

目次
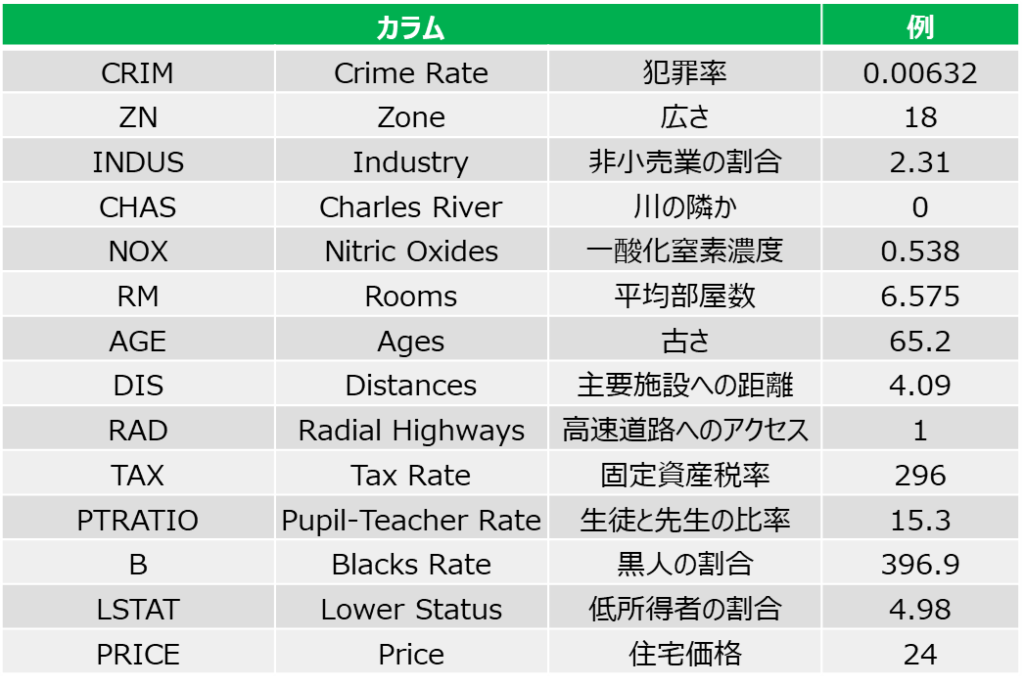
ボストン住宅価格のサンプルデータとは?

今回紹介する「ボストン住宅価格」のデータは、機械学習の回帰タスクのサンプルデータとして利用されます
1970年代後半におけるアメリカのボストン街にある区画の住宅の価格(中央値)を予測します
13個の説明変数と、1個の目的変数(Target)のデータが存在していて、
説明変数には「平均部屋数」や「家の古さ」、「川や高速道路へのアクセス」や「周辺の犯罪率」があります
つまりこのデータの方向性は下記になります
住宅周辺の環境データから、住宅価格を予測する
どのようなデータが格納されているか、詳しく説明していきます
事前準備
sklearnからload_bostonをインポートし、DataFrameにそれぞれ格納します
import pandas as pd
import seaborn as sns
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['PRICE'] = boston.target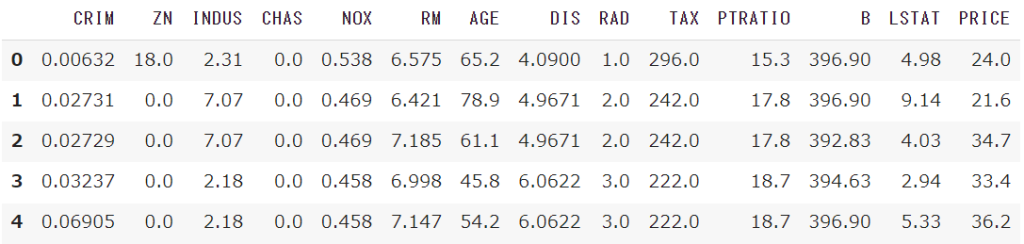
データ内容のご紹介
sklearnからインポートできる「ボストン住宅価格」のデータは、カラム名が省略された英字になっています
また全て数値のデータになっています
それぞれのデータの個数をseabornを使って可視化します
 【Python】seabornで綺麗なグラフ作成を!たった1行で書けます
【Python】seabornで綺麗なグラフ作成を!たった1行で書けます 犯罪率(CRIM)
いきなり物騒な指標ですが、CRIMは犯罪発生率です
街を選ぶときに、治安は重要な指標の一つなので住宅価格に影響を与えている可能性があります
sns.histplot(df, x='CRIM', binwidth=5)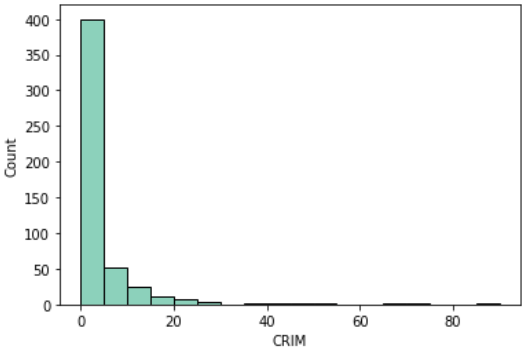
広い家の割合(ZN)
ZNは広い部屋の割合を示します
正確には「25,000平方フィートを超える区画に分類される住宅地の割合」を示す指標です
sns.histplot(df, x='ZN', binwidth=10)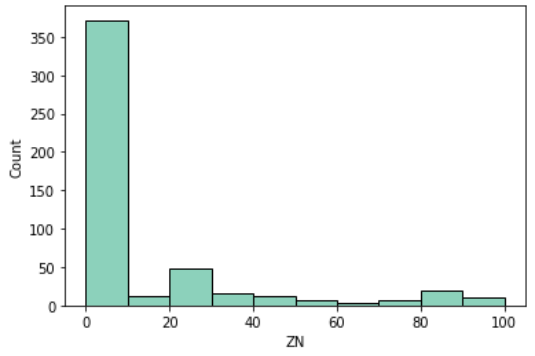
非小売業の割合(INDUS)
INDUSはIndustryの略で、町別の「非小売業の割合」を示す指標です
街ごとの産業の違いの情報が入っています
sns.histplot(df, x='INDUS')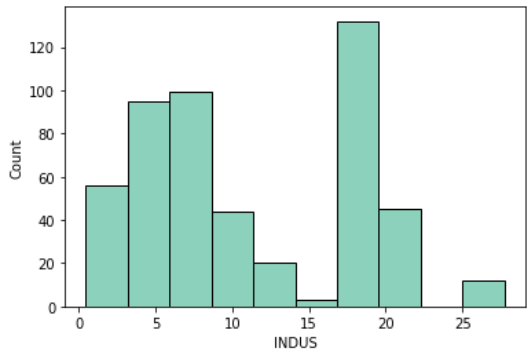
チャールズ川の近くか(CHAS)
CHASはCharles Riverのことで、区画がチャールズ側に面していれば「1」、面していなければ「0」となります
sns.countplot(data=df, x='CHAS')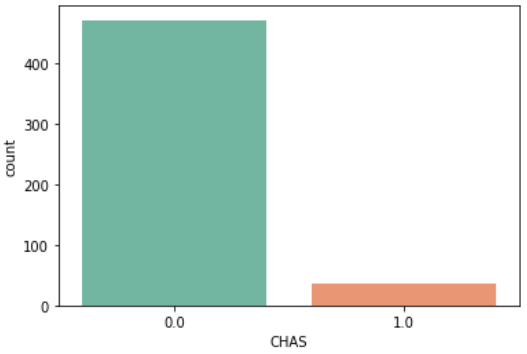
一酸化窒素濃度(NOX)
NOXは一酸化窒素濃度を示しています
Wikipediaの説明から、光化学スモッグや酸性雨の原因になるようで、住宅価格には悪影響を与えそうです
一酸化窒素(nitric oxide)
一酸化窒素(いっさんかちっそ、nitric oxide)は窒素と酸素からなる無機化合物で、化学式であらわすと NO。酸化窒素とも呼ばれる。
常温で無色・無臭の気体。水に溶けにくく、空気よりやや重い。有機物の燃焼過程で生成し、酸素に触れると直ちに酸化されて二酸化窒素 NO2 になる。硝酸の製造原料。光化学スモッグや酸性雨の成因に関連する。また体内でも生成し、血管拡張作用を有する。窒素の酸化数は+2。
Wikipedia
sns.histplot(df, x='NOX')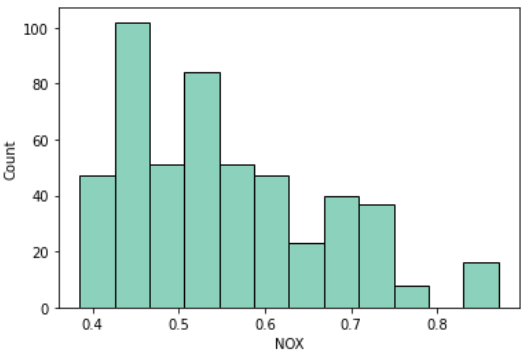
平均部屋数(RM)
1戸当たりの「平均部屋数」を示しています
部屋数はまさに住宅価格に影響を与えそうです
sns.histplot(df, x='RM')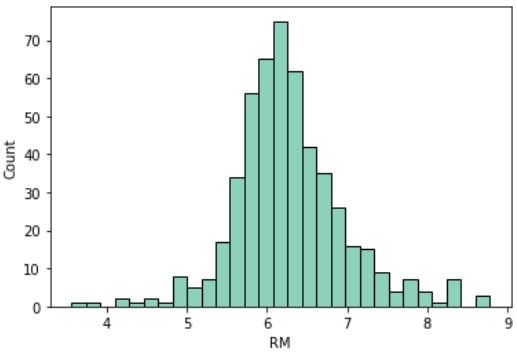
家の古さ(AGE)
AGEは1940年より前に建てられた持ち家の割合を示しています
「ボストン住宅価格」のデータは1970年代後半におけるデータなので、築年数が35~40年ほどの割合です
sns.histplot(df, x='AGE', binwidth=5)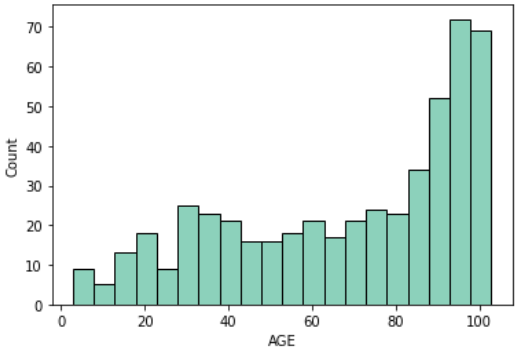
主要施設への距離(DIS)
DISはDistanceの略で、5つあるボストンの雇用センターまでの距離(重み付き距離)です
sns.histplot(df, x='DIS')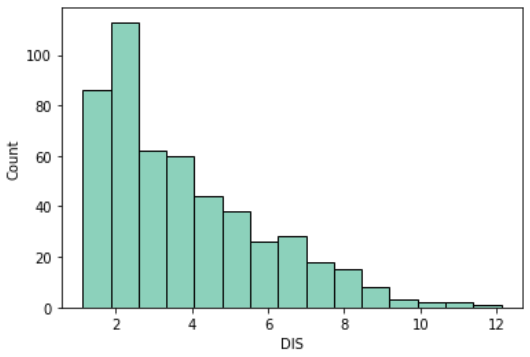
高速道路へのアクセス性(RAD)
主要高速道路へのアクセス性を指標化したものがRADです
中身見てみるととびぬけて大きい区画があるようです
sns.histplot(df, x='RAD')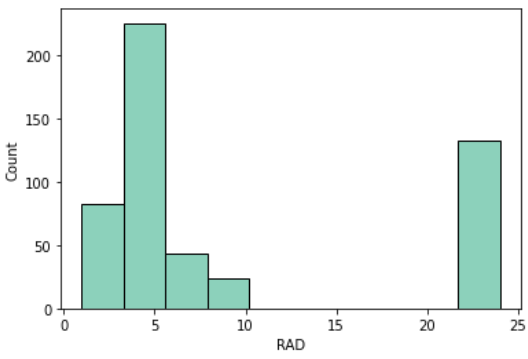
固定資産税(TAX)
TAXは10,000ドル当たりの「固定資産税率」を示しています
固定資産税とは家の所有者に対し、その固定資産の価格をもとに算定される税のことです
sns.histplot(df, x='TAX')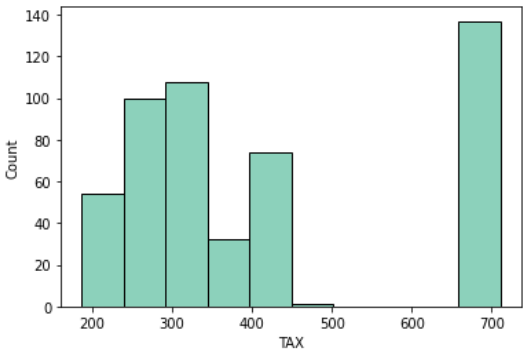
生徒と先生の比率(PTRATIO)
PTRATIOは町別の生徒と先生の比率です
一人の先生に対して、どのくらい生徒がいるかを示す指標です
sns.histplot(df, x='PTRATIO')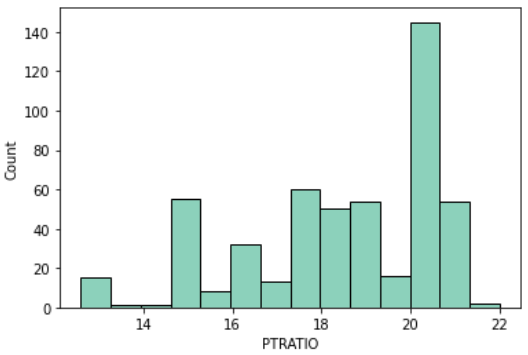
黒人の割合(B)
Bは町ごとの黒人の割合を示しています
日本では異なる人種が街にいるのがイメージしにくいですが、米国では町の文化を決める要因になっています
sns.histplot(df, x='B', binwidth=10)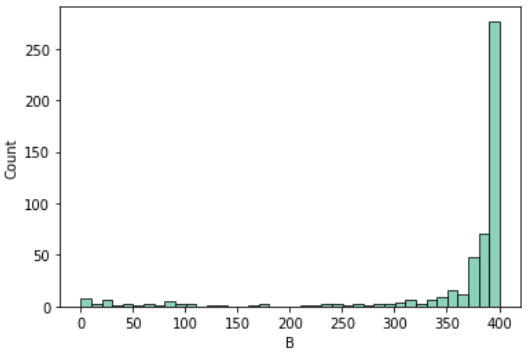
低所得者の割合(LSTAT)
LSTATは町の低所得者の割合を示しています
sns.histplot(df, x='LSTAT')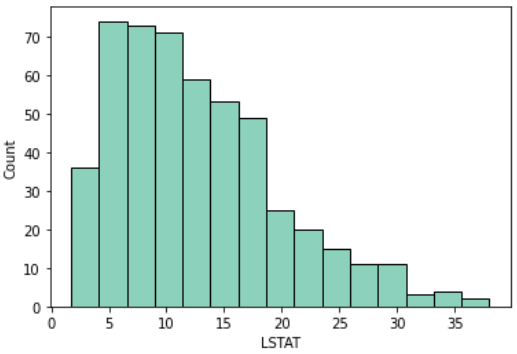
住宅価格(PRICE)
最後に本データセットの目的変数となる「住宅価格」を示すPRICEです
PRICEは筆者が定義した名称のため、他のサイトでは別の変数名になっている可能性があります
load_bostonからtargetで取得することができます
住宅価格(1000ドル単位)の中央値になります
sns.histplot(df, x='PRICE')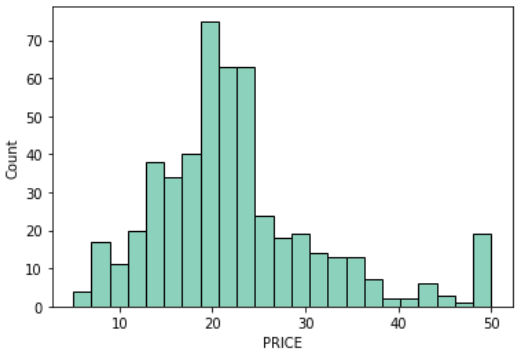
相関関係を確認する
ボストン住宅価格を予測するために、目的変数(住宅価格)に大きな影響を与えているであろう要素を探します
まずは14個の項目(カラム)それぞれの相関を算出してみます
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize=(10,8))
mask = np.zeros_like(df.corr())
mask[np.triu_indices_from(df.corr())] = True
with sns.axes_style("white"):
ax = sns.heatmap(df.corr(), mask=mask, square=True, linewidths=0.5, cmap='coolwarm', annot=True)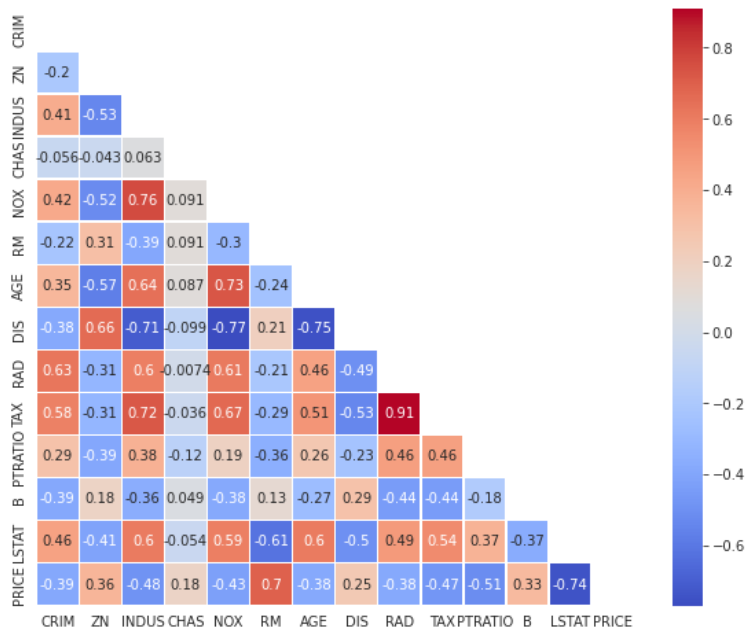
RAD(高速道路へのアクセス性)とTAX(固定資産税)が正の相関が高いことや
それぞれの相関の高さ・低さが分かります
続いて目的変数である「住宅価格PRICE」に対する、説明変数の相関を見てみます
df_corr = df.drop('PRICE', axis=1)
df_corr = df_corr.corrwith(df['PRICE'])
df_corr.plot.barh(figsize=(4,6))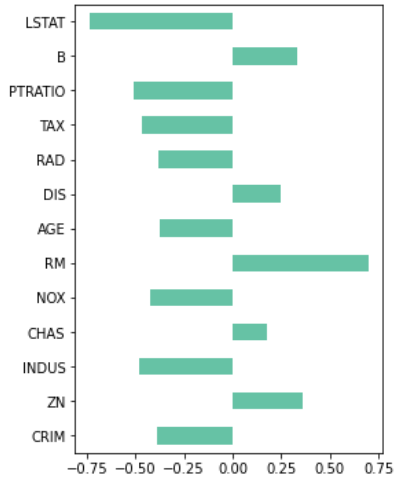
正の相関や負の相関がくっきり分かれました
相関に関しては下記記事で詳しく説明しているのでご覧ください
 相関関係とは?分析に欠かせない要素を分かりやすくご紹介
相関関係とは?分析に欠かせない要素を分かりやすくご紹介  【Python】相関係数を求める方法|ヒートマップでの可視化
【Python】相関係数を求める方法|ヒートマップでの可視化 注意事項
ボストン住宅価格のサンプルデータは、機械学習やディープラーニングの世界では非常に有名なサンプルデータです
一方でこのデータには注意しなければならない点がいくつかあります
① データ量が多くない
このデータセットは「504行」x「14列」のデータで成り立っています
機械学習を学ぶ目的で利用するには、処理しやすい量のデータではあるものの、実際にモデル運用する際には十分な量とは言えません
あくまでも少量のデータだということを念頭に置いて分析を進めてください
② 1970年代後半のデータである
データセットが1970年代後半の内容であるため、現在から約50年ほど前のデータになります
文化や価値観、技術の変化がある前提で分析をするようにしましょう
※とはいえ住宅に影響を与える項目はそこまで変わらない
③ 人種のデータを利用している
住宅価格のデータ要素にはB(黒人の割合)が存在しています
これは人種差別と捉えられる内容であるため、注意が必要です
住宅価格の予測では問題ないかもしれません
しかし業務で仮に「社員採用のために機械学習を利用」するときに、人種や性別、宗教や思想などの説明変数を使ってしまうと、意図せずとも「差別」を助長してしまう可能性があります
まとめ
機械学習の回帰タスクのサンプルデータとよく利用される「ボストン住宅価格」のサンプルデータをご紹介してきました
整理されているデータではある一方で、データ量や性質で注意事項があるため気を付けて使ってみてください
分類タスクでよく利用される「タイタニック号のデータ」はこちらをご覧ください
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介します 

