 Smart-Hint
Smart-Hint 
目次
パラメータの調整とは
今回は機械学習のモデルにおけるパラメータの調整についてご紹介していきます
パラメータとは機械学習におけるモデルの「設定」と捉えてください
※ハイパーパラメータと呼ばれています
同じモデルでもこのパラメータ(設定)を変えることによって、結果が変化します
このパラメータの中から一番精度が高くなる組み合わせを見つけることが、パラメータの調整の目的になります
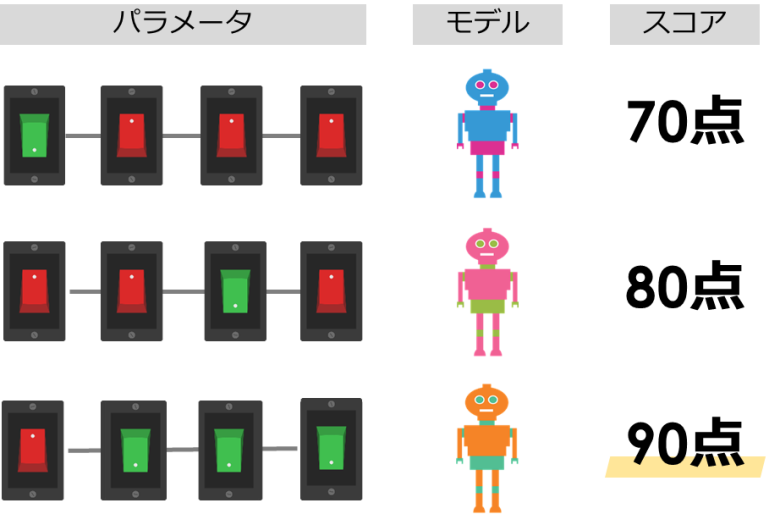
例えば「ランダムフォレスト」モデルにおいて、重要なパラメータとなる下記3つを調整するとします
それぞれに設定するパラメータ値を事前にいくつか用意します
- n_estimators : 10, 20, 30, 50
- max_depth : 10, 20, 30, 40
- min_samples_leaf : 1, 2, 4
「4」x「4」x「3」の「48通り」の組み合わせが考えられ、どの組み合わせが良いかを探します
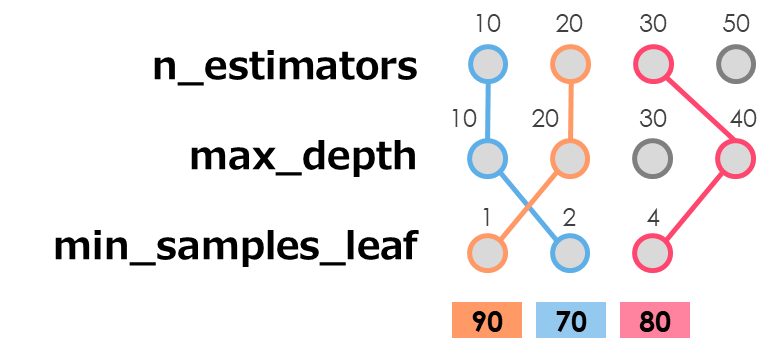
全てのパターンを試し、最も精度の高い組み合わせを見つける方法を「グリッドサーチ」と呼びます
それではPythonを使って、グリッドサーチを行う方法についてご紹介します
パラメータの調整の注意点
① 終盤の調整としてパラメータ調整を行う
モデルのパラメータ調整は、序盤から根詰めて行うのは適切ではありません
データによりますがパラメータチューニングより、良い特徴量を追加する方が精度改善につながることが多いためです
最後の悪あがきとして筆者はパラメータ調整を行っています
② ベースラインとなるパラメータを設定する
始めからパラメータ調整を行う前に、ベースラインとなるパラメータ値を設定しましょう
また各モデルには過去の実績から適切なパラメータ値が存在しています
そこから探索的にグリッドサーチを行い、最適な値を探していきましょう

③ 重要なパラメータのみ調整する
機械学習モデルには無数のパラメータが存在しています
一方で「重要なパラメータ」と「重要ではないパラメータ」が存在しており、重要なものだけ調整することで時間短縮を行うことができます
④ パラメータの中身を知っておく
モデルの精度向上のために、パラメータの中身(意味)をある程度は知っておきましょう
特にパラメータ値を上げたときに複雑化するのか、単純化していくのかは理解しておくと良いです
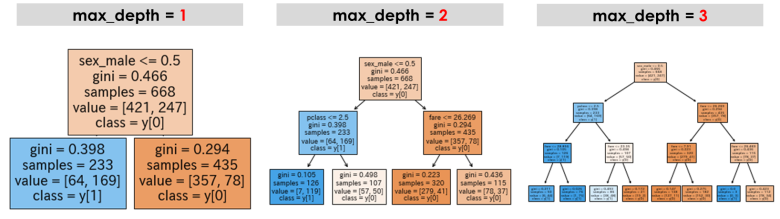
例えば「決定木系のモデル」におけるmax_depthは「葉」の深さを設定するパラメータです
「ランダムフォレスト」や「XGBoost」でも重要な役割を果たしますが、値を上げれば複雑化していく典型的なパラメータです
事前準備
Seabornから、タイタニック号のデータを取得しておきます
またPandasも合わせてインポートしておきます
import seaborn as sns
import pandas as pd
df = sns.load_dataset('titanic')
df.head()
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介します
ランダムフォレストの前処理
パラメータの調整(グリッドサーチ)の説明を「ランダムフォレスト」の分類学習を例にご説明します
コードを下記に記述するので、モデル作成前まで実行してください
# 事前準備
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# タイタニック号のデータ読み取り
df = sns.load_dataset('titanic')
# 欠損値の確認
df.isnull().sum()
# 年齢のみ欠損値の処理
age_mean = df['age'].mean()
df['age'] = df['age'].fillna(age_mean)
# 目的変数と説明変数の分割
df_x = df.drop(['survived','alive'], axis=1)
df_y = df['survived']
# 目的変数のダミー変数化
df_x = pd.get_dummies(df_x)
# 学習用-テスト用のデータに分割
train_x, test_x, train_y, test_y = train_test_split(df_x,df_y,random_state=1)グリッドサーチの実施
前処理まで実施したタイタニック号のデータを用いて、ランダムフォレストのモデル作成を行います
このモデル作成の際の最適なパラメータ求めるために、グリッドサーチを使います
パラメータ設定なしで実行
まずは基準値としてパラメータ設定なしでモデル作成してみます
random_state乱数シードは揃えておきます
# ランダムフォレストモデルの作成
model = RandomForestClassifier(random_state=1)
model.fit(train_x,train_y)
# ランダムフォレストモデルのスコア
print(model.score(test_x,test_y))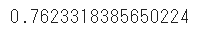
グリッドサーチで最適パラメータを探す
パラメータと検証する範囲を事前に設定しておきます
params = {
'n_estimators': [10, 20, 30, 50, 100, 300], # 決定木の数
'max_features': ['sqrt', 'log2','auto', None], # 利用する特徴量
'max_depth': [10, 20, 30, 40, 50, None], # 決定木の深さ
'random_state': [1]
}パラメータなしでモデルを作成し、GridSearchCVに対してモデルやパラメータ、評価指標を設定します
そしてfitで学習を行います
model = RandomForestClassifier()
gridsearch = GridSearchCV(estimator = model, # モデル
param_grid = params, # チューニングするパラメータ
scoring = 'accuracy' # スコアリング
)
gridsearch.fit(train_x,train_y)best_params_はグリッドサーチの最適な結果を出したパラメータを可視化することができます
best_score_は最適なパラメータでの訓練データにおけるスコアを算出します
print('Best params: {}'.format(gridsearch.best_params_))
print('Best score: {}'.format(gridsearch.best_score_))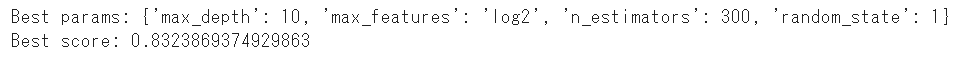
最適なパラメータでモデルを作成する
上記までのコードは最適なパラメータを探すだけだったので、ここから実際にモデルを作成していきます
best_params_でパラメータを指定しましょう
# モデルの作成
model = RandomForestClassifier(n_estimators = gridsearch.best_params_['n_estimators'], # 用意する決定木モデルの数
max_features = gridsearch.best_params_['max_features'], # ランダムに指定する特徴量の数
max_depth = gridsearch.best_params_['max_depth'], # 決定木のノード深さの制限値 # 1ノードの深さの最小値
random_state = 1, # 乱数シード
)
model.fit(train_x,train_y)
# モデルのスコア
print(model.score(test_x,test_y))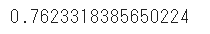
何も設定しない場合と比較し、若干スコアが向上しました
経過時間を算出する
グリッドサーチは全てのパラメータのパターンを試すので、実行に時間がかかってしまいます
time.time()は現在時刻の秒単位のタイムスタンプを取得できるため、startとendの2期間の差を取ることで経過時間を算出することができます
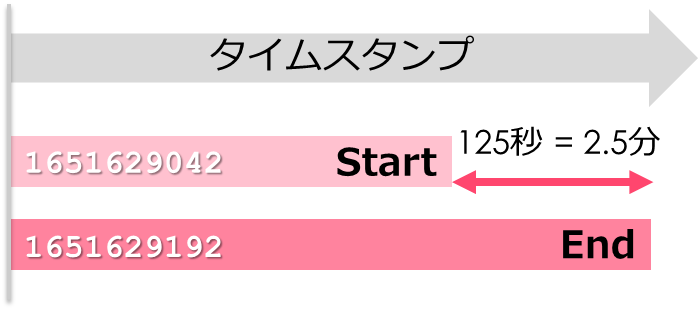
import time
start = time.time()
###############
# ここにグリッドサーチを入れる
###############
end = time.time()
print((end - start) / 60) #分Pythonのコードは上から実行されるため、グリッドサーチ前にstartに実行前の時間を代入します
そしてグリッドサーチが終わった後にendに時間を代入し、差分を算出しましょう
from sklearn.model_selection import GridSearchCV
import time
start = time.time()
params = {
'n_estimators': [10, 20, 30, 50, 100, 300], # 決定木の数
'max_features': ['sqrt', 'log2','auto', None], # 利用する特徴量
'max_depth': [10, 20, 30, 40, 50, None], # 決定木の深さ
'random_state': [1]
}
model = RandomForestClassifier()
gridsearch = GridSearchCV(estimator = model, # モデル
param_grid = params, # チューニングするハイパーパラメータ
scoring = 'accuracy' # スコアリング
)
gridsearch.fit(train_x,train_y)
print('Best params: {}'.format(gridsearch.best_params_))
print('Best score: {}'.format(gridsearch.best_score_))
end = time.time()
print('稼働時間(分):',(end - start) / 60) #分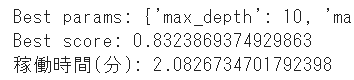
今回のグリッドサーチでは約2分ほど実行に時間がかかっていることが分かりました
まとめ
今回はPython機械学習のモデルにおけるパラメータの調整についてご紹介してきました
指定の範囲のパラメータに対して全て試し、最適なパラメータを見つけることができるグリッドサーチを説明しました
注意点で書いた通り、パラメータ調整で劇的に結果が変わることは滅多にありません
最後の調整としてぜひ試してみてください
# 事前準備
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
import time
# タイタニック号のデータ読み取り
df = sns.load_dataset('titanic')
# 欠損値の確認
df.isnull().sum()
# 年齢のみ欠損値の処理
age_mean = df['age'].mean()
df['age'] = df['age'].fillna(age_mean)
# 目的変数と説明変数の分割
df_x = df.drop(['survived','alive'], axis=1)
df_y = df['survived']
# 目的変数のダミー変数化
df_x = pd.get_dummies(df_x)
# 学習用-テスト用のデータに分割
train_x, test_x, train_y, test_y = train_test_split(df_x,df_y,random_state=1)
# グリッドサーチ開始時間を記録
start = time.time()
# パラメータの範囲を指定
params = {
'n_estimators': [10, 20, 30, 50, 100, 300], # 決定木の数
'max_features': ['sqrt', 'log2','auto', None], # 利用する特徴量
'max_depth': [10, 20, 30, 40, 50, None], # 決定木の深さ
'random_state': [1]
}
# グリッドサーチの実施
model = RandomForestClassifier()
gridsearch = GridSearchCV(estimator = model, # モデル
param_grid = params, # チューニングするハイパーパラメータ
scoring = 'accuracy' # スコアリング
)
gridsearch.fit(train_x,train_y)
# グリッドサーチの結果のアプトプット
print('Best params: {}'.format(gridsearch.best_params_))
print('Best score: {}'.format(gridsearch.best_score_))
# グリッドサーチの終了時間を記録し、差分をアプトプット
end = time.time()
print('稼働時間(分):',(end - start) / 60) #分


お素晴らしい