Smart-Hint
Smart-Hint 
目次
サンプルデータとは?
Pythonでのデータ分析練習をより円滑に進めるために、サンプルデータを使うことが多く
その中でも初心者向けのデータセットであるタイタニック号をご紹介します
Webからデータを取得する方法はこちらからご覧ください
 【Python】サンプルデータをWebから取得する方法
【Python】サンプルデータをWebから取得する方法
タイタニック号はどういうデータなのか?

今回ご紹介するタイタニック号のデータは、かの有名な「タイタニック号沈没時の乗客」に関するデータになります
年齢や旅客クラス、家族が載っているかなどの乗客に関するデータに加えて、
その乗客が「死んでしまった」か「生き残ったか」の生存情報が付与されています
このデータを処理するときの方向性としては…
乗客に関するどの情報が、生存に影響を与えたか?
例えば男性・女性のどちらが生き残りやすかったのか?
旅客クラスごとの生存率などをPythonのデータ加工によって導き出します
この結果からタイタニック号の沈没の裏側で起こっていたことを推測することができます
事前準備
Seabornというライブラリから、タイタニック号のデータを取得しておきます
import seaborn as sns
df = sns.load_dataset('titanic')
df
データ内容のご紹介
Seabornで取得できるタイタニック号のデータは15列x891行の組み合わせのデータです
15種類のカラム(列)が用意されていて、様々なデータ型が用意されています
※Kaggleというデータ分析プラットフォームにもタイタニック号のデータがあり、そちらではNameというカラムもあるので追加で説明します
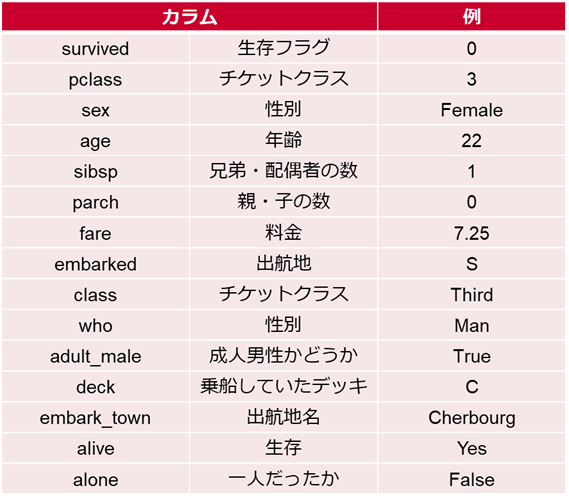
よく見ると同様の内容が別データとして入っているケースがあります
生存フラグsurvivedと生存aliveなどです
それではカラムを1つずつ説明していきます
Seabornでグラフ化して説明していきますが、グラフの作成方法はこちらの記事をご覧ください
 【Python】seabornで綺麗なグラフ作成を!たった1行で書けます
【Python】seabornで綺麗なグラフ作成を!たった1行で書けます
生存(survived / alive)
タイタニック号が沈没した際、その乗客が「死んでしまった」か「生き残ったか」を表しています
データでは survivedとaliveが該当しますが、数値型か文字列型かの違いです
死んでしまった場合が「0」で、生き残った場合が「1」となるため、平均値をとるとそれが「生存率」になります
sns.countplot(data=df, x='survived')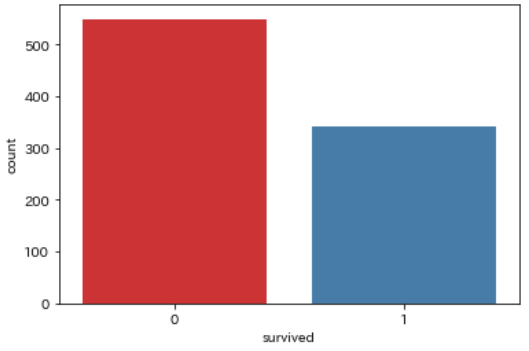
性別(sex / who)
続いて性別です
こちらも2種類sexとwhoがありますが、性別の記載方法が違うだけです
それぞれにデータ量を可視化してみます
sns.countplot(data=df, x='sex')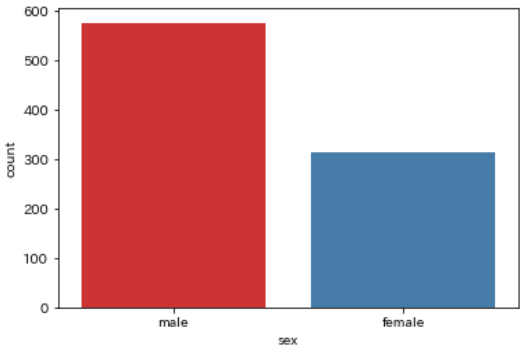
年齢(age / adult_male)
続いて年齢のデータについてご紹介します
ageはそのまま年齢を指しますが、adult_maleは成人男性であるかどうかというデータです
年齢ごとにデータ量を可視化します
sns.histplot(df, x='age')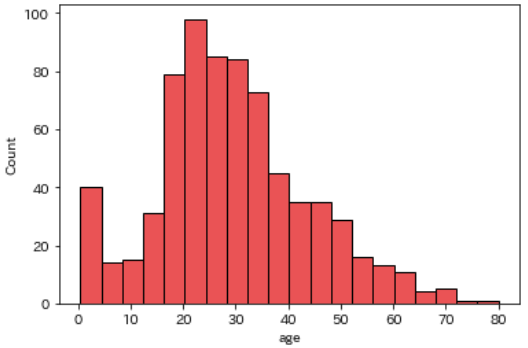
少し細かいので、四捨五入して「年代」をプロットしてみます
年齢【24】を10で割って【2.4】それを四捨五入した【2.0】後に、さらに10倍します【20】
df['ages'] = round(df['age'] / 10, 0) * 10
sns.countplot(data=df, x='ages')![df['ages'] = round(df['age'] / 10, 0) * 10
sns.countplot(data=df, x='ages')](https://smart-hint.com/wp-content/uploads/2021/10/image-7.png)
家族の数(sibsp / parch)
一緒に乗船した家族の数もデータとして存在します
sibspは兄弟・配偶者の数を表しており
parchは親・子の数を表しています
sns.countplot(data=df, x='sibsp')
sns.countplot(data=df, x='parch')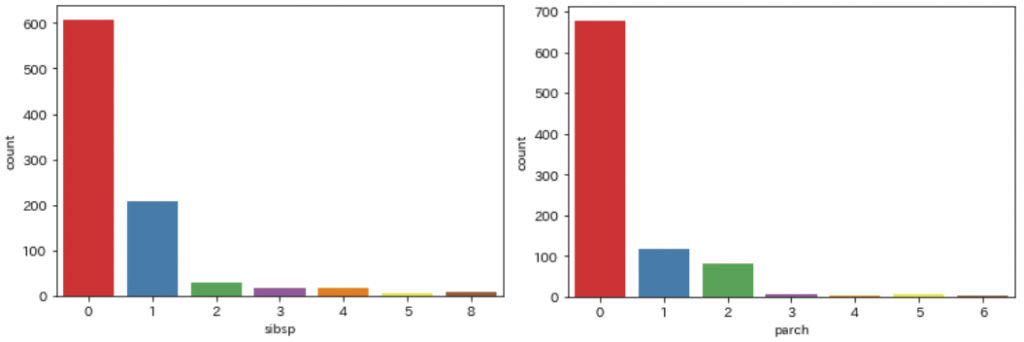
それぞれ「0」の乗客が多いのが分かります
チケットクラス(pclass / class)
続いて乗船するときのチケットクラスです
こちらは料金と比例するため、高所得者(低所得者も)を判別することができます
sns.countplot(data=df, x='class')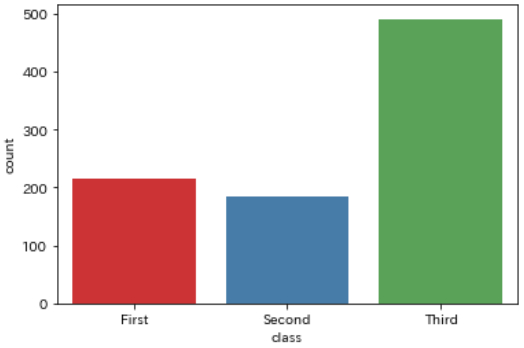
3種類のチケットクラスがあり、1=上級 2=中級 3=下級となっていて
一番下のクラスである「Third」が多数派となっています
料金(fare)
乗車する際に払う料金もデータとして存在します
sns.histplot(df, x='fare', binwidth=10)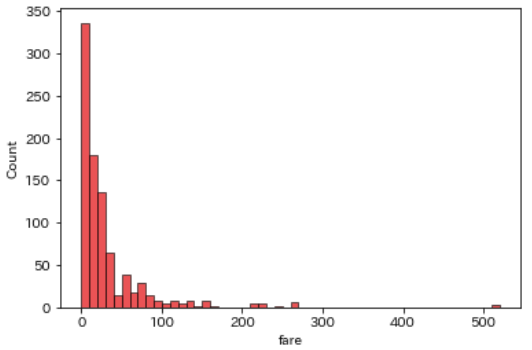
また先ほどのチケットクラスclassごとの平均料金fareを比較してみます
sns.barplot(data=df, x='class', y='fare')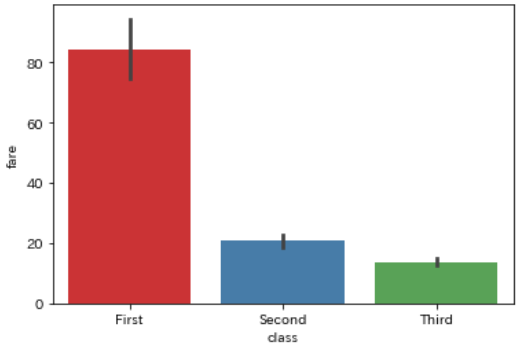
圧倒的に「First」のクラスの方が料金が高いことが分かります
出航地(embarked / embark_town)
タイタニック号に乗船したときの場所(出航地)も情報として存在します
この出航地の名前がembark_townで、その頭文字がembarkedに格納されています
出航地は3つだけで、乗客は「Southampton・Cherbourg・Queenstown」のいずれかから乗船したようです
sns.countplot(data=df, x='embark_town')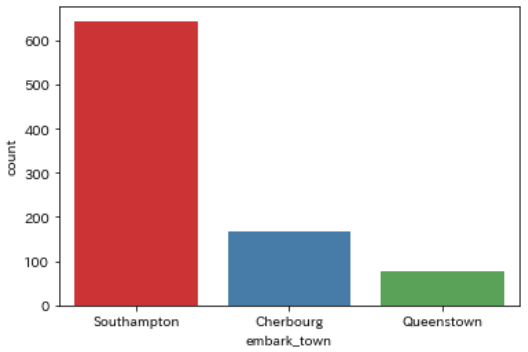
出航地としては「Southampton」が一番多いようです
乗船していたデッキ(deck)
どのデッキにいたかも情報として残っており、AからGまでのデータがあります
sns.countplot(data=df, x='deck')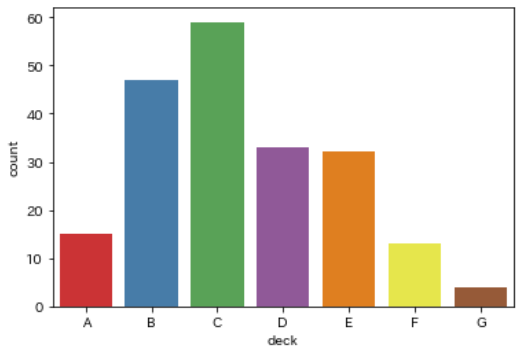
名前(Name)
ここからはseabornには掲載されておらず、Kaggleのサンプルデータで取得できる項目を説明します
Nameは乗船していた人の名前を示しています
df['Name']
名前に含まれる,カンマや.ピリオドを起点に分割し、欧米の敬称(Mr / Missなど)を取得します
df['Title'] = df['Name'].map(lambda x: x.split(', ')[1].split('. ')[0])![df['Name'].map(lambda x: x.split(', ')[1].split('. ')[0])](https://smart-hint.com/wp-content/uploads/2022/01/image-171.png)
さらに敬称から、性別や乗船員、王族・貴族をまとめます
それごとに生存率を可視化します
df['Title'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer', inplace=True)
df['Title'].replace(['Don', 'Sir', 'the Countess', 'Lady', 'Dona'], 'Royalty', inplace=True)
df['Title'].replace(['Mme', 'Ms'], 'Mrs', inplace=True)
df['Title'].replace(['Mlle'], 'Miss', inplace=True)
df['Title'].replace(['Jonkheer'], 'Master', inplace=True)
sns.barplot(x='Title', y='Survived', data=df, palette='Set2')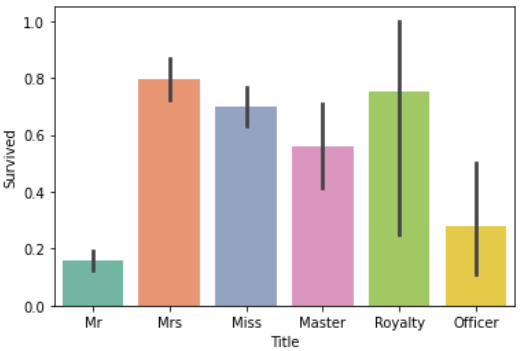
まとめ
今回はPythonでデータ分析練習をより円滑に進めるための、タイタニック号のサンプルデータをご紹介してきました
生存に関するデータで親密さはありませんが、興味の出るデータではないでしょうか
少し難しい単語も出てきますが、練習用で優れているデータセットなのでぜひ使ってみてください