

目次
事前準備
「Pandas」というデータ解析を実施できるライブラリをインポートします
import pandas as pdread_excelの使い方
read_excel()はエクセルファイル( .xls, .xlsx, .xlsm )をPythonに読み込むことができます
※pandasの機能を使うために頭に「pd.」を付けましょう(事前準備でPandasをpdと名付けています)
pd.read_excel('/content/drive/MyDrive/python/ファイル名.xlsx')pd.read_excel('ファイル名.xlsx')エクセルファイルが置いてあるファイルパス(もしくはファイル名)を指定することで、Pythonに読み込むことができます
またパラメータを指定することで、どのシートから取ってくるか、ヘッダーは必要かなども設定することができます
このようなエクセルファイルを「Python」で読み込みます
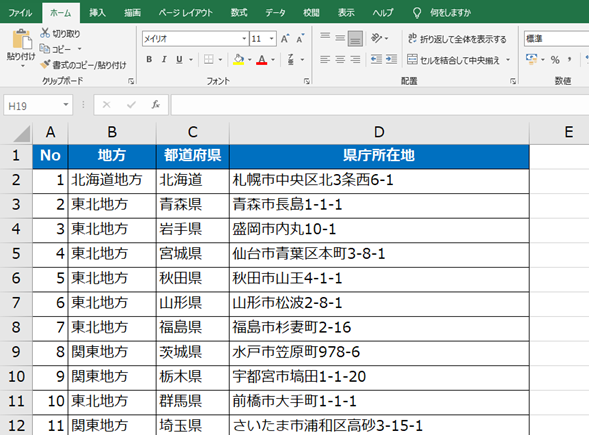
sample = pd.read_excel('サンプルデータ.xlsx')
sample.head()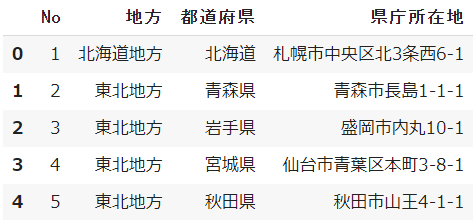
※Google Colaboratoryにエクセルファイルをアップロードする方法
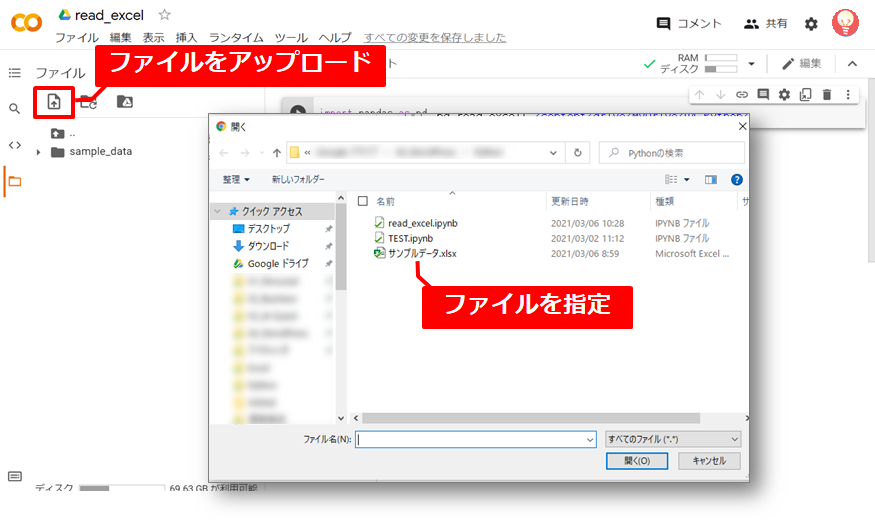
※Google Driveと連携する方法
 【Python】Google ColaboratoryとGoogle Driveを連携する方法
【Python】Google ColaboratoryとGoogle Driveを連携する方法パラメータ
おすすめ度を判定:★★★=必須|★★☆=推奨|★☆☆=任意
★★★:ファイルパス/ファイル名
pd.read_excel('ファイル名.xlsx')
pd.read_excel('/content/drive/MyDrive/python/ファイル名.xlsx')”シングルクォーテーションか“”ダブルクォーテーションを付けて
ファイル名やファイルパスを記載します
拡張子(.xlsxなど)を忘れずに記載してください
★★☆:index_col(インデックス/先頭列)
pd.read_excel('ファイル名.xlsx', index_col=None)インデックスを指定します
何も設定しないと自動的にインデックスが作成されます(0始まりの連番)
- index_col = None(0始まりの連番が作成される)※デフォルト
- index_col = 0(1列目がインデックスになる)
- index_col = 1(2列目がインデックスになる)
- index_col = 1, 2(2,3列目がマルチインデックスになる)
初期設定ではインデックスが自動的に設定されてしまうため、
「index_col= 0」の設定を推奨します
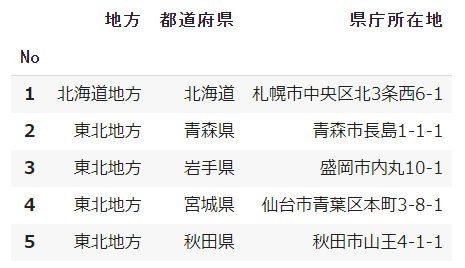
また表が「A列」から始まっていないとき、インデックスとなる列を設定しましょう
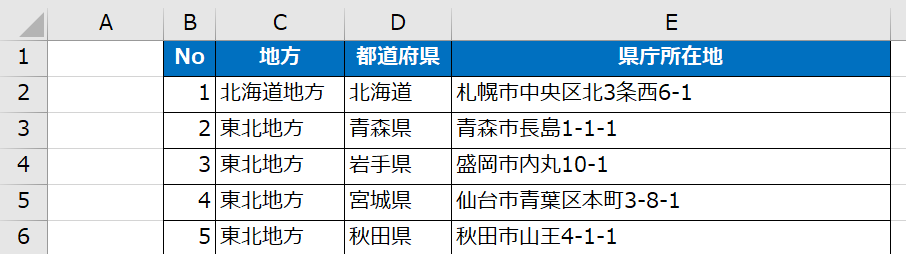
★☆☆:sheet_name(シート名)
pd.read_excel('ファイル名.xlsx', sheet_name=0)読み込むシート名を指定することができます
何も指定しないと最初のシートになります
- sheet_name = 0(最初のシートを読み込む)※デフォルト
- sheet_name = 1(2番目のシートを読み込む)
- sheet_name = “sheet1”(シート名を読み込む)
- sheet_name = [0, 1, 2](複数シートを読み込む)
- sheet_name = None(すべてのシートを読み込む)
※複数のシートを指定した場合は、値が辞書型として読み込まれます
★☆☆:header(ヘッダー/先頭行)
pd.read_excel('ファイル名.xlsx', header=0)ヘッダーの位置を指定します
何も設定しないと1行目がヘッダーになります
- header = 0(1行目がヘッダーになる)※デフォルト
- header = 1(2行目がヘッダーになる)
- header = 1, 2(1,2行目がマルチカラムとしてヘッダーになる)
- header = None(ヘッダー無し、0からの連番)
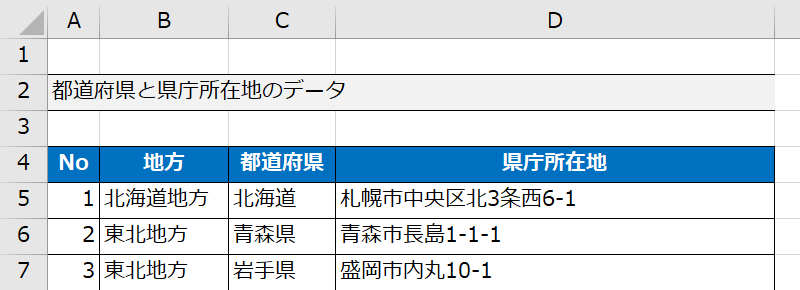
表のヘッダーが「先頭行にない」とき、「header」のパラメータで調整しましょう
下記の場合は「header=3」が適切
★☆☆:usecols(使う列)
pd.read_excel('ファイル名.xlsx', usecols=None)使う列をパラメータで指定することができます
- usecols = None(すべての列)※デフォルト
- usecols = ‘A’(エクセルのA列のみ)
- usecols = ‘A,B,C’(エクセルのA,B,C列)
- usecols = ‘A:C’(エクセルのA~C列)
- usecols = [1](2列目のみ)※一列でも[]リストを使う
- usecols = [1, 2, 3](2,3,4列)
- usecols = [‘都道府県’](都道府県というカラムのみ)
- usecols = [‘都道府県’,’地方’](都道府県と地方というカラムのみ)
使う列に関しては「エクセルから読み込むときに抽出する」と「Pythonで取捨選択する」の2パターンあります。
データが多すぎる場合は「usecols」を使って、読み込むデータを減らして読み込みましょう
★☆☆:skiprows(読み込まない行)
pd.read_excel('ファイル名.xlsx', skiprows=1)読み込まない行を選択します(※読み込まない設定なので注意!)
- skiprows = 2(先頭から2行を読み込まない)
- skiprows = [2, 4](2,4行目を読み込まない)
★☆☆:skipfooter(読み込まない最後の行)
pd.read_excel('ファイル名.xlsx', skipfooter=1)「skiprows」と似たようなパラメータですが、最後の行(フッター)で読み込まない行を指定できます
例えばエクセルである程度「集計」している場合、最後の行に「合計」の列があったりします
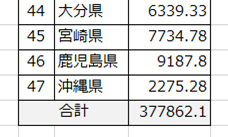
Pythonでこのまま集計してしまうと、この「合計欄」まで計算してしまいます…
- skiprows = 1(最後から1行を読み込まない)
まとめ
普段使っている「エクセル」のデータを
「Python」に読み込む方法をご紹介してきました
最低限のデータをread_excelで読み込み、
後はPythonで操作していきましょう


