

目次
データを結合するmerge関数
mergeでは2つのデータ同士を結合することができます
Excelでは「VLOOKUP」、SQLでは「JOIN」と同じ機能で、共通する項目(キー)を元に表同士を結合します
Pythonでは結合方法をパラメータで指定します
少し細かく設定する必要がありますが、それぞれ説明していきます
事前準備
Pandasというデータ解析を実施できるライブラリをインポートします
import pandas as pd※サンプルデータ:学校のテストの点数

今回はデータの結合を説明するために「テストの点数」と「部活情報」の2つのデータを利用します
テストの点数(df)
df = pd.read_html('https://smart-hint.com/student-data/')[0]
df.head()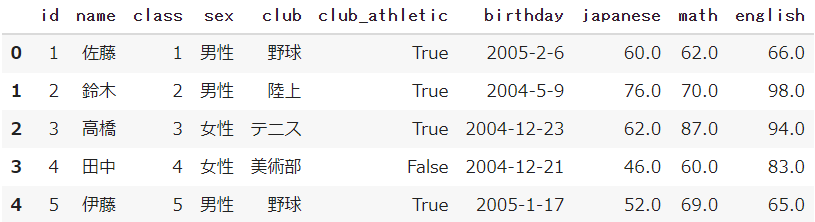
部活情報(df_club)
一部の部活の「大会出場の結果」をtournamentとしてデータを作成しています
df_club = pd.DataFrame({'club':['野球','サッカー','柔道','テニス','バレー','バスケ','卓球','吹奏楽'],
'tournament':['全国大会','全国大会','全国大会','県大会','県大会','県大会','地方大会','地方大会']})
df_club
mergeの使い方
mergeはPandasをインポートして利用します
そして事前に変数として2つのDataFrameを用意します
今回は「テストの点数:df」の部活名をキーに「部活情報:df_club」を結合します
- 左:テストの点数 df
- 右:部活情報 df_club
- キー:club
- 結合方法:LEFT(左外部結合)
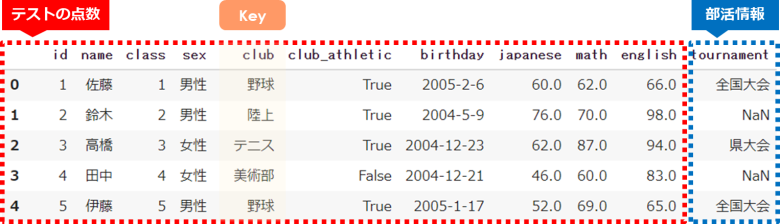
基本的な設定のステップ
まずはPandasを呼び出すためにコード前に「pd」を付けてmergeを記述します
pd.merge(mergeの中に「左の表」の変数名と「右の表」の変数名を記載します
pd.merge(df, df_club次にhowに「JOIN方法」を指定します
今回は「左外部結合」のため’left’を指定します
pd.merge(df, df_club, how='left'そして「キー」とするカラムをonで指定します
pd.merge(df, df_club, how='left', on='club')最後に「変数」として「df_new」に代入し、5件取り出してみましょう
df_new = pd.merge(df, df_club, how='left', on='club')
df_new.head()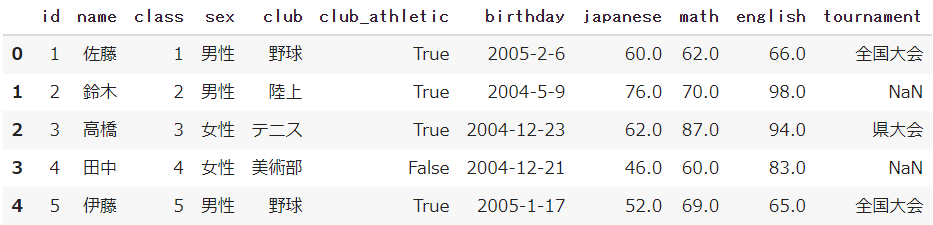
これでテストのデータに対して「部活」の情報を付けることができました
詳細設定に関してはパラメータで説明します
別の記述方法
mergeは「pd」からではなく、「左の表」を先に書く方法があります
結果はどちらも同じですが、こちらの方がスッキリ書けます
df.merge(df_club, how='left', on='club')パラメータ
おすすめ度を判定:★★★=必須|★★☆=推奨|★☆☆=任意
★★★:left / right(結合するデータ)
pd.merge(df, df_club)mergeを関数として利用する場合は、2つのデータを指定します
最初に記載した変数(left)に対して、次に記載した変数(right)を結合します
df.merge(df_club)※どちらの場合も以降のパラメータは同じなので、お好きな方をご利用ください
★★★:on(結合キー)
pd.merge(df, df_club, on='club')共通するキー名を指定します(例ではclub)
記載がない場合は、両方に存在するカラム名が自動的に共通キーとして認識されますが、
明示的に指定することをおすすめします
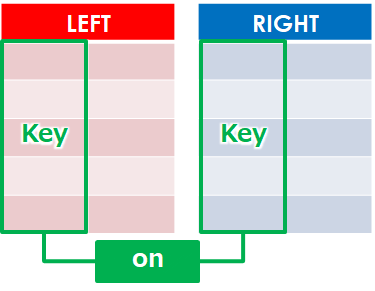
- on = ‘結合キー’
- on = [‘結合キーA’,’結合キーB’]
複数のキーを指定する場合はリストとして指定しましょう
★★★:left_on(左の結合キー)
# カラム名を変更
df_club.rename(columns={'club':'部活'}, inplace=True)
pd.merge(df, df_club, left_on='club', left_on='部活')左右で結合キーとするカラム名が違う場合は、パラメータを分けて指定します
こちらも複数のキーを指定するときはリストとして指定します
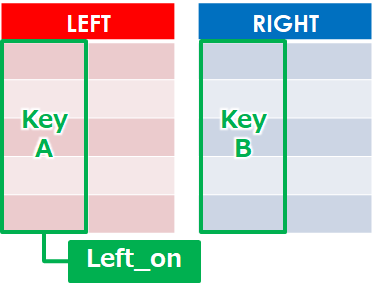
- left_on = ‘結合キー’
- left_on = [‘結合キーA’,’結合キーB’]
★★★:right_on(右の結合キー)
# カラム名を変更
df_club.rename(columns={'club':'部活'}, inplace=True)
pd.merge(df, df_club, left_on='club', left_on='部活')「left_on」に対して右側の列名を指定します
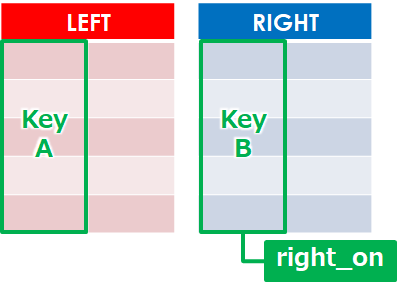
- right_on = ‘結合キー’
- right_on = [‘結合キーA’,’結合キーB’]
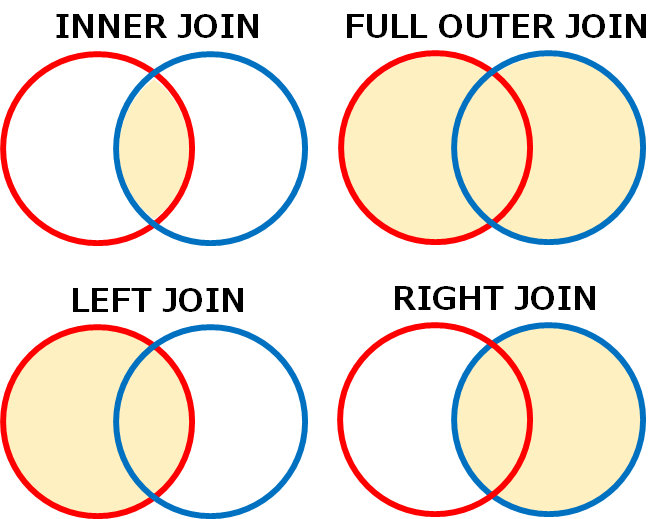
★★★:how(結合方法)
pd.merge(df, df_club, on='club', how='left')2つの表を結合する方法を指定します
指定しない場合はhow=‘inner’となり相互に共通する項目だけ残ります
データが存在しない場合は「NaN」となります
- how=‘left’(左外部結合:LEFT JOIN)
- how=‘right’(右外部結合:RIGHT JOIN)
- how=‘outer’(外部結合:OUTER JOIN)
- how=‘inner’(内部結合:INNER JOIN)※デフォルト
★★☆:indicator(元データの表示)
pd.merge(df, df_club, on='club', how='left', indicator=True)左右のデータのうち、元データではどちらに存在していたかを表示することができます
「both」「left_only」「right_only」の3パターンに分類されます
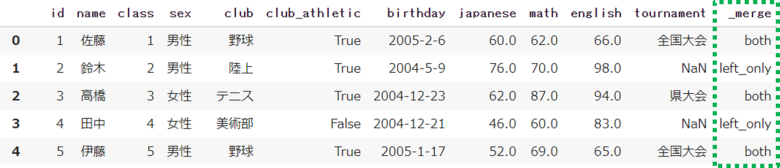
指定がない場合は元データの情報は表示されません
- indicator=False(元データを表示しない)※デフォルト
- indicator=True(元データを表示する)
- indicator=‘任意の列名’(元データを表示し、カラム名を指定する)
「True」を指定した場合の列名は「_merge」になります
列名を明示したい場合は、indicatorに列名を指定しましょう
★☆☆:suffixes(共通する列名)
mergeでは結合キーにした情報は削除されますが、両方のデータに共通するカラムは重複して残ります
ただしPythonでは同じカラム名は利用できないため、左右で共通の列名が存在している場合は、後ろに「_x」「_y」が自動的に付きます
試しにdf_club同士で結合してみましょう
pd.merge(df_club, df_club, on='club', how='left')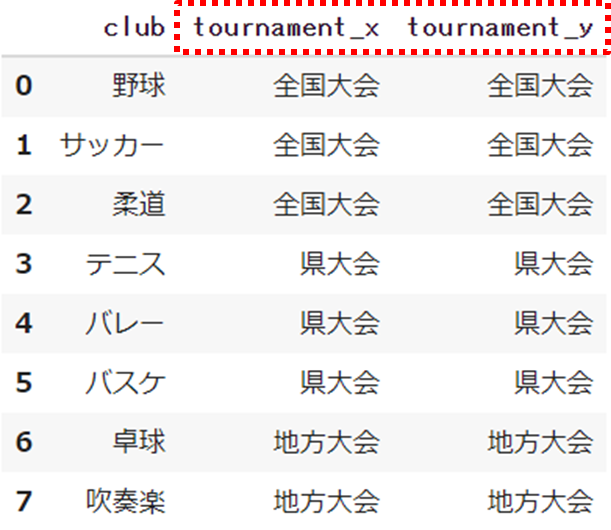
違いを明確化するためにデータ元の名前を付けることができます
suffixesに文字列を指定しましょう
pd.merge(df_club, df_club, on='club', how='left', suffixes=['_テスト','_部活'])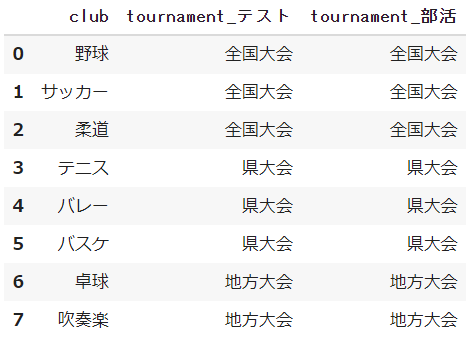
リスト型で任意の名前を指定します
- suffixes = [‘_x’, ‘_y’](共通の列名に_x/_yが付く)※デフォルト
- suffixes = [‘_left’, ‘_right’](共通の列名に_left/_rightが付く)
★☆☆:left_index / right_index(キーをインデックス)
それぞれの変数のインデックスをキーに設定したい場合は、left_indexとright_indexを指定します
set_indexを使って、clubをインデックスに指定します
df = df.set_index('club')
df_club = df_club.set_index('club')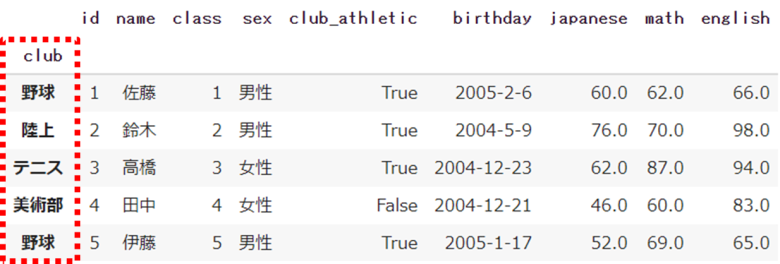
left_indexとright_indexの両方をTrueで設定します
pd.merge(df, df_club, how='left', left_index=True, right_index=True)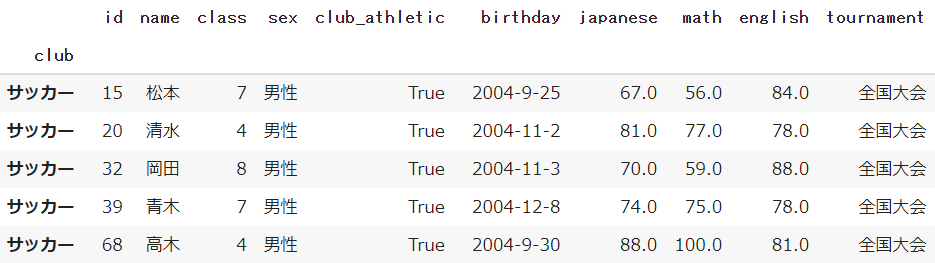
まとめ
今回はPythonのmergeについてご紹介してきました
Pythonでは複数のデータを頻繁に作り出し、結合するという作業が多く発生します
ぜひ使い方を覚えてみてください


Pythonのmergeが苦手意識があったのですが、イラスト多めで非常に分かりやすいです
一点、気になる部分がありましてご確認ください。
>★★★:left,right(結合するデータ)
こちらのコードが実行できませんでした。
コメントありがとうございます。
ご指摘いただいたコードに誤りがございました。失礼いたしました。
すで修正しておりますので、改めて実行してみてください。