 Smart-Hint
Smart-Hint 
目次
項目をまとめて集計する
今回はgroupby(グループ・バイ)を用いて、特定の項目ごとに集計する方法をご紹介します
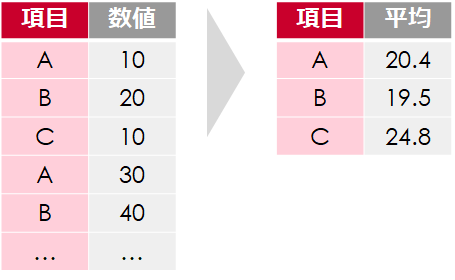
集計とは「合計」や「平均」、「最大・最小」などのことで、様々なデータ分析に活用されています
調べたい項目を指定するだけで、簡単に集約を実施することができます
事前準備
Seabornというライブラリから、タイタニック号のデータを取得しておきます
import seaborn as sns
df = sns.load_dataset('titanic')
df.head()
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介します
groupbyの使い方
groupbyはDataFrameに対して実施するメソッドで、引数に列名を渡すことで集約したい項目を指定することができます
まずはタイタニック号の生存を意味する「survived」を中心に、groupbyを実施します
df.groupby('survived')
このままだと何を出てこないため、集約に必要な関数を付けましょう
「合計」を算出するためにsumをつなげて記述します
df.groupby('survived').sum()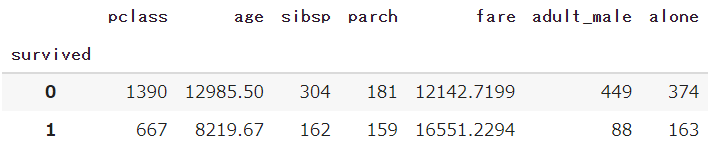
「生存した:1」と「死亡した:0」ごとに、旅客クラスや年齢の合計値を算出することができました
特に指定が無い場合は「算出できるすべての値」が計算されて出てきます
様々な集約関数
groupbyとセットで利用することが多い、集約関数をリストアップします
- sum():合計
- mean():平均
- max():最大値
- min():最小値
- count():データの個数
- std():標準偏差
- var():分散
タイタニック号のデータでは平均を使うことで、生存に関する要因を見つけ出すことができそうです
df.groupby('survived').mean()
複数の項目をまとめる
続いて2つ以上の項目に対してgroupbyを実施する方法をご紹介します
複数の項目を指定する場合は、[ ]リスト形式で並べて記述します
順番ごとにマルチインデックスで抽出されます
生存を意味する「survived」と、性別を表す「sex」の2つの項目で、平均を算出します
df.groupby(['survived','sex']).mean()![df.groupby(['survived','sex']).mean()](https://smart-hint.com/wp-content/uploads/2021/10/image-125.png)
2段のインデックスでそれぞれの平均値を算出することができました
すべての統計量を一度に算出する
最後にdescribeを用いて、統計量をすべて算出する方法をご紹介します
使い方に関しては別の記事でご紹介しているので、気になる方はご覧ください
 【Python】describe|全ての統計情報を一瞬で把握する方法
【Python】describe|全ての統計情報を一瞬で把握する方法
groupbyを使い「survived」の統計情報を一気に取得します
df.groupby('survived').describe()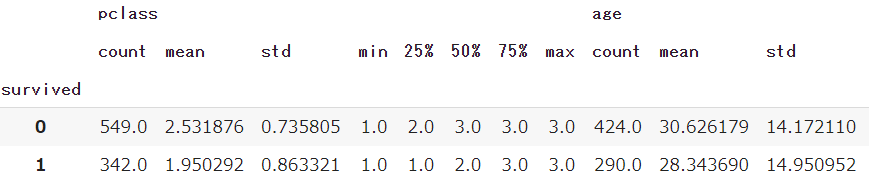
マルチカラム(複数列)となり、横に長いテーブルが出来上がってしまいました…
このままだと非常に見にくいため、stackを利用して行・列を入れ替えます
df.groupby('survived').describe().stack()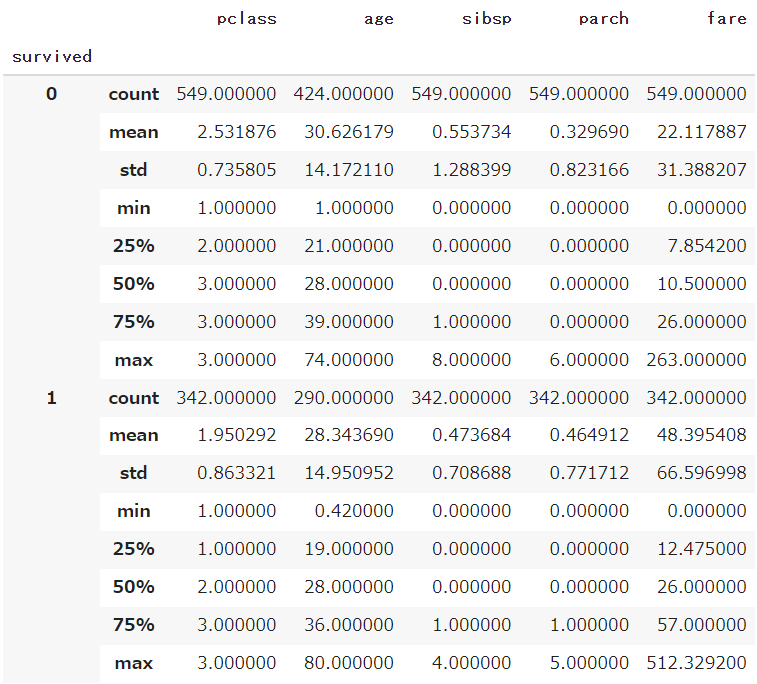
非常に分かりやすく、生存フラグごとに統計情報を算出することができました
まとめ
今回はgroupbyを利用して、項目ごとに集約を実施する方法をご紹介してきました
非常にシンプルなメソッドなので、ぜひ覚えて使ってみてください
また、さらに詳しく集計を操作するにはpivot_tableというメソッドも用意されているので、見てみてください
 【Python】Pythonピボットテーブルを完全攻略|pivot_table
【Python】Pythonピボットテーブルを完全攻略|pivot_table


