Smart-Hint
Smart-Hint 
目次
データを並び替える
DataFrameに格納したデータを「並び替える」方法をご紹介します
sort_valuesを使うことで自由自在にデータを並び替えることができます
また単純に並び替えるだけではなく、昇順・降順や上書きなど
詳細を設定することも可能です
事前準備
「Pandas」というデータ解析を実施できるライブラリをインポートします
import pandas as pd※サンプルデータ:学校のテストの点数

student.head()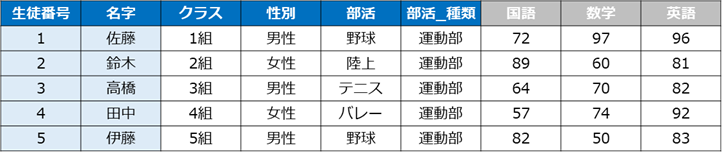
sort_valuesの使い方
sort_values()は関数としてパラメータを指定して利用します
DataFrameの変数に続けて記述しましょう
サンプルとして「国語の点数」を点数の高い順(降順)で並び替えます
student.sort_values('国語', ascending=False)
「100点」が1人いることが分かりました
ここからはsort_values()のパラメータをそれぞれご紹介します
パラメータ
おすすめ度を判定:★★★=必須|★★☆=推奨|★☆☆=任意
★★★:by(並び替える列)
student.sort_values('国語', ascending=False)並び替えたい列名を必ず指定する必要があります
パラメータをbyとしていますが、「列名」をそのまま記述してください
例として「列名:クラス」を1組から並び替えてみます(昇順)
student.sort_values('クラス')
★★★:ascending(昇順・降順)
student.sort_values('国語', ascending=False)ascendingとは英語で「昇順:小さい順」という意味です
記載がない場合(デフォルト)は「ascending = False」となり、昇順で並び替えられます
- ascending = True(昇順:小さい順)※デフォルト
- ascending = False(降順:大きい順)
※複数列で並び替える場合
複数の列で並び替える場合は、列名を[ ]リストで指定してください
またascendingも[ ]リストの中で「True・False」を記述します
例えばクラスは「1組~8組」の順で、国語の点数は「100点~0点」の順で並び替えます
student.sort_values(['クラス','国語'], ascending=[True,False])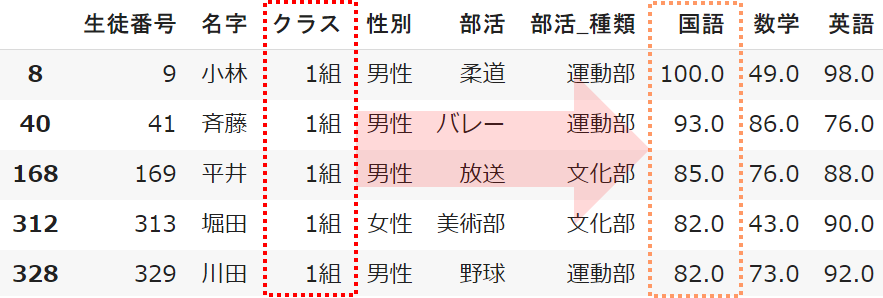
[ ]リストの書き順は、並び替える「優先順位」を意識しましょう
最初に記述した「クラス」を並び替えた後に、「国語」の点数で並び替えるイメージです
★★☆:inplace(上書き)
student.sort_values('国語', ascending=False, inplace=True)inplaceを「True」と設定することで、並び替えた内容で上書きすることができます
入れ替えた状態のDataFrameを利用する際に便利なパラメータです
- inplace = True(上書きあり)
- inplace = False(上書きなし)※デフォルト
★☆☆:na_position(欠損値の位置)
student.sort_values('国語', na_position='first')欠損値が存在する場合の並び替えの処理をna_positionで指定することができます
デフォルトでは欠損値は下に位置しますが、設定で上部に並び替えることも可能です
- na_position = ‘first’(欠損値が上)
- na_position = ‘last’(欠損値が下)※デフォルト
他の関数と組み合わせる
単純に並び替えるだけではなく、他の関数と組み合わせて利用することが多いです
実際のデータ分析でよく利用されるpivot_tableを使ってみましょう
クラスごとの英語の平均点を集計し、点数の高い順に並び替えています
student.pivot_table(index='クラス',
values='英語').sort_values('英語', ascending=False)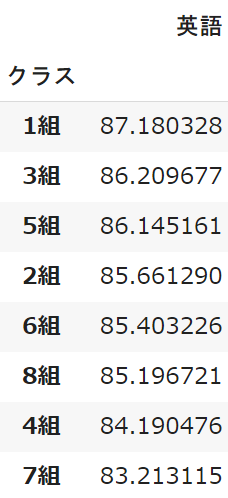
ピボットテーブルの使い方でご説明しています
 【Python】Pythonピボットテーブルを完全攻略|pivot_table
【Python】Pythonピボットテーブルを完全攻略|pivot_table
まとめ
今回はデータを「並び替える」方法をご紹介してきました
非常に簡単な関数で、利用頻度も高いのでぜひ覚えて使ってみてください