 Smart-Hint
Smart-Hint 
目次
カテゴリ変数の変換を実施する
今回はPythonで文字列を代表とする「カテゴリ変数」を、「数値変数」に変換する方法をご紹介します
ダミー変数とも呼ばれており、Pythonを利用すると非常に簡単に実施することができます
文字列型や日付型などのカテゴリ変数は、多くの機械学習のモデルにおいてそのまま分析に利用することができません
またデータ分析の際も、カテゴリ変数ではなかなかグラフ化が難しかったりします
そこで2種類の変換方式を利用して、カテゴリ変数の変換を実施します
- one-hot encoding get_dummies
- label encoding LabelEncoder
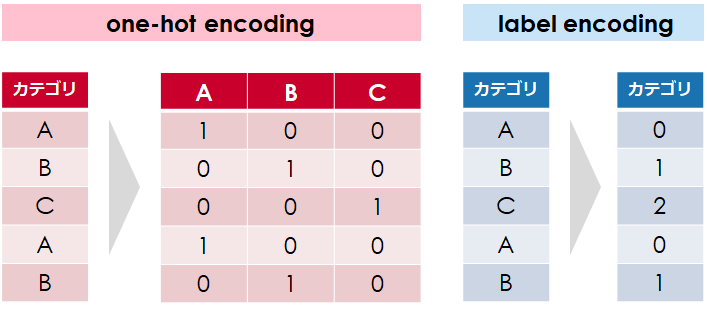
図の通り、「one-hot encoding」の場合はカテゴリの数だけ列(特徴値)が増えるのに対して、
「label encoding」はカテゴリの数を「0」から始まる数値に置き換えます
Pandasの関数で非常によく利用されるget_dummiesは前者の「one-hot encoding」を採用しており、機械学習でよく使われる手法です
それぞれ詳しくご紹介していきます
事前準備
Seabornというライブラリから、タイタニック号のデータを取得しておきます
またPandasも合わせてインポートしておきます
import seaborn as sns
import pandas as pd
df = sns.load_dataset('titanic')
df.head()
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介します
one-hot encoding
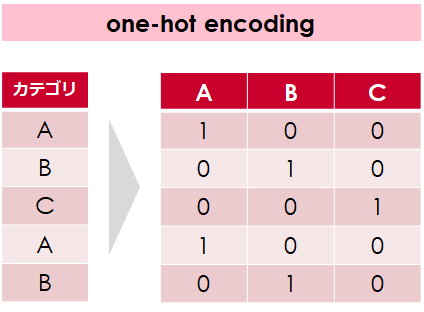
「one-hot encoding」はカテゴリ変数に対する変換手法として、最も利用されている手法です
カテゴリ変数の数に応じて列(特徴値)を増やし、そのカテゴリがあるかどうかを「0」か「1」かで置き換えます
つまりこの変換を実施すると、対象のカテゴリ変数の内容の数だけ列が作成されます
そしてこの変数はダミー変数と呼ばれます
get_dummies関数の利用
get_dummies関数を利用することで、DataFrameのカテゴリ変数列に対して変換を実施することができます
まずはタイタニック号の出航地(embark_town)のみ抽出してみます
3種類の出航地が文字列型で格納されています
df_town = pd.DataFrame(df['embark_town'])
df_town.head(6)![pd.DataFrame(df['embark_town'])](https://smart-hint.com/wp-content/uploads/2021/11/image-48.png)
3種類の出航地である「Southampton」「Cherbourg」「Queenstown」をそれぞれの列に分割し、「0」か「1」に置き換えます
get_dummiesの引数に、上記で作成した変数を指定します
pd.get_dummies(df_town)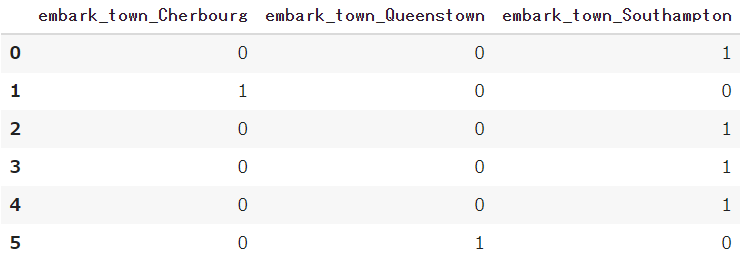
カテゴリ変数が3つの列に分けて新しく追加されました
非常に簡単にダミー変数を作成することができました
複数の列を変換する
複数のカテゴリ変数に対して変換を実施するには、パラメータのcolumnsを利用します
category = ['sex','class','embark_town']
pd.get_dummies(df, columns=category)
categoryという変数に「sex」「class」「embark_town」を格納し、columnsというパラメータに指定します
それぞれ列が追加され、「0」か「1」に変換されます
全てのカテゴリ変数を一度に変換するには、columnsを指定する必要はありません
データ(DataFrame)に対してget_dummiesを実施すると、自動的にカテゴリ変数を判断し、列が追加されます
pd.get_dummies(df)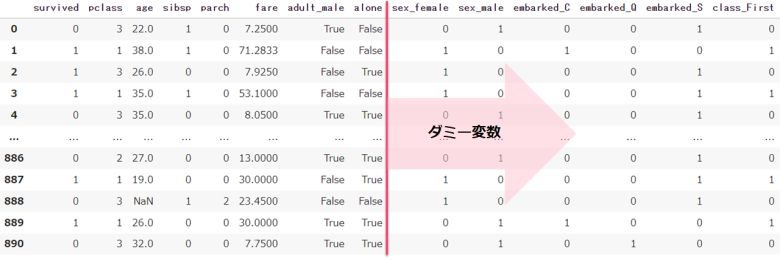
注意事項① 変数に格納する
get_dummiesで取り出される情報は中身が変換されないため、変数として新たに格納する必要があります
df_dummies = pd.get_dummies(df)注意事項② データが増える
「one-hot encoding」の欠点は、カテゴリ変数の数に応じて列(特徴値)が増えてしまう点です
特にカテゴリ変数の中身が多い場合は、そのまま列の数になることでほとんどが「0」のデータが生成されてしまいます
その結果、機械学習のモデル学習に時間がかかりすぎたり、メモリが大きく増えてしまうことが考えられます
タイタニック号のデータを単純にダミー変数化した場合、どのくらいデータが増えるか検証してみます
df_dummies = pd.get_dummies(df)
print(df.shape)
print(df_dummies.shape)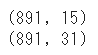
行数はもちろん変化なしですが、列数が「15」から「31」に変わるため単純に2倍のデータ量になります
今回のデータには入っていないですが、量が多くなりがちな「名前」などは注意が必要です
下記の図は「name」というたった1列が、get_dummiesによって「306」列になった結果です
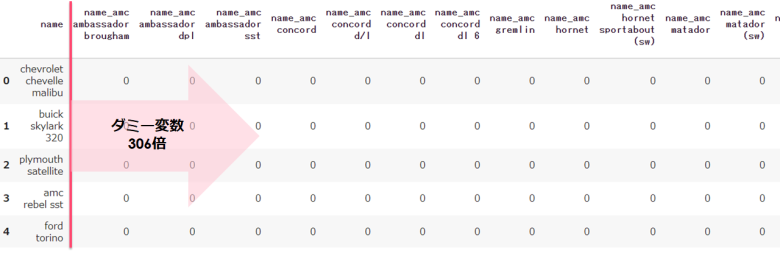
注意点③ 多重共線性を防ぐdrop_first
drop_firstを「True」で設定することで、最初の項目を削除してダミー変数を作成することができます
回帰分析でうまくいかない原因として有名な、多重共線性を防ぐことができます
多重共線性とは、変数同士で拘束関係が成り立ってしまう状態で、例えば「A」「B」「C」の3つのカテゴリーしかないデータの場合、「B」と「C」が0であれば必ず「A」が1で成り立ってしまう状態を指します
category = ['embark_town']
pd.get_dummies(df, columns=category, drop_first=True)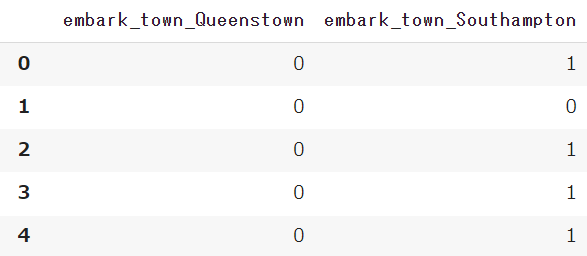
3つあるはずのembark_townのダミー変数が2列のみになっています
label encoding
「label encoding」の変換ではカテゴリ変数の内容がいくつあっても1つの列で収まるため、
「one-hot encoding」の欠点であったデータ量の増加を防ぐことができます
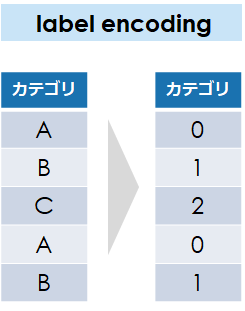
「label encoding」は列の中身を辞書順に並び替えた順で、「0」から始まる整数に置き換えます
もし列の中に「A」「B」「C」の3種類だけの場合、それぞれ「0」「1」「2」で変換されます
LableEncoderの利用
sklearnのLabelEncoderを利用することで変換を実施することができます
※改めて出航地だけのカテゴリ変数を用意します
df_town = pd.DataFrame(df['embark_town'])
df_town.head(6)LabelEncoderを利用するには、まず変数(le)を作成します
その変数(le)に対して、fitで対象のデータを読み込んだ後、transformで変換を実施します
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df_town)
df_town['変換後'] = le.transform(df_town)
df_town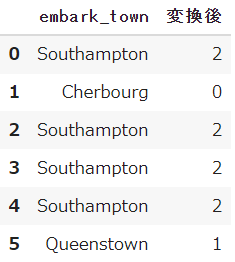
複数の列を変換する
LabelEncoderを利用して複数の列を変換するには、カテゴリ変数の数だけループして変換を実施します
タイタニック号のデータには9個のカテゴリ変数が存在しているため、その分だけループさせて変換をしていきます
変数(category)にカテゴリ変数名を格納しておきます
そしてforを利用して変換を実施していきましょう
category = ['sex','embarked','class','who','adult_male','deck','embark_town','alive','alone']
for c in category:
le = LabelEncoder()
le.fit(df[c])
df[c] = le.transform(df[c])
df.head()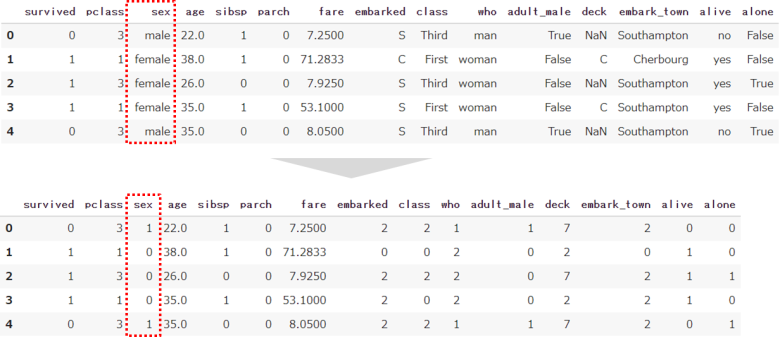
データ数を変えることなく、カテゴリ変数を数値変数に変換することができました
forの繰り返し処理に関してはこちらのサイトで解説されているため、ぜひご覧ください
 【Python】for文をイメージ図で完全解説|超分かる!繰り返し処理
【Python】for文をイメージ図で完全解説|超分かる!繰り返し処理
注意事項 決定木以外は使わない
「label encoding」はデータ量が増えないメリットがある代わりに、機械学習のモデル選びで注意が必要です
カテゴリ変数を数値変数に変換しても、その数値変数には「数値的な意味」がありません
例えば「A~E」のカテゴリ変数を、「0~4」の数値変数に変換したとしても
「E:4」が「B:1」の4倍大きいわけではありません
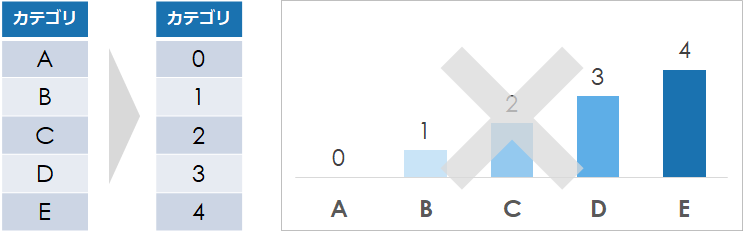
機械学習において「決定木」をベースにした手法以外では、正確ではないモデルが出来上がる可能性があります
一方で「決定木」や「ランダムフォレスト」といった手法では、
数値変数も分岐を繰り返して予測値に反映できるため、学習に用いることが可能です
コンペなどでよく利用されているGBDTにおいても、「label encoding」はよく利用されています
まとめ
今回はPythonで「カテゴリ変数」を「数値変数」に変換する方法をご紹介してきました
2種類の方法がありますが、メリット・デメリットを踏まえたうえでご利用ください
get_dummiesとLabelEncoderの両方とも、簡単に実施することができるためぜひ覚えてください


