 Smart-Hint
Smart-Hint 
目次
欠損値(NaN)とは?
欠損値とは文字通り「欠損している値」のこと、つまりデータが入っていないことを表しています
NaNとは「Not a Number」のことです
欠損値はデータ分析の結果に大きく影響を与えるため、NaNの処理は非常に重要になってきます
AI(機械学習)が読み込めない場合もあるため、処理方法を覚えましょう
欠損値の処理方針は大きく2つあります
- 欠損値を把握する
- 欠損値を取り除く・置換する
それぞれについて詳しくご紹介していきます
事前準備
「Pandas」というデータ解析を実施できるライブラリをインポートします
import pandas as pd※サンプルデータ:学校のテストの点数

student.head()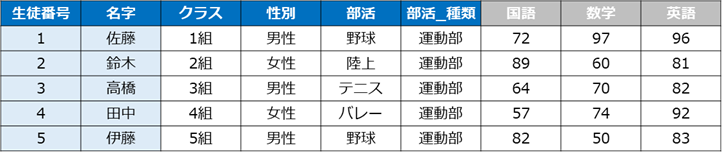
①欠損値を把握する
データを読み込むとき、必ず欠損値がないかチェックする癖を付けてください
様々な要素でデータの欠損が発生してしまいます
info
info()メソッドを使うことで「non-null:欠損していない」数が分かります
student.info()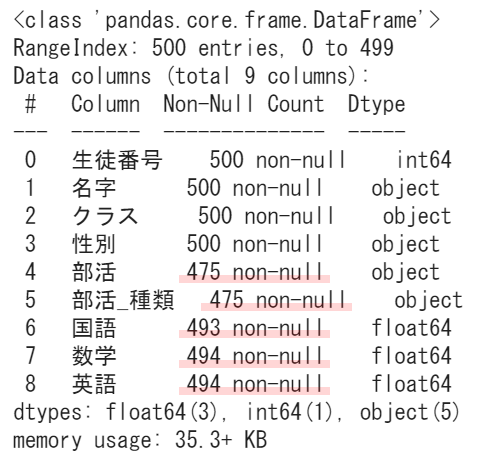
info()の詳細はこちらでご説明しています
 【Python】info|データの要約を確認する方法
【Python】info|データの要約を確認する方法
isnull
isnull()メソッドを使うことでも、欠損値を見つけることができます
アウトプットはTrueで欠損あり・Falseで欠損なしとなります
student.isnull()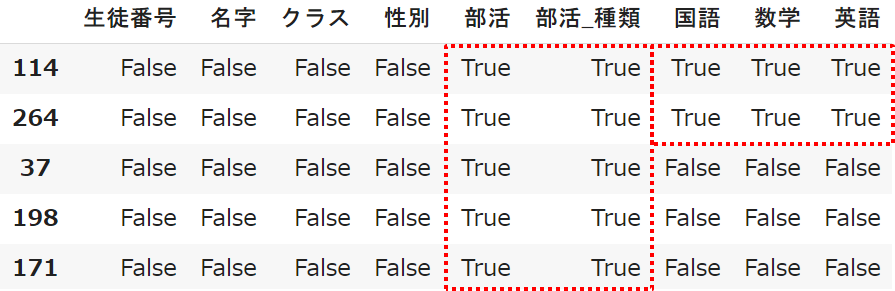
isnull()だけではTrue・Falseが出るbool値となり、非常に分かりにくくなってしまいます
そこでsum()メソッドを組み合わせて使ってみましょう
student.isnull().sum()
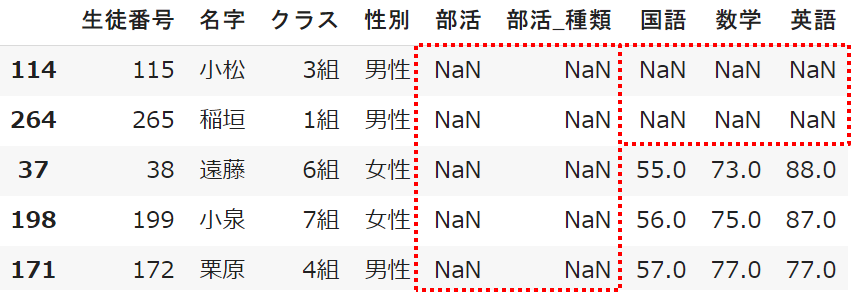
列ごとに欠損値の「True」がいくつあるかを数えることで、欠損値の数を把握することができます
サンプルデータでは「部活」や「英国数のテスト」が欠損していることが分かりました
②欠損値を取り除く・置換する
欠損している部分が判明すれば、次に考える事はその欠損値をどう扱うかになります
そしてここでも方針が2つに分かれます
- 欠損値を取り除く
- 欠損値を別の値で置換する
欠けているデータを無いことにして消してしまい、データがある行だけで分析を進める方法と
平均などの数で代替してしまう方法です
それぞれ似たような関数が用意されているため、ご紹介します
dropna(欠損値を取り除く)
dropna()はその名の通り、欠損値をdrop(落とす)処理をします
student.dropna()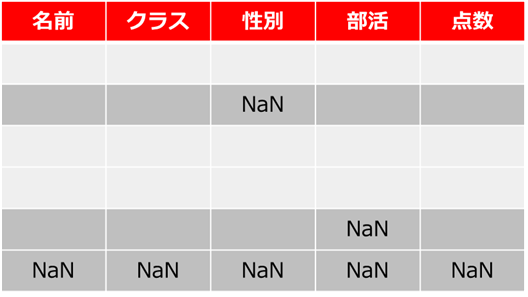
図のように「NaN:欠損値」が入っている行は削除されます
つまり全てのデータがそろっている行だけに絞るイメージです
dropna()は欠損値を簡単に処理することができます
続いて特定の列の欠損値を削除するときはsubsetを使います
[ ]リストを使い、列名を指定しましょう
student.dropna(subset=['名前'])![student.dropna(subset=['名前'])](https://smart-hint.com/wp-content/uploads/2021/05/image-14.png)
性別や部活にある「NaN」は削除されません
特定の列のみに存在する欠損値のみ取り除くことができます
欠損値を取り除くdropna()ですが、本当に取り除いてしまってよいのでしょうか?
欠損しているのがランダムなデータであれば、残ったデータだけで分析が可能です
しかし欠損しているのは何かしらの理由があるはずで、それを取り除いてしまうと
分析に大きく影響を及ぼしてしまうことを念頭に置いておきましょう
fillna(欠損値を置換する)
fillna()は欠損している値を別の値で置き換える処理ができます
例として欠損値を「0」で置き換えます
student.fillna(0)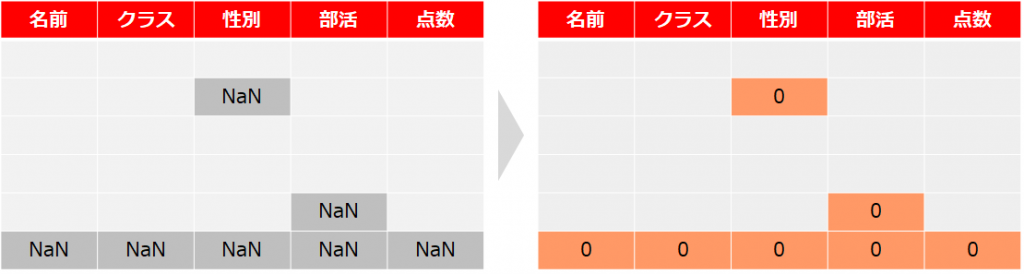
()カッコの中に置換したい値を指定することで、欠損値を入れ替えることができます
列を指定して置換することもできるので、それぞれの列に適した置き換えを実施します
student['部活'].fillna('帰宅部') #帰宅部に置き換え基本的には欠損した値は、他データの似たような値で置き換えます
代表的なものとしては下記3つです
- mean:平均値
- median:中央値
- mode:最頻値
student['国語'].fillna(student['国語'].mean()) #平均値
student['国語'].fillna(student['国語'].median()) #中央値
student['国語'].fillna(student['国語'].mode()) #最頻値少々複雑ですが、fillna()の中に列の平均を求める式student[‘国語’].mean()を入れています
統計的な代表値についてはこちらの記事をご覧ください
 【完全解説】平均値・中央値・最頻値を図を用いて説明します
【完全解説】平均値・中央値・最頻値を図を用いて説明します
特定の列ごとにデータを置換するには、{ }辞書型で「対象の列」と「置換後の数値」を記述します
student.fillna({'部活':'帰宅部','点数':0})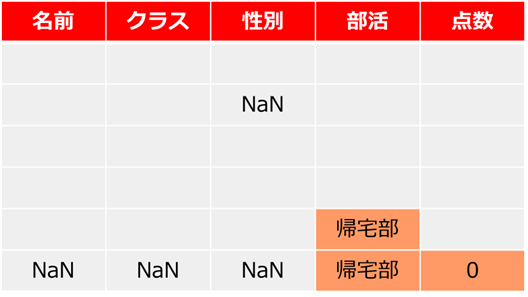
データの中身を上書き
dropna()メソッドとfillna()メソッドはinplaceというパラメータがあり
inplaceを「True」を設定することで、欠損値処理した形でデータを更新することができます
student.fillna(0, inplace=True)※同じ変数に格納するのと同様の機能です
student = student.fillna(0) #上と同じ結果にまとめ
今回は欠損値の扱いについてご紹介してきました
- 欠損値を把握する
- 欠損値を取り除く・置換する
この2つの処理方針をしっかり実施し、上手に欠損値を取り扱ってみてください
ご不明点がございましたらコメントお願いします


