 Smart-Hint
Smart-Hint 
目次
ランダムにデータを抽出する
ランダムにデータを抽出するには、sampleという手法を利用します
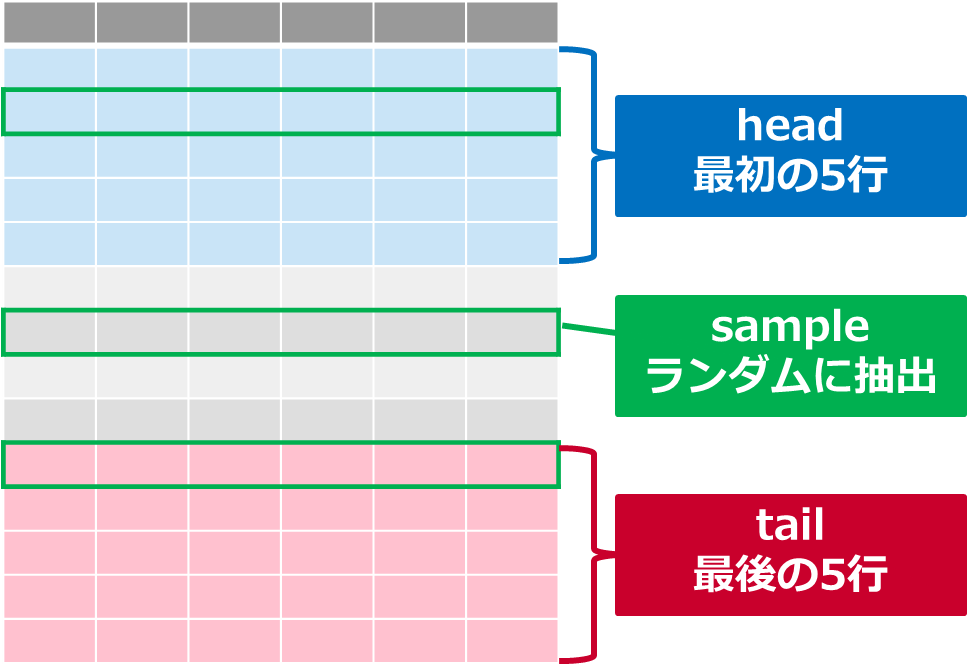
headは最初の5行を、tailは最後の5行を抽出するのに対し、sampleはランダムな行を取得します
事前準備
「Pandas」というデータ解析を実施できるライブラリをインポートします
import pandas as pdsampleの使い方
sampleを使うとデータをランダムに抽出することができます。
データ構造を見たいだけの時はheadやtailで十分ですが、
「散らばったデータが欲しい」ときに便利です
data = pd.read_excel('都道府県データ.xlsx')
data.sample()
sampleでパラメータを設定しないと、ランダムに1行目だけが抽出されます
詳細情報が欲しい場合はパラメータを設定しましょう
パラメータ
おすすめ度を判定:★★★=必須|★★☆=推奨|★☆☆=任意
★★☆:n(抽出する行数)
data.sample(1)前述した通り、sampleでは1行しか抽出されないため、headと合わせるには「5」を入力する必要があります
.sample():(ランダムに1行を抽出)
.sample(3):(ランダムに3行を抽出)
.sample(100):(ランダムに100行を抽出)
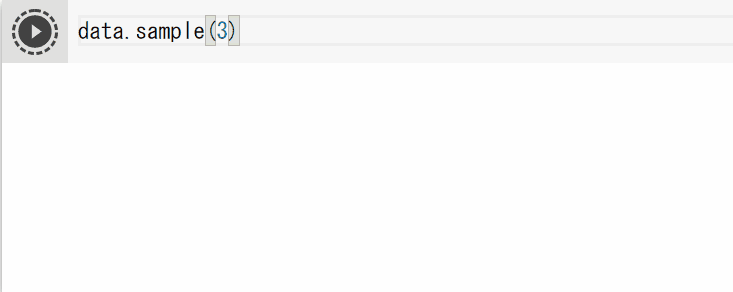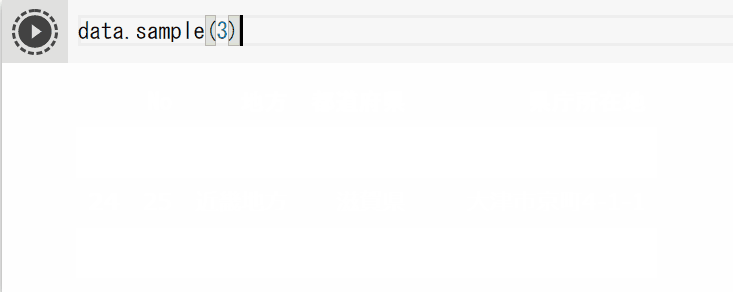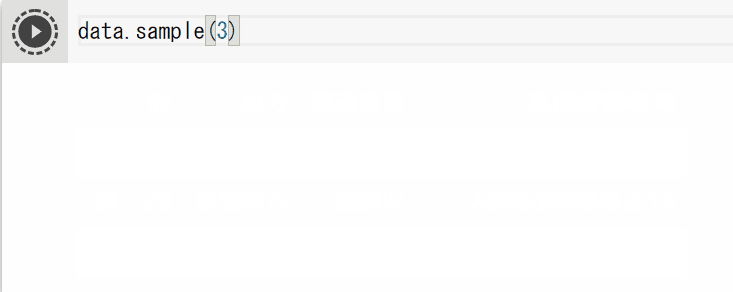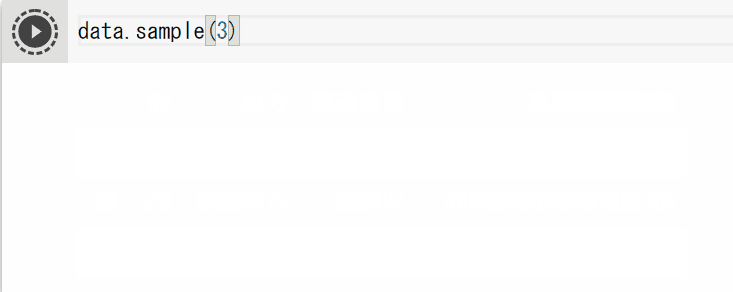
data.sample(3)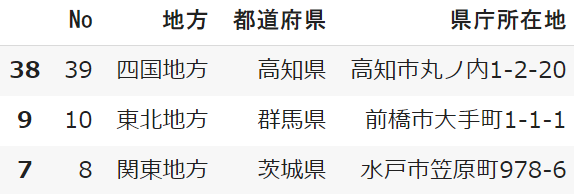
★★☆:frac(抽出する行数の割合)
data.sample(frac=0.3)ランダムに抽出する行数を、全体の割合という形で指定することができます
全体=1として「0~1」までの数値で記載します
※前述の「n」と両方使うことはできません
frac=0.1(全体の1割をランダムに抽出)
frac=0.3(全体の3割をランダムに抽出)
frac=0.8(全体の8割をランダムに抽出)
★☆☆:random_state(乱数を固定する)
data.sample(3, random_state=0)random_stateを設定することで、乱数を固定することができます
同じコードで同じ結果を再現したいときに使います
数値型であれば何を指定しても大丈夫です
★☆☆:axis(行・列どちらをランダムに抽出するか)
data.sample(3, axis=None)デフォルトでは行がランダムに抽出されますが、列もランダムに抽出することができます
axis=0(行をランダムに抽出)※デフォルト
axis=index(行をランダムに抽出)
axis=1(列をランダムに抽出)
axis=columns(列をランダムに抽出)
★☆☆:replace(重複行の許可)
data.sample(3, replace=False)デフォルトでは行と列が「重複が無いよう」に抽出されています(False)
「True」を設定すると同じ内容が含まれます
replace=False(重複なし)※デフォルト
replace=True(重複なし)
data.sample(5, replace=True)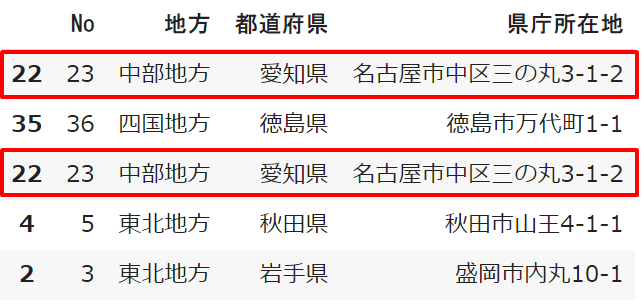
まとめ
今回はsample()の使い方についてご紹介してきました
似たような機能としてデータの最初の行を抽出するhead()や末尾の行を抽出するtail()があります
 【Python】headとtail|一部のデータを抽出してみる
【Python】headとtail|一部のデータを抽出してみる

