 Smart-Hint
Smart-Hint 
目次
Produce101とは?
韓国の大人気の『PRODUCE 101』シリーズの日本版として2019年にスタート
練習生101人が日本国民(国民プロデューサー)の投票によって最終的に11人が選ばれ、グローバルに活躍するボーイズグループを目指す
2021/5/20現在シーズン2がスタートしています
分析の定義
- 期間:2021-01-01 ~ 2021-05-31
- メンバー:41人に残っている練習生
- 名称:「Produce 101 JAPAN」に統一(プデュ・Produce101では韓国・中国版も混じるため)
!pip install pytrends # GoogleTrendを使う
from pytrends.request import TrendReq # GoogleTrendを使う
pytrends = TrendReq(hl='ja-JP', tz=-540) # GoogleTrendを使う
import numpy as np # Numpyを使う
import pandas as pd # Pandasを使う
!pip install japanize-matplotlib # 日本語のmatplotlibを使う
import japanize_matplotlib # 日本語のmatplotlibを使う
import matplotlib.pyplot as plt # matplotlibを使う
%matplotlib inline # matplotlibをjupyterで使う
import seaborn as sns # Seabornを使うkw_list_1 = ['木村 柾哉','田島 将吾','藤牧 京介','西 洸人','尾崎 匠海']
kw_list_2 = ['田島 将吾','西島 蓮汰','佐野 雄大','髙塚 大夢','後藤 威尊']
kw_list_3 = ['田島 将吾','大久保 波留','飯沼 アントニー','許 豊凡','寺尾 香信']
kw_list_4 = ['田島 将吾','太田 駿静','池﨑 理人','森井 洸陽','テコエ 勇聖']
kw_list_5 = ['田島 将吾','福田 翔也','栗田 航兵','仲村 冬馬','小林 大悟']
kw_list_6 = ['田島 将吾','中野 海帆','篠原 瑞希','松田 迅','小池 俊司']
kw_list_7 = ['田島 将吾','ヴァサイェガ 光','村松 健太','平本 健','井筒 裕太']
kw_list_8 = ['田島 将吾','大和田 歩夢','四谷 真佑','笹岡 秀旭','小堀 柊']
kw_list_9 = ['田島 将吾','阪本 航紀','上田 将人','福田 歩汰','飯吉 流生']
kw_list_10 = ['田島 将吾','松本 旭平','内田 正紀','髙橋 航大']
pytrends.build_payload(kw_list=kw_list_1, timeframe='2021-01-01 2021-05-31',geo='JP')
df1 = pytrends.interest_over_time().drop('isPartial', axis=1)
pytrends.build_payload(kw_list=kw_list_2, timeframe='2021-01-01 2021-05-31',geo='JP')
df2 = pytrends.interest_over_time().drop(['田島 将吾','isPartial'], axis=1)
pytrends.build_payload(kw_list=kw_list_3, timeframe='2021-01-01 2021-05-31',geo='JP')
df3 = pytrends.interest_over_time().drop(['田島 将吾','isPartial'], axis=1)
pytrends.build_payload(kw_list=kw_list_4, timeframe='2021-01-01 2021-05-31',geo='JP')
df4 = pytrends.interest_over_time().drop(['田島 将吾','isPartial'], axis=1)
pytrends.build_payload(kw_list=kw_list_5, timeframe='2021-01-01 2021-05-31',geo='JP')
df5 = pytrends.interest_over_time().drop(['田島 将吾','isPartial'], axis=1)
pytrends.build_payload(kw_list=kw_list_6, timeframe='2021-01-01 2021-05-31',geo='JP')
df6 = pytrends.interest_over_time().drop(['田島 将吾','isPartial'], axis=1)
pytrends.build_payload(kw_list=kw_list_7, timeframe='2021-01-01 2021-05-31',geo='JP')
df7 = pytrends.interest_over_time().drop(['田島 将吾','isPartial'], axis=1)
pytrends.build_payload(kw_list=kw_list_8, timeframe='2021-01-01 2021-05-31',geo='JP')
df8 = pytrends.interest_over_time().drop(['田島 将吾','isPartial'], axis=1)
pytrends.build_payload(kw_list=kw_list_9, timeframe='2021-01-01 2021-05-31',geo='JP')
df9 = pytrends.interest_over_time().drop(['田島 将吾','isPartial'], axis=1)
pytrends.build_payload(kw_list=kw_list_10, timeframe='2021-01-01 2021-05-31',geo='JP')
df10 = pytrends.interest_over_time().drop(['田島 将吾','isPartial'], axis=1)
df = pd.merge(df1,df2,on='date',how='left')
df = pd.merge(df,df3,on='date',how='left')
df = pd.merge(df,df4,on='date',how='left')
df = pd.merge(df,df5,on='date',how='left')
df = pd.merge(df,df6,on='date',how='left')
df = pd.merge(df,df7,on='date',how='left')
df = pd.merge(df,df8,on='date',how='left')
df = pd.merge(df,df9,on='date',how='left')
df = pd.merge(df,df10,on='date',how='left')そもそもProduce101の人気は?
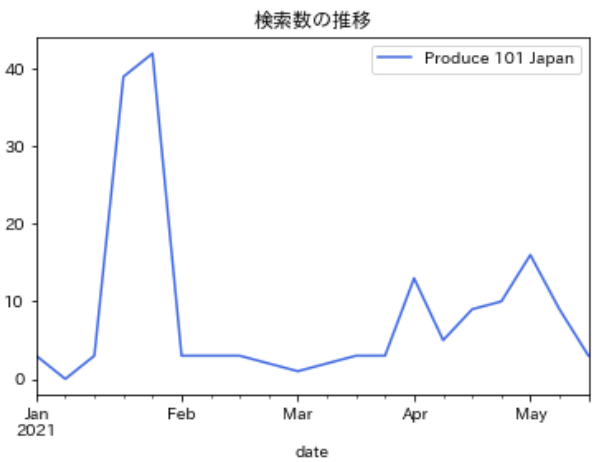
- オンタクト能力評価が公開になった1月後半に大きな山が来ている
- 放送が始まってから検索数が徐々に上がっている
kw_list = ['Produce 101 Japan']
pytrends.build_payload(kw_list=kw_list,timeframe='2019-01-01 2021-05-31',geo='JP')
df_all = pytrends.interest_over_time().drop('isPartial', axis=1)
df_all.reset_index().query('date>"2021-01-01"').set_index('date').plot(color='royalblue',title='検索数の推移')シーズン1の時期と比べると?
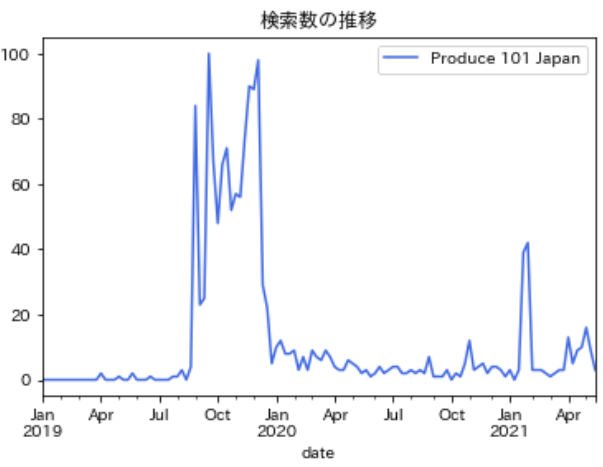
- シーズン1の期間(2019年)と比べると検索数は多くない
- シーズン2など他の検索ワードで検索している可能性あり
まだまだこれからエピソードもあるので、人気が出るのを期待しましょう
kw_list = ['Produce 101 Japan']
pytrends.build_payload(kw_list=kw_list,timeframe='2019-01-01 2021-05-31',geo='JP')
df_all = pytrends.interest_over_time().drop('isPartial', axis=1)
df_all.plot(color='royalblue',title='検索数の推移')検索数が多いメンバーは?
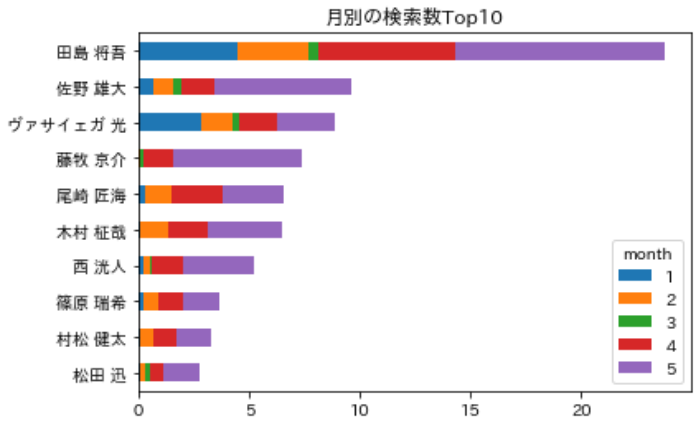
気になるメンバー単位の件数がこちら!
- 「田島くん」が圧倒的に検索が多い
- 「佐野くん」「藤牧くん」は5月に検索を伸ばした
- 「ヴァサイェガくん」は1月の検索が多い
想像とは違っていましたか?実際の順位との比較もしていきます
df_month = df.reset_index()
df_month['month'] = df_month['date'].dt.month
df_month = df_month.drop('date',axis=1)
df_month = df_month.pivot_table(index='month',aggfunc='mean').transpose()
df_month["all"] = df_month.mean(axis=1)
df_month.sort_values('all').tail(10).drop('all',axis=1).plot.barh(stacked=True,title='月別の検索数Top10')5月だけではどういう結果なの?
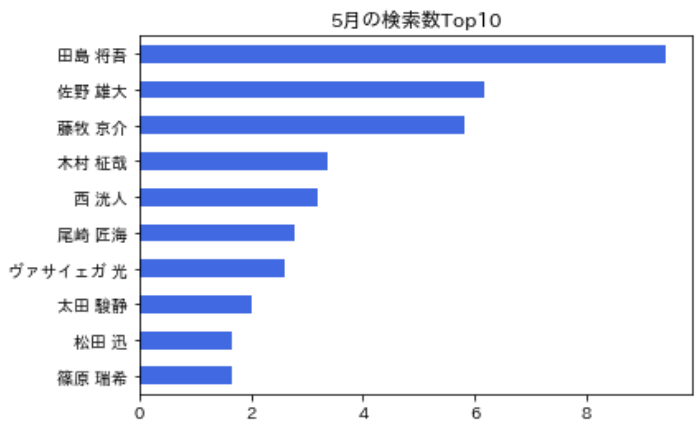
- 1月~5月の結果とは順位が大きく異なる
- 「佐野くん」「藤牧くん」は5月に検索を伸ばした
df_month.sort_values(5).tail(10)[5].plot.barh(color='royalblue',title='5月の検索数Top10')5月で検索を大きく伸ばしたメンバーは?
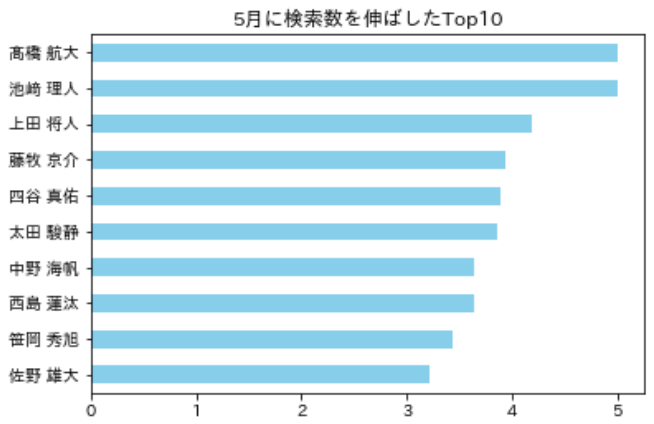
今度は「5月」に検索を伸ばした(割合)メンバーに絞って分析してみました
- 先ほどのTop10とは大きくメンバーが異なる
- 順位が低いメンバーの方が検索上昇率が高くなりやすい
df_month['up'] = df_month[5]/df_month['all']
df_month.sort_values('up').tail(10)['up'].plot.barh(color='skyblue',title='5月に検索数を伸ばしたTop10')順位と検索の差はあるの?
左が「5週目の順位」で、右が「検索の順位」です
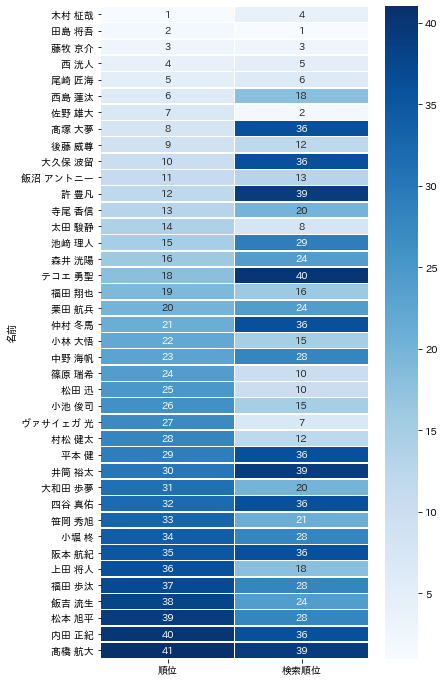
- 上位5人は実際の順位と検索で差はほとんどない
- それ以下ではかなり順位との差がある
df_month.index.name = '名前'
df_rank = df_month[5]
df_rank = df_rank.rank(ascending=False,method='max').round()
rank = pd.read_excel('/content/drive/MyDrive/Python/Produce101_season2_member_5week.xlsx',sheet_name=0)
rank = rank.merge(df_rank,on='名前', how='left')
rank.rename(columns={5:'検索順位'},inplace=True)
plt.figure(figsize=(6,12))
sns.heatmap(rank.set_index('名前'), annot=True, cmap='Blues', linewidths=.5)まとめ
エピソードが放送されて注目されるメンバーがいたり、
そもそも漢字が打ちにくく検索されにくいメンバー(許 豊凡)もいたりしました
実際に人気のあるメンバーは検索もされることが多いことが分かりました

