Smart-Hint
Smart-Hint 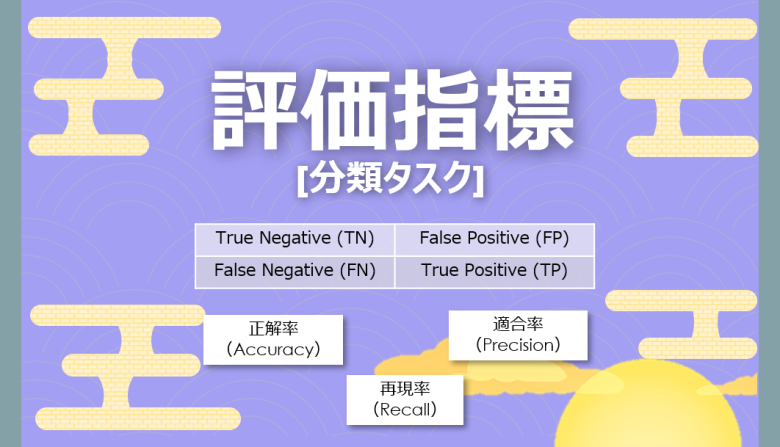
目次
機械学習の評価指標
今回は機械学習の予測に対する評価の手法について、グラフィックを多用してご説明します
機械学習において「分類」のタスクを行う際、その機械学習モデルの精度が高いか低いかを判断するために「指標」を利用します
ただし学校や会社での「評価」と同じように、単純に高い・低いの指標では図ることができません
特に機械学習の分類に関しては、予測が「当たった・外れた」だけではなく、実際は「0」だけど「1」と予測してしまったなど、複数のパターンが存在しています
例えば「病気」を予測する機械学習モデルでは、下記4パターンが存在しています
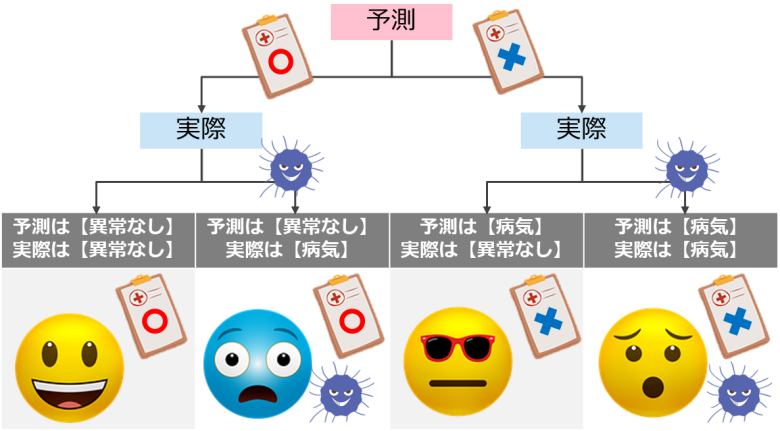
「異常なし」と診断して実際にも「異常なし」であれば問題はないですが、実際は「病気」なのに「異常なし」と診断してしまうケースがあります
この4パターンそれぞれの結果の割合を算出する評価指標をご紹介していきます
混同行列で整理する
分類の機械学習の評価で上記4パターンを整理するとき、混同行列を利用して整理します
混同行列(Confusion Matrix)は2値分類の結果を2 x 2のマトリックスでまとめたものです
「予測と実際」を縦横に並べて、それぞれの組み合わせを図示します

今回の病気を予測する機械学習では「病気=正(Positive)」と「異常なし=負(Negative)」と設定します
もちろん分類の手法では入れ替わる場合もあります
予測に対して正しければ「True」、間違っていれば「False」をつけて、「True Negative(TN)」などと説明されることが多いです
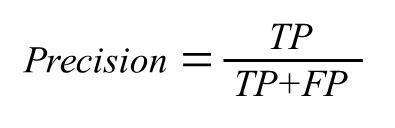
教科書では上記のような数式を用いて評価指標の説明をすることが多いですが、
本サイトではなるべくグラフィックを用いて分かりやすく解説します
正解率(Accuracy)
最初は「正解率」についてご説明します
おそらくどの指標よりも分かりやすく、一般的に理解されやすい手法です
すべての予測に対して、予測が合っていた割合


正解は「異常なしの人に異常なしと診断」と「病気の人に病気と診断」の2パターンが存在しているので、
全ての予測に対して、上記2パターンの数の割合になります
正解率は直感的に分かりやすい指標で、なおかつ全ての項目を含むため、この指標で十分でないかと思われるかもしれません
しかしほとんどがNegativeで、まれにPositiveになるようなケース(異常検知など)の不均衡なデータに対しては最適とは言えません
これから説明する指標でカバーしていくことになります
適合率(Precision)
続いての「適合率」は、対象を正(Positive)と予測した項目のみに絞ります
正(Positive)と予測した中で、予測が合っていた割合


右側の「正:Positive」と予測した人に限定して、予測が合っていた人の割合を算出します
例では「病気と診断した中で、実際に病気だった人」の割合が適合率です
適合率 (Precision)は、「FP:実際は異常なしだが、異常ありと予測」を防ぐ指標として利用されます
例えば迷惑メールを見つけ出す機械学習では、「FP:実際は通常のメールだが、迷惑メールと判断」されたものはゴミ箱に入ってしまい、コミュニケーションミスになる可能性があります
一方で適合率では評価されない「FN:迷惑メールだが、通常メールと判断」したものは、削除する手間がかかるくらいで大きな問題にはなりません
こういった可能性(率)を下げたい場合に適合率(Precision)を使います
再現率(Recall)
「再現率」は、対象を実際に正(Positive)だった人に絞ります
実際に正(Positive)の中で、予測が合っていた割合


表下の「正:Positive」な人に対して、予測が当たっていた率を算出します
再現率(Recall)は、「True Positive Rate」と呼ばれる場合もあります
再現率(Recall)は「FN:実際には異常があるが、異常なしと予測」を防ぐ目的で利用します
例えば、上記のように病気を見つける機械学習において、「FN:実際に病気だったが、異常なしと診断」してしまうと、命に関わるため防がなければいけません
一方で「FP:病気ではないが、病気と診断」しても、医療費はかかりますが最悪のケースには至りません
こういった病気や機械の異常の診断において再現率(Recall)を利用します
F値(F-measure)
続いての「F値」は少し変わり種です
前述した「適合率」と「再現率」の2つを利用します
適合率(Precision)と再現率(Recall)を組み合わせた指標

適合率(Precision)と再現率(Recall)はそれぞれ対照的な指標です
その2つを組み合わせることで、予測を外している「FP」と「FN」を考慮に入れて評価することができます
注目すべき点は、分子が「掛け算」なので適合率(Precision)と再現率(Recall)どちらかが低ければ、全体も低くなるように設定されています
F値は適合率(Precision)と再現率(Recall)の良いとこどりで、「FP」と「FN」のどちらも重要な時に利用します
偽陽性率(False Positive Rate)
偽陽性率はその名の通り、偽陽性(FP)の割合の指標です
実際に負(Negative)の中で、予測が間違っていた割合


偽陽性率(False Positive Rate)はこれまでの指標と異なり、小さければ小さいほどいい指標です
この「偽陽性率」はAUC(Area Under the Curve)と呼ばれる指標にも利用されます
まとめ
今回は機械学習の分類タスクで利用する「指標」についてご説明してきました
「予測」と「実際」の正負で4象限に分けて、それぞれに割合を算出してきました
機械学習は様々な分類タスクが存在しています
間違って予測するのがNGなケースもあれば、見落としがNGな場合もあります
様々な指標を使い分けてみてください
 【機械学習】Pythonで分類の評価指標を算出する
【機械学習】Pythonで分類の評価指標を算出する