 Smart-Hint
Smart-Hint 
目次
ロジスティック回帰とは
ロジスティック回帰は、2値の目的変数を予測するために利用されるモデルです
2値の目的変数とは「正解・不正解」「合格・失格」「陽性・陰性」などの2つしかない値のことです
機械学習の予測を行う際は、「正解=1・不正解=0」のように「0-1」の数値に置き換えて予測を行っていきます
今回はPythonで「タイタニック号の生存者」をテーマにロジスティック回帰を実施します
このデータには乗客ごとの性別や年齢、どの客席にいたかなどの情報(説明変数)があり
タイタニック号で生存するか(目的変数)を予測していきます
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介します
ロジスティック回帰には数式が存在しますが、複雑になってしまうので今回は割愛します
事前準備
Seabornから、タイタニック号のデータを取得しておきます
またPandasも合わせてインポートしておきます
import seaborn as sns
import pandas as pd
df = sns.load_dataset('titanic')
df.head()
ロジスティック回帰の前処理
線形回帰モデルの特徴は下記になるため、その処理が必要になります
- 特徴量は数値形式(1.2.3…)
- 欠損値を扱うことができない(Null)
- 特徴量に標準化が必要(特徴量の大きさに差があるとき)
説明変数(x)と目的変数(y)に分割
事前準備で用意した変数(df)を説明変数と目的変数に分割します
生存者を示す(survivedとalive)を取り除きましょう
df_x = df.drop(['survived','alive'], axis=1)
df_y = df['survived']![df_x = df.drop(['survived','alive'], axis=1)](https://smart-hint.com/wp-content/uploads/2022/01/image-133-1024x207.png)
![df_y = df['survived']](https://smart-hint.com/wp-content/uploads/2022/01/image-134.png)
ダミー変数処理(文字列→数値)
get_dummiesで文字列型のデータを数値型(0-1)に変換します
df_x = pd.get_dummies(df_x)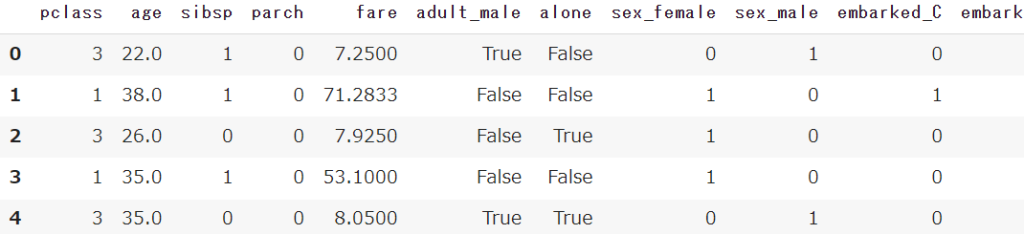
 【Python】カテゴリ変数の数値変換|ダミー処理(one-hot encoding / label encoding)
【Python】カテゴリ変数の数値変換|ダミー処理(one-hot encoding / label encoding)
欠損値を処理する
欠損値があるとロジスティック回帰は処理できないため、fillnaで欠損値を別の数値に変換します
今回は簡易的な予測のため全て「0」に置き換えますが、本来であれば平均・中央値などで変換するのが最適です
df_x = df_x.fillna(0) 【Python】欠損値の扱い方大全
【Python】欠損値の扱い方大全
学習用-テスト用に分割
train_test_splitを使って、学習用とテスト用にデータを分割します
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(df_x, df_y, random_state=1)
 【機械学習】学習-テストデータに分割(hold-out法)|train_test_split
【機械学習】学習-テストデータに分割(hold-out法)|train_test_split
標準化を実施する
StandardScalerで数値のスケールを揃える標準化を実施します
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
pd.DataFrame(scaler.fit_transform(df_x),
columns=df_x.columns)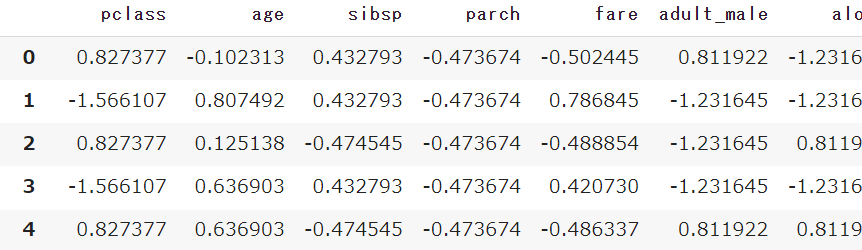
 【機械学習】標準化と正規化をPythonで実施する|特徴量スケーリング
【機械学習】標準化と正規化をPythonで実施する|特徴量スケーリング
ロジスティック回帰モデルの作成と予測
まずはLogisticRegressionのモデルを作成します
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(random_state=1)上記で前処理を実施したデータをfitメソッドで学習を行います
model.fit(train_x,train_y)モデルに対してpredict_probaで予測を実施します
predict_probaは2値(0-1)ではなく、1になる確率を返します(例:0.85)
pred = model.predict_proba(test_x)ロジスティック回帰の評価
log_lossを使った評価
log_lossを使って分類タスクの評価を実施します
from sklearn.metrics import log_loss
score = log_loss(test_y, pred)
print(f'logloss:{score:.4f}')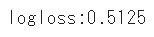
混同行列で評価を可視化
続いて混同行列を使って、予測と実数の真偽を可視化します
predictメソッドを使うと2値(0-1)で予測結果を算出することができます
from sklearn.metrics import confusion_matrix
pred = model.predict(test_x)
cm = confusion_matrix(test_y, pred)
sns.heatmap(cm, annot=True, cmap='Oranges', fmt='d')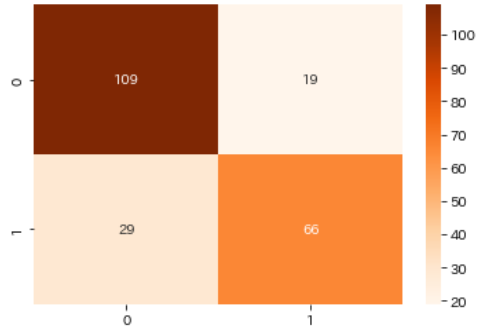
 【機械学習】分類の評価指標を一番分かりやすく解説|confusion-matrix
【機械学習】分類の評価指標を一番分かりやすく解説|confusion-matrix
回帰係数を算出する
説明変数が目的変数に及ぼす影響度を表わす係数を算出することで、どの情報がより予測結果(生存か死亡か)に影響を与えるかを可視化します
coef_を利用すればロジスティック回帰モデルから係数を算出することができます
model.coef_
説明変数ごとの係数がarray形式で出てくるため、先ほど使っていた変数(df_x)のカラム名と組み合わせます
※行列を入れ替えるため.Tを使っています
df_coef = pd.DataFrame(model.coef_.T, index=df_x.columns, columns=['coef'])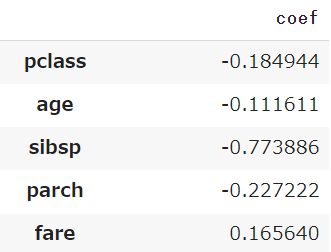
せっかくなのでmatplotlibで棒グラフでグラフ化しましょう
df_coef.plot.barh(figsize=(4,10))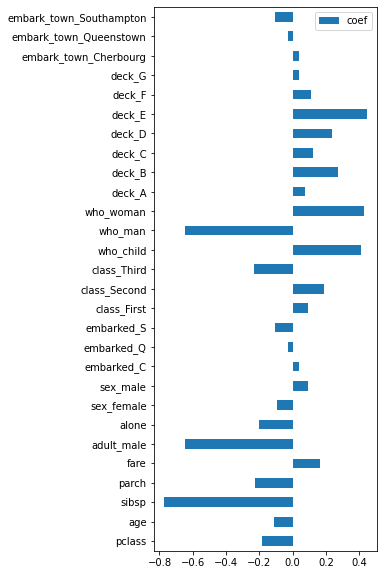
まとめ
今回はLogisticRegressionを使ってPythonでロジスティック回帰を実施してきました
非常に基本的な手法で、そこまで複雑ではないのでぜひ実践で試してみてください
全てのコード
# 事前準備
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import log_loss
from sklearn.preprocessing import StandardScaler
# タイタニック号のデータを取得
df = sns.load_dataset('titanic')
# 説明変数と目的変数に分割
df_x = df.drop(['survived','alive'], axis=1)
df_y = df['survived']
# 前処理(ダミー変数化と欠損処理)
df_x = pd.get_dummies(df_x)
df_x = df_x.fillna(0)
# 前処理(標準化)
scaler = StandardScaler()
pd.DataFrame(scaler.fit_transform(df_x),
columns=df_x.columns)
# 学習用-テスト用に分割
train_x, test_x, train_y, test_y = train_test_split(df_x, df_y, random_state=1)
# ロジスティック回帰のモデル作成と予測
model = LogisticRegression(random_state=1)
model.fit(train_x,train_y)
pred = model.predict_proba(test_x)
# ロジスティック回帰の評価
score = log_loss(test_y, pred)
print(f'logloss:{score:.4f}')
# ロジスティック回帰の係数を可視化
df_coef = pd.DataFrame(model.coef_.T, index=df_x.columns, columns=['coef'])
df_coef.plot.barh(figsize=(4,10))

