
目次
ピボットテーブルでデータを加工する
Excelのピボットテーブルと同様の機能がPythonのDataFrameにも存在します
pivot_tableの機能により「クロス集計表」も簡単に作ることができます

Excelでは「ピボットテーブルのフィールド」という、視覚的にも分かりやすいボックスが存在しますが
一方でPythonでは全てパラメータで記述する必要があります
こちらの記事で集計方法をご説明します
事前準備
Pandasというデータ解析を実施できるライブラリをインポートします
import pandas as pd※サンプルデータ:学校のテストの点数

import pandas as pd
# 本サイトから直接データを取得
df = pd.read_html('https://smart-hint.com/student-data/')[0]
df.head()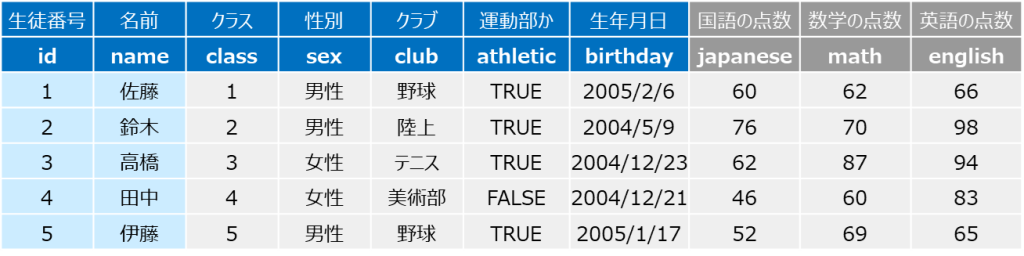
pivot_tableの使い方
pivot_tableは必須級のパラメータが複数存在します
最終的にどういうテーブルになっていればよいのかを想定して記述を始めてください
考えるべきポイントは5つ!
- 使うデータ(data)
- まとめる項目(index)
- 分割する項目(columns)
- 計算する値(values)
- 集計関数(aggfunc)
この5つのポイントはそのままパラメータとして利用します
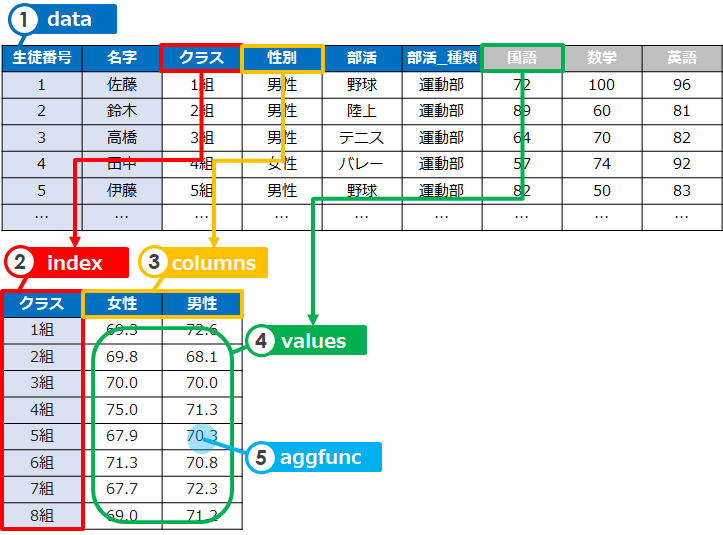
上記の図では「学校のテスト」のデータ(data)を使ってピボットテーブルを作っています
「クラス」をまとめる項目(index)として、「性別」で分割(columns)しています
「国語」の点数を値(values)として、「平均」を計算(aggfunc)しています
つまり「クラス×性別」ごとの平均点を出しています
集計方法を設定する「aggfunc」は普段使わない単語ですが
正確には「Aggregate Function」で日本語では「集計関数」という意味です
パラメータ
おすすめ度を判定:★★★=必須|★★☆=推奨|★☆☆=任意
★★★:data(対象データ)
pd.pivot_table(df)まずはdataで利用するDataFrameを指定しましょう
dataとは書いていますが、そのままDataFrameの変数名を記述します
今回はサンプルデータの変数「df」を指定しています
またメソッドとして利用することも可能です
df.pivot_table()★★★:index(まとめる項目)
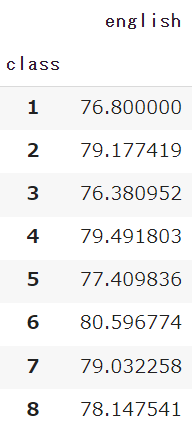
df.pivot_table(index='class', values='english')indexではピボットテーブルでまとめたい項目を指定します
今回はindexにクラス(1~8組)を指定してみます
※後述しますが、valuesに英語の点数を指定します
複数の項目でまとめる(マルチインデックス)には、元のデータの列名を[ ]リストで指定してください
例として性別と部活の種類をリストとして記述します
df.pivot_table(index=['sex','club_athletic'], values='english')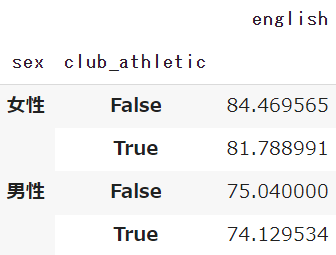
★★☆:columns(分割する項目)
df.pivot_table(index='class', columns='sex', values='english')続いて分割する項目としてcolumnsを指定します
ピボットテーブルでは列(カラム)としてアプトプットされます
クラスごとの数値を「性別」でも分けてみましょう
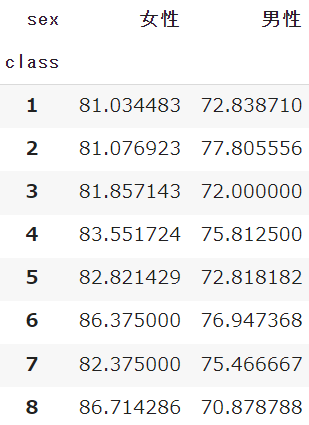
indexとcolumnsを指定することで、クロス集計表を作成することができました
こちらも元のデータの列名をリストで記述することで、マルチカラムとなります
df.pivot_table(index='class', columns=['sex','club_athletic'], values='english')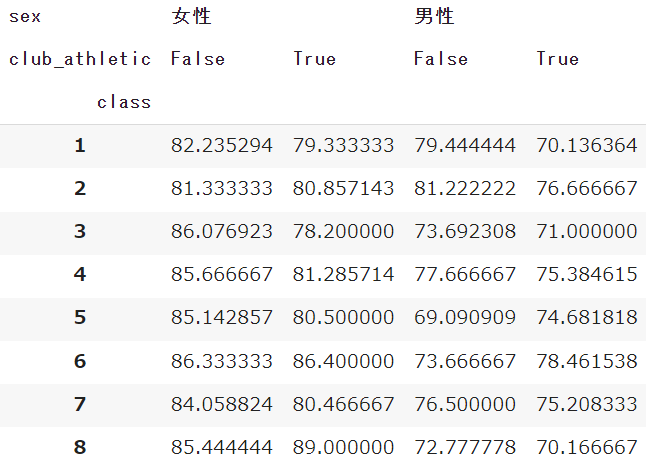
★★★:values(計算する値)
df.pivot_table(index='class', values='english')valuesではピボットテーブルで表示したい「値」を記載します
元のデータから数値型の列を抽出してください
複数の数値を指定することもできます
「国語」「数学」「英語」の3つの点数を[ ]リスト形式で値に入れてみましょう
df.pivot_table(index='class', values=['japanese','math','english'])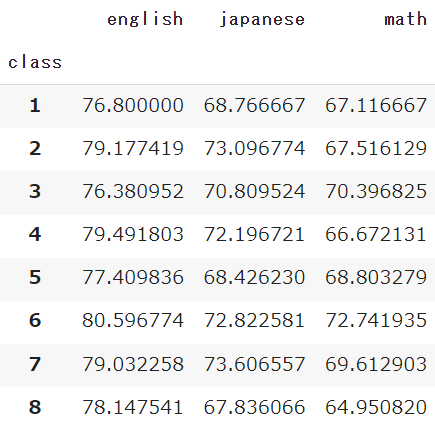
もしvaluesを記載しない場合は、数値型の情報が全て抽出されます
df.pivot_table(index='class') #valuesの記載なし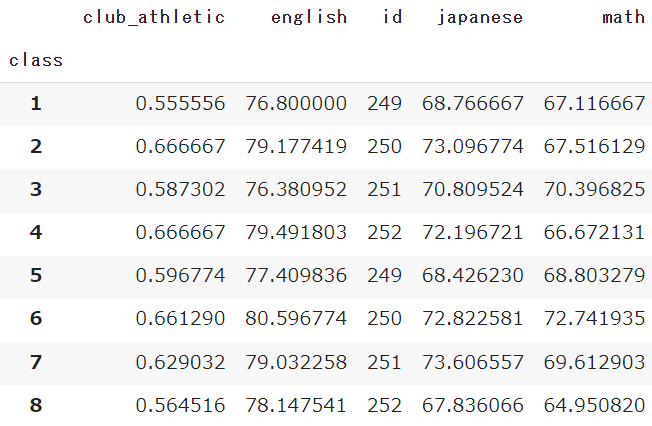
今回の例ではindexのみ「クラス」を指定しvaluesを指定していません
すると「国語」「数学」「英語」の数値型の点数に加えて、生徒番号や運動部化の有無も抽出されました
★★★:aggfunc(集計関数)
df.pivot_table(index='class', values='english', aggfunc='mean')aggfuncでは集計関数、つまり計算する方法を指定します
記載がない場合は「平均:np.mean」が採用されます
- mean:平均
- sum:合計
- max:最大値
- min:最小値
- count:件数
指定方法は「np.mean」と指定しても、「’mean’」と指定しても結果は同じです
それぞれの集計方法を抽出するには、リストで記述しましょう
df.pivot_table(index='class', values='english',
aggfunc=('min','max','mean'))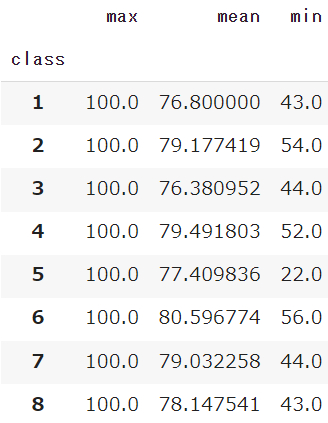
国語の点数の「最大値・平均値・最小値」を抽出してみました
★☆☆:margins(総計)
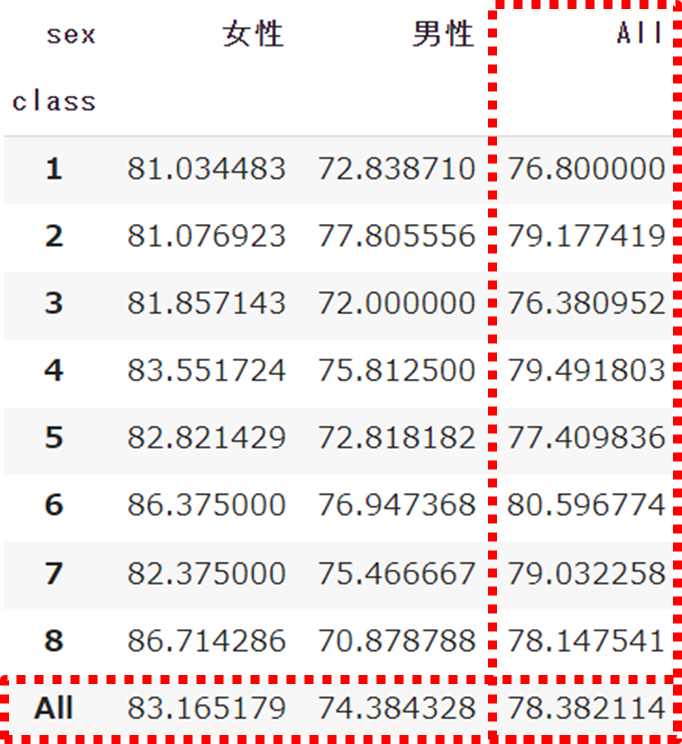
df.pivot_table(index='class', columns='sex', values='english',
margins=True)marginsをパラメータで「True」を設定することで、「総計」を表示することができます
総計といっても平均の場合は全体の平均値になります
デフォルトでは「False」で設定されており、「総計」は表示されません
★☆☆:margins_name(総計の名前)
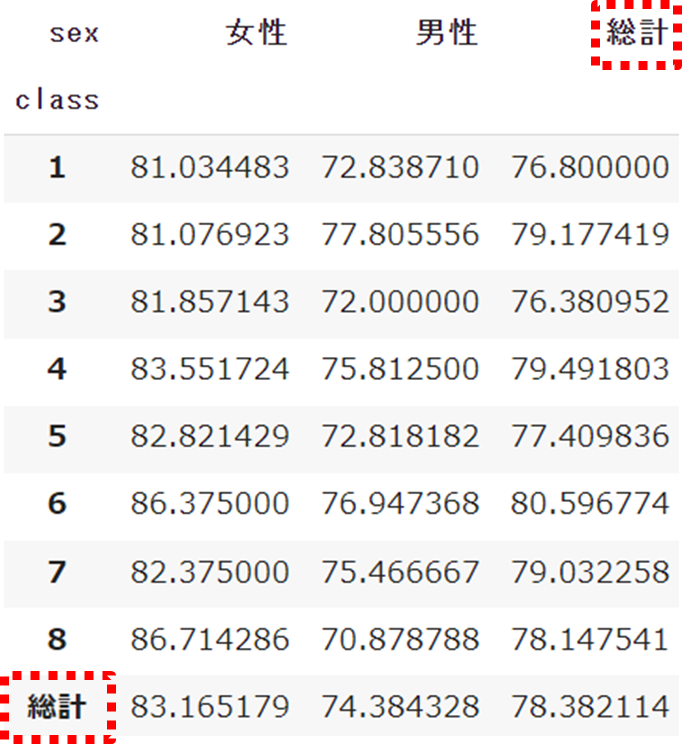
df.pivot_table(index='class', columns='sex', values='english',
margins=True, margins_name='総計')margins=Trueで設定した総計に対し、margins_nameで任意の名前を付けることができます
※インデックスを解除する方法
df.pivot_table(index=['sex','club_athletic'],
values='english').reset_index()ピボットテーブルを加工する際に「インデックス」の構造では扱いにくくなることがあります
そこでreset_indexのメソッドを利用し、インデックスを解除することができます
「0.1.2.3…」と数字の連番がインデックスとして追加されます

まとめ
今回はPythonのデータを集計する際によく使うpivot_tableをご紹介してきました
基本的な使い方を覚えてしまえば、Pythonのデータ加工が非常に楽になります
ぜひ覚えて使ってみてください


