる手法です
SeriesやDataFrameも指定することができるため、機械学習の分析でスムーズに利用できます
まずは「0」からの連番を分割してみます
a = np.arange(10)
a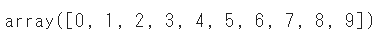
train_test_splitに先ほどの変数を代入します
train_test_split(a)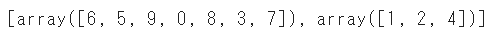
2つのデータに分割されました
変数を2つ用意して、それぞれに格納しましょう
x,y = train_test_split(a)
print(x)
print(y)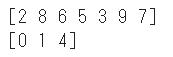
DataFrameを分割する
機械学習で利用されるDataFrameに対して学習用-テスト用にデータを分割します
説明変数(df_x)と目的変数(df_y)の2つを事前に分けておきます
df_x = df.drop('survived', axis=1)
df_y = df['survived']![df_x = df.drop('survived', axis=1)
df_y = df['survived']](https://smart-hint.com/wp-content/uploads/2022/01/image-13.png)
2つの変数を学習用-テスト用に分割します
それぞれをtrain_test_splitに代入します
train_x, test_x, train_y, test_y = train_test_split(df_x, df_y)「train_x」「test_x」「train_y」「test_y」の4つの変数に対して、分割したそれぞれが格納されます
始めのうちは混乱すると思うので、イメージを浮かべながら考えてみてください

パラメータ
パラメータを設定することで、データの区切り方を調整することができます
おすすめ度を判定:★★★=必須|★★☆=推奨|★☆☆=任意
★★★:arrays(対象のデータ)
第一引数のarraysは、NumpyのarrayやSeries、DataFrameを指定します
2つ以上の変数を指定することも可能です
※arraysは記述する必要はありません
a = np.arange(10)
train_test_split(a)★★☆:test_size(テストデータの大きさ)
テスト用のデータ量を指定することができます
まずは「0」から「1」の割合でテストサイズを指定します
train_test_split(a, test_size=0.5)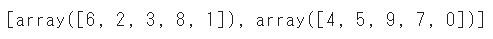
テストサイズを「個数」で指定することも可能です
train_test_split(a, test_size=2)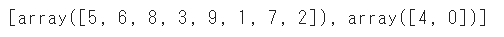
特に指定が無い場合は「0.25」となります(テストサイズが1/4=25%)
★★☆:train_size(学習データの大きさ)
test_sizeと同じ仕組みで、学習データの大きさを指定できます
※詳細は同じなので割愛します
★☆☆:shuffle(シャッフル)
shuffleを「False」に指定すると、変数の順番のまま分割します
何も指定しないと「True」となっているので、シャッフルしたくない場合のみ記述しましょう
train_test_split(a, shuffle=False)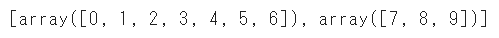
★★☆:random_state(乱数シード)
random_stateに数値を指定すると、分割するときのランダム性を固定することができます
一方で指定しない場合は、毎回ランダムで分割が実施されます
train_test_split(a, random_state=1)機械学習のモデル比較を実施する際、分割の方法が異なってしまうと正確な比較ができない場合があります
数値は何でもよいので、ぜひ設定しておきましょう
まとめ
今回はtrain_test_splitを活用して、機械学習用のデータを、学習データ-テストデータに分割する方法をご紹介してきました
使い方は非常に簡単なのでぜひ使ってみてください
機械学習のバリデーション(検証)についてはこちらの記事で説明しています
 【機械学習】バリデーション(検証)をグラフィック解説
【機械学習】バリデーション(検証)をグラフィック解説


