Smart-Hint
Smart-Hint 
目次
事前準備
「Pandas」というデータ解析を実施できるライブラリをインポートします
import pandas as pdサンプル:学校データ

student_data.head()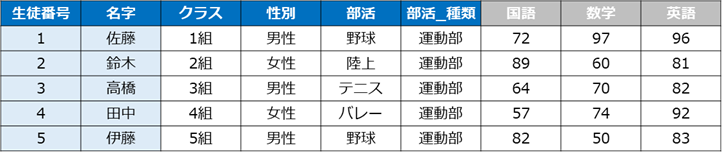
describeとは?
describe()を使うことで、DataFrameの統計情報を抽出することができます
データを読み込んだ後に、概要を把握するのに非常に便利なメソッドです
student_data.describe()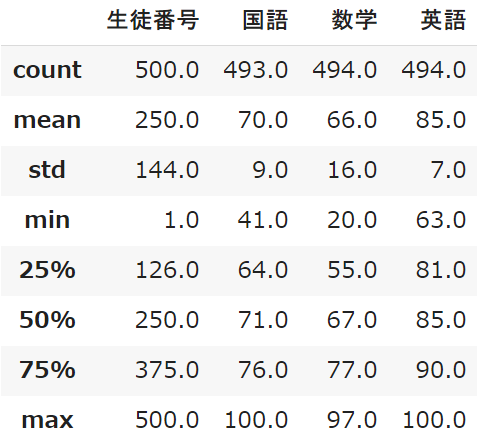
統計情報とは?
統計情報とは「平均や散らばり」などのデータを要約した情報を指します
この統計情報を把握することで、データ全体の構造を把握することができます
- 平均
- 標準偏差
- 最大値
- 最小値
- 四分位数
これらは基本的な統計情報ですが、統計が苦手な方にはアレルギーが出るかもしれません…
なるべく身近な用語で説明するために「学校データ」でご説明していきます
describeの使い方
describe()は()カッコの中を空欄でも、そのまま使えるメソッドです
指定する項目は非常に少ないですが、唯一注意すべき点は…
データ型が「数値データ」か「それ以外」かを把握すること
「それ以外」とは「文字列」や「日付」などのデータなどのこと
describe()では「数値データ」と「それ以外」で抽出される内容が変わります
1.2.3.4.5…のような「数値データ」は平均や標準偏差などを計算できます
一方で、それ以外の「文字列データ」などは平均、標準偏差を算出することができないため、ユニークな数や最頻値などの情報が抽出されます
include / excludeでデータ型を指定
英語の意味通り、「include」では抽出したいデータ型を指定し、「exclude」では抽出しないデータ型を指定します
※列名や列番号ではなく、「数値型」「文字列型」「日付型」などのデータ型を指定するので注意しましょう
もし指定がない場合は、「数値データ」のみ要約情報が抽出されます
当記事では「3パターン」に絞って指定方法をご紹介します
数値データ“のみ” = 何も指定しない ※デフォルト
数値データ“以外” = exclude = ‘number’
“全て”のデータ型 = include = ‘all’
student_data.describe() #数値データのみ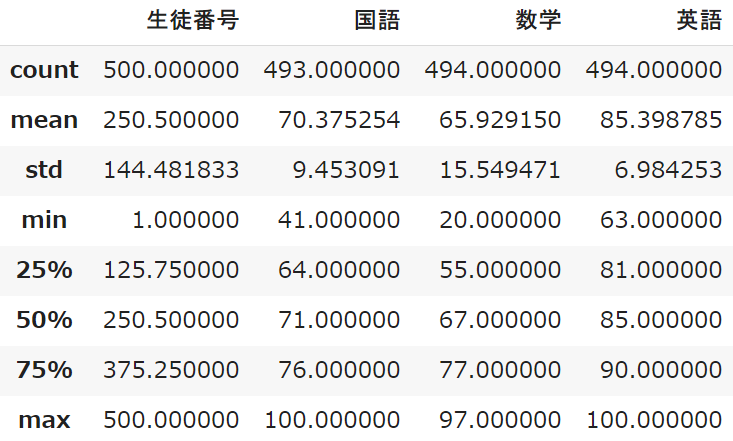
student_data.describe(exclude='number') #数値データ以外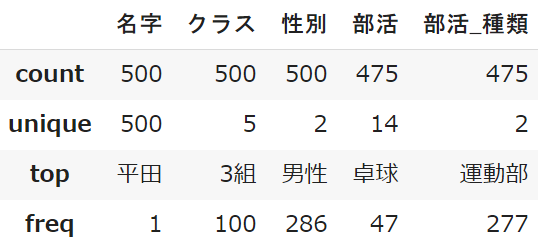
student_data.describe(include='all') #全てのデータ型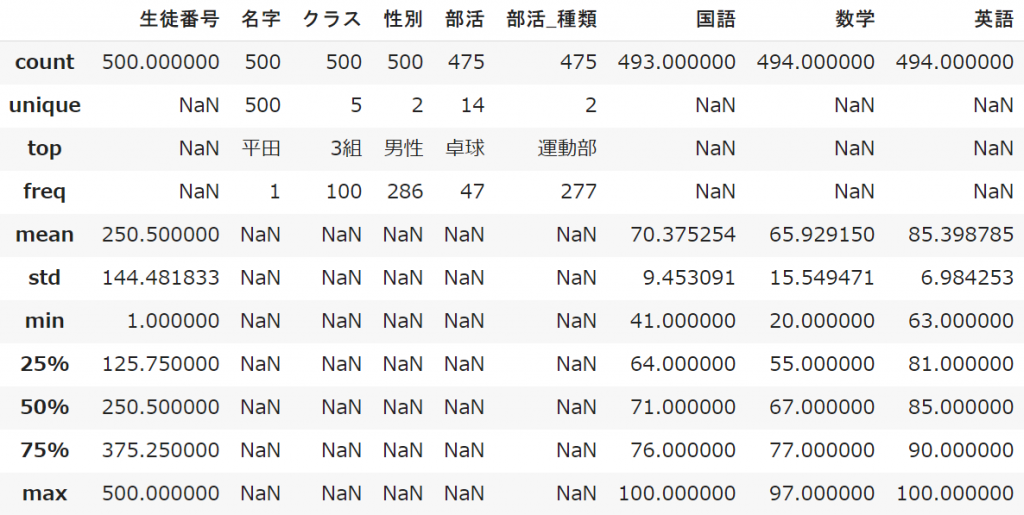
集約項目
前述の通り【数値データ】と【それ以外】では項目が異なります
数値データ:個数・平均・標準偏差・最小値・最大値・中央値・四分位数
それ以外:個数・ユニークな個数・最頻値・最頻値の頻度
count:個数
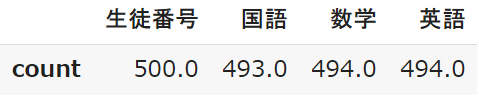
「count」はデータの個数を表します
「NULL」のデータは対象外となるため、生徒500名に対して6~7人はテストを受けていなことになりますね
mean:平均
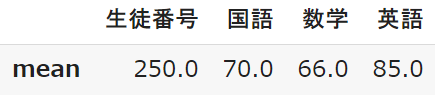
データ分析の際にとても重要になる「平均」です
平均は英語が高く、数学が低いことが分かります(難易度を表しますね)
std:標準偏差
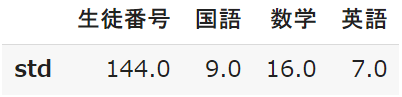
詳しい説明は避けますが、「標準偏差」はデータの散らばりを表します
数学が16.0で一番高いということは、点数が高い人も低い人も多いことになります
min:最小値
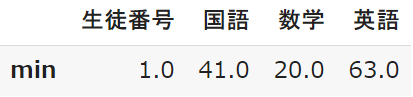
minは最小値で、テストの点数では最低点ということになります
max:最大値
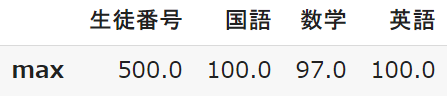
maxは最大値で、テストの点数では最高点ということになります
50%:中央値
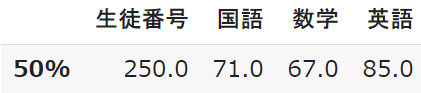
50%は「中央値」を意味しています
25% 75%:四分位数
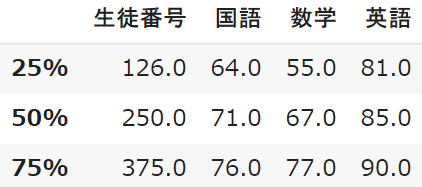
全体の1/4や3/4の数値を確認することができます
※区切るパーセントを設定する
デフォルトでは最小値から最大値までを4分割していますが、区切りを設定することができます
「percentiles」パーセンタイルというパラメータを設定します
「0~1」の数値をリスト型で記述します
percentiles=[0.2,0.4,0.6,0.8]
percentiles=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
student_data.describe(percentiles=[0.2,0.4,0.6,0.8])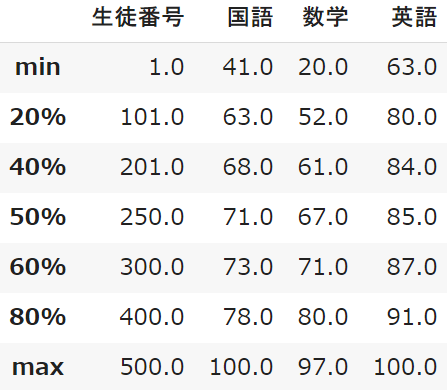
unique:ユニークな個数

ユニークとは「重複が無い」という意味で、同じ項目は数えない仕組みです
クラスは5クラスあり、男性・女性の2つの性別があることが分かります
top:最頻値

最も多い項目を出すのが「最頻値」です
注意点としては「米山」が「2組」で「男性」ということではなく、
クラスで多いのは「2組」で、それとは別に性別で多いのは「男性」ということです
freq:最頻値の頻度
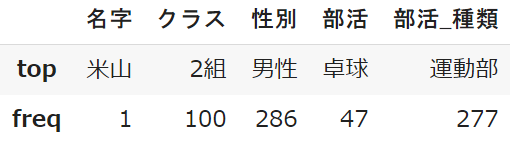
freqはtopと組み合わせて、最も多い項目がどのくらいあるのかを示します
性別の「男性」は286人いることを示しています
まとめ
今回は統計情報を一瞬で抽出するdescribe()関数をご紹介してきました
数値型以外でもぜひ使ってみてください