Smart-Hint
Smart-Hint 
目次
PythonでGoogleトレンドの検索数を取得する
GoogleトレンドではCSV形式でデータをダウンロードすることができますが、
APIの機能を使うことによってPythonから直接データを取得することができます
Pythonで検索データを取得することのポイントは3つ
- 分析環境がPythonの場合に、データ取得から加工まで一気通貫で行える
- 大量の検索キーワードの検索数を一括で抽出できる
- 機械学習に検索データを利用することができる
事前準備(pytrendsへ接続)
初回のみpytrendsをインストールします
!pip install pytrendsそしてTrendReqをインポートし、「pytrends」という変数に対し地域と時間を設定し実行します
※hl=’ja-JP’は日本の地域を指定し、tz=-540は時差を設定しています
from pytrends.request import TrendReq
pytrends = TrendReq(hl='ja-JP', tz=-540)続いてキーワードをkw_listとして設定します(変数名は任意)
今回は「ソフトバンク」で設定してみます(6キーワード以上はエラーになります)
kw_list = ['ソフトバンク']最後に「キーワード」「期間」「地域」を指定します
pytrends.build_payload(kw_list=kw_list,
timeframe='2019-01-01 2021-06-30',
geo='JP')- kw_listには上記で設定した変数(kw_list)を指定します(ここではソフトバンク)
- timeframeには推移の期間を指定します
- geoには基本的にJP(日本)を指定しましょう
事前準備はこれで完了です
Googleトレンドでは「検索数の推移」や「地域別の検索数」に加えて、「関連キーワード」なども抽出することができますが、ここまでの事前準備は同じです
「キーワード」や「期間」を変更したい場合は、上記2つ戻って変更します
Pythonでの設定方法
ここからは取得できる項目別に設定方法をご紹介します
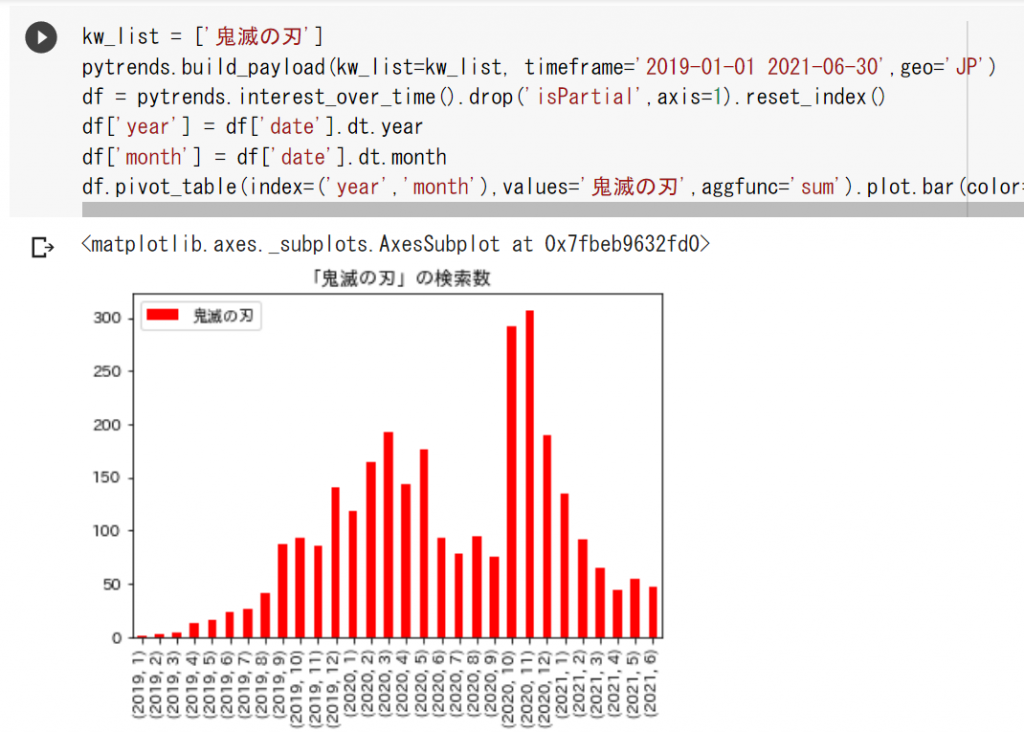
① 検索数の推移(interest_over_time)
検索数を各日付ごとに取得することができ、「検索の推移」を分析することができる機能です
事前準備で設定した「pytrends」にinterest_over_timeを使い検索数の推移を取得します
pytrends.interest_over_time()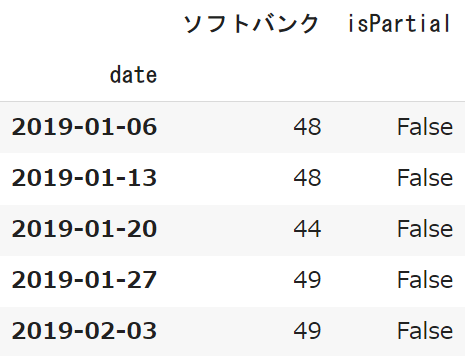
検索数の推移を取得することができました
pytrends.interest_over_time().drop('isPartial',axis=1)「isPartial」というカラムが出てしまうため、drop()を重ねて利用しましょう
!pip install pytrends
from pytrends.request import TrendReq
pytrends = TrendReq(hl='ja-JP', tz=-540)
kw_list = ['ソフトバンク']
pytrends.build_payload(kw_list=kw_list, timeframe='2019-01-01 2021-06-30', geo='JP')
df = pytrends.interest_over_time().drop('isPartial',axis=1)② 都道府県別の検索数(interest_by_region)
続いてエリア別の検索数を取得します
事前準備で設定した「pytrends」にinterest_by_regionを使い「エリア」ごとの検索数を取得します
resolutionをCOUNTRYに指定し、inc_geo_code=Trueとして都道府県コードも合わせて取得します
pytrends.interest_by_region(resolution='COUNTRY',
inc_geo_code=True)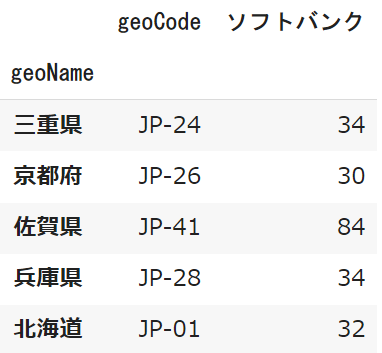
コードを取得することで「北海道→沖縄」という順番で並び替えることができます
pytrends.interest_by_region(resolution='COUNTRY',
inc_geo_code=True).sort_values('geoCode')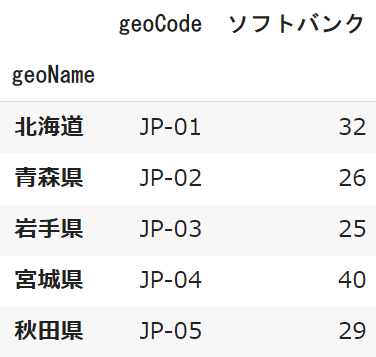
!pip install pytrends
from pytrends.request import TrendReq
pytrends = TrendReq(hl='ja-JP', tz=-540)
kw_list = ['ソフトバンク']
pytrends.build_payload(kw_list=kw_list, timeframe='2019-01-01 2021-06-30', geo='JP')
df = pytrends.interest_by_region(resolution='COUNTRY',inc_geo_code=True).sort_values('geoCode')③ 関連キーワード(related_queries)
設定したキーワードに「関連」するキーワードを取得することができます
ユーザーが他に興味あるものや、検索した理由を知ることができます
事前準備で設定した「pytrends」にrelated_queriesを設定します
queries = pytrends.related_queries()関連キーワードは「上昇」と「トップ」の2パターン取得することができ、辞書型で格納されます
それぞれをDataFrameに変更するために追加でコードを記述します
queries[kw_list[0]]['rising']
queries[kw_list[0]]['top']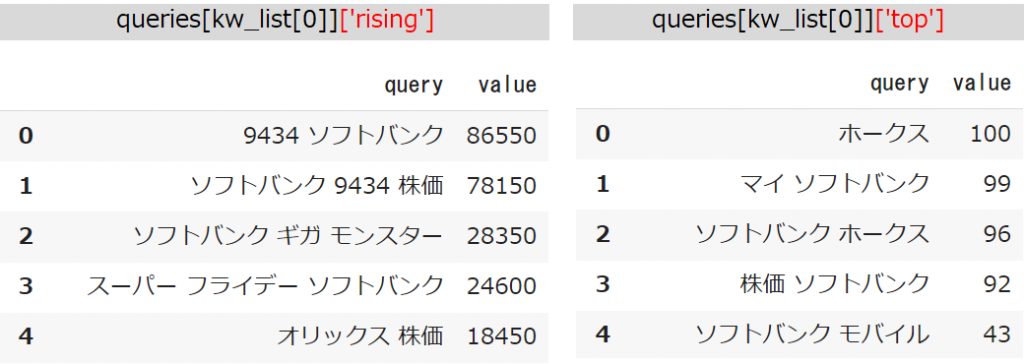
「Top」の方を見てみると「ソフトバンク」の検索には「野球チーム」と「携帯キャリア会社」の2つの検索意図があることが分かります
!pip install pytrends
from pytrends.request import TrendReq
pytrends = TrendReq(hl='ja-JP', tz=-540)
kw_list = ['ソフトバンク']
pytrends.build_payload(kw_list=kw_list, timeframe='2019-01-01 2021-06-30', geo='JP')
queries = pytrends.related_queries()
queries[kw_list[0]]['rising']
queries[kw_list[0]]['top'].head()④ 関連トピックス(related_topics)
関連キーワードと似たような機能で「関連トピックス」があります
related_topicsを利用することで、キーワードよりも抽象的なカテゴリーを取得することができます
topics = pytrends.related_topics()そしてこちらも「上昇」と「トップ」の2パターンが辞書型で格納されるため、それぞれ抽出します
topics[kw_list[0]]['rising']
topics[kw_list[0]]['top']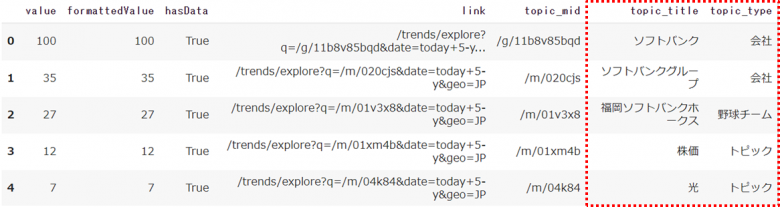
!pip install pytrends
from pytrends.request import TrendReq
pytrends = TrendReq(hl='ja-JP', tz=-540)
kw_list = ['ソフトバンク']
pytrends.build_payload(kw_list=kw_list, timeframe='2019-01-01 2021-06-30', geo='JP')
topics = pytrends.related_topics()
topics[kw_list[0]]['rising']
topics[kw_list[0]]['top']⑤ 急上昇キーワード(trending_searches)
急上昇キーワードもGoogleトレンドからPythonで取得することができます
事前準備で設定した「キーワード」や「期間」と関係なく、直近の急上昇ワードが対象になります
trending_searchesを利用して、pnを日本に設定します
pytrends.trending_searches(pn='japan')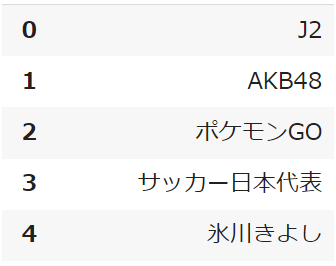
pnを変更することで、アメリカの急上昇ワードを取得することも可能
pytrends.trending_searches(pn='japan')
!pip install pytrends
from pytrends.request import TrendReq
pytrends = TrendReq(hl='ja-JP', tz=-540)
df = pytrends.trending_searches(pn='japan')⑥ 年間の急上昇ワード(top_charts)
年度ごとの急上昇ワード(人気が出たキーワード)を取得することができます
top_chartsを設定し、続いて取得したい年を記述します(2020など)
エリアや時間帯としてhl tz geo も指定します
pytrends.top_charts(2020, hl='ja-jp', tz=540, geo='JP')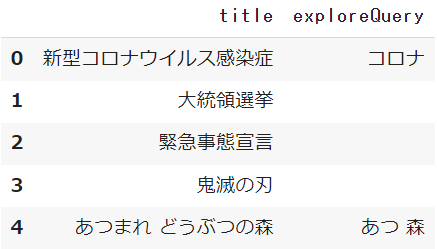
検索データの注意事項
期間の設定方法
検索数の推移で指定したtimeframeですが、期間の設定に注意する必要があります
pytrends.build_payload(kw_list=kw_list,
timeframe='2019-01-01 2021-06-30',
geo='JP')最長で2004年までさかのぼることができますが、デフォルトでは直近5年の推移を取得します
1日ごとのデータを取得するにはさかのぼる期間を短く設定してください
timeframe='all' #2004年から(1か月ごと)
timeframe='today 5-y' #直近5年(1週間ごと)※デフォルト
timeframe='today 3-m' #直近3か月(1日ごと)※1.2.3のみ
timeframe='2020-01-01 2020-12-31' #任意指定(1日/1週間ごと)実数ではなく統計化されたデータ
「検索」というデータは個人を特定することができる非常にセンシティブな情報です
Google側もすべてのデータを提供しているわけではありません
そのため加工されたデータをPythonで取得しているということを意識する必要があります
Googleトレンドのデータの特徴としては大きく分けて2つ
- 最大値が100としてデータが抽出される
- 検索数の少ないニッチなワードは抽出できない
①は検索の総数が分からないように統計化されています
例えば4つのキーワード(ドコモ・ソフトバンク・au・楽天モバイル)の検索を比較したときに、最大値のドコモの検索が100として表現されています
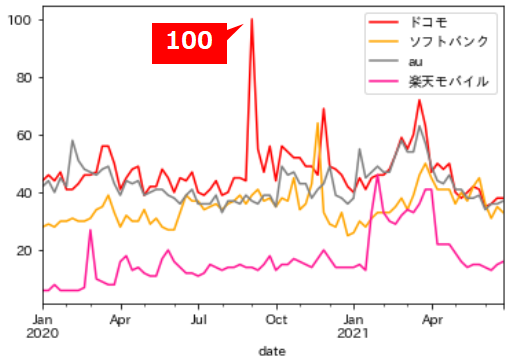
つまり検索数が圧倒的に違うキーワード同士を比較することが非常に難しい
試しにアメリカの小売り3社を比較しても、日本での認知が圧倒的に高い「アマゾン」と比較して他が「0」となってしまいます
 【Python】一瞬で書けるグラフ作成|matplotlib
【Python】一瞬で書けるグラフ作成|matplotlib
②のニッチワードについては、検索数が少ない場合はデータを取得できません
キーワードを繋げすぎてしまうと検索数が少なくなるため注意です
下記コードでは結果は取得できませんでした
kw_list = ['ソフトバンク 料金プラン 最安値']
pytrends.build_payload(kw_list=kw_list, timeframe='2020-01-01 2021-06-30', geo='JP')
pytrends.interest_over_time()まとめ
今回はpytrendsを利用しGoogleトレンドのデータをPythonで取得する方法をご紹介してきました
検索のデータはマーケティングに非常に有効に利用することができます
ユーザーニーズを分析するときに使ってみてください
実際に利用している記事もあるためぜひご覧ください
 携帯キャリア3社+楽天モバイルをGoogle検索で分析してみた
携帯キャリア3社+楽天モバイルをGoogle検索で分析してみた
 地方に愛されているプロ野球球団はどこだ?Google検索で分析してみた
地方に愛されているプロ野球球団はどこだ?Google検索で分析してみた
 今注目の”あるもの”の価格と検索数をGoogle検索で分析してみた
今注目の”あるもの”の価格と検索数をGoogle検索で分析してみた