Smart-Hint
Smart-Hint 
目次
列の要素の出現回数とは?
value_counts()は、DataFrameの特定の「列」に入っている「ユニークな要素」の「出現回数」を抽出することができる関数です
「ユニークな要素」とは重複が無いように集約された要素のことで、
「出現回数」とはその要素が何行あるかということです
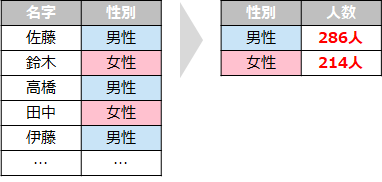
つまり特定の列を指定して「どのようなデータが、どれくらい入っているか」を把握することができるのです
※サンプルデータ:学校のテストの点数

student_data.head()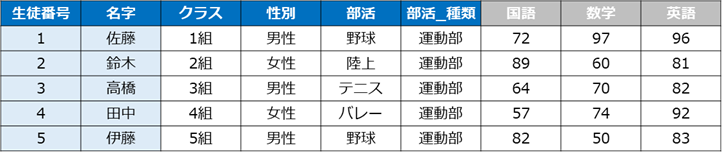
value_counts()の使い方
まずDataFrameの列を特定する必要があり、[ ]を使って列名を指定します
そしてvalue_counts()のメソッドを付けるだけです
student_data['性別'].value_counts()![school_data['性別'].value_counts()の結果](https://smart-hint.com/wp-content/uploads/2021/03/image-68.png)
ユニークな要素がindexで出現回数が値として、データが抽出されます
生徒の「部活」も同様に抽出します
student_data['部活'].value_counts()![school_data['部活'].value_counts()の結果](https://smart-hint.com/wp-content/uploads/2021/03/image-69.png)
複数の列を指定する場合
2個以上の列のユニークな要素の出現回数を調べることもできます
例えば生徒の「性別」と「クラス」それぞれの人数を数えます
複数の列を指定する場合は[[ ]]に複数の項目を指定しましょう
student_data[['クラス','性別']].value_counts()![school_data[['クラス','性別']].value_counts()の結果](https://smart-hint.com/wp-content/uploads/2021/03/image-70.png)
パラメータ
おすすめ度を判定:★★★=必須|★★☆=推奨|★☆☆=任意
★☆☆:ascending(昇順)
student_data['性別'].value_counts(ascending=False)「ascending」とは昇順(小さい順に並び替え)を意味しており、デフォルトでは「False」となっています
何も指定しないと降順(大きい順)に抽出されます
- ascending = False(降順:大きい順に並び替え)※デフォルト
- ascending = True(昇順:小さい順に並び替え)
★☆☆:normalize(出現割合)
student_data['性別'].value_counts(normalize=False)デフォルトの「False」では「出現回数」が抽出されますが、
「True」を設定することで「相対的な出現割合」が出ます
全体を「1」としたときの割合が算出されるので便利な機能です
- normalize = False(出現回数を抽出)※デフォルト
- normalize = True(出現割合を抽出)
![school_data['性別'].value_counts(normalize=False)の結果](https://smart-hint.com/wp-content/uploads/2021/03/image-72.png)
★☆☆:sort(ソート)
student_data['性別'].value_counts(sort=True)「出現回数」で並び替えを実施しない方法がこちらです
デフォルトでは出現回数が多い順に並び替えますが、「False」を選択することでソートされることなく表示されます
- sort = True(ソートあり)※デフォルト
- sort = False(ソートなし)
![school_data['性別'].value_counts(sort=True)の結果](https://smart-hint.com/wp-content/uploads/2021/03/image-71.png)
★☆☆:dropna(欠損値の扱い)
欠損値(NaN:Not a Number)を結果に出すかどうかの指定になります
デフォルトでは「NaN」は抽出されませんが、「False」を設定することで欠損値を含めて抽出することができます
- dropna = True(欠損値は含めない)※デフォルト
- dropna = False(欠損値を含める)
部活の種類として「運動部・文化部」のほかに、帰宅部を意味するデータの「欠損値」を抽出してみます
まずは「NaN」を含める場合
student_data['部活_種類'].value_counts()#欠損値を含めない![school_data['部活_種類'].value_counts()#欠損値を含めないの結果](https://smart-hint.com/wp-content/uploads/2021/03/image-74.png)
続いて「NaN」を含めない場合
student_data['部活_種類'].value_counts(dropna=False)#欠損値を含める![school_data['部活_種類'].value_counts(dropna=False)#欠損値を含めるの結果](https://smart-hint.com/wp-content/uploads/2021/03/image-73.png)
まとめ
今回はvalue_counts()関数についてご紹介してきました。
データ分析をする初手として「データの把握」をする必要がありますので、value_counts()を使って要素の出現回数を見てみましょう