Smart-Hint
Smart-Hint 
目次
事前準備
「Pandas」というデータ解析を実施できるライブラリをインポートします
import pandas as pdheadは先頭、tailは末尾のデータを取ってくる

head()はその名の通りデータの先頭(最初)の5行が抽出されて、テーブルとして可視化されます
また tail()も英語の「尾」と同じ意味で、データの末尾(最後)の行が抽出されます
head()はデータ処理や分析を実施するとき、1番と言っていいほど利用する機能です
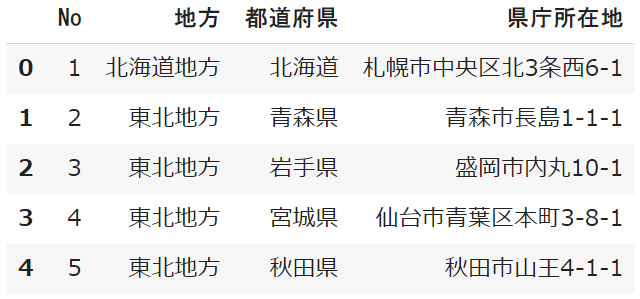
sample = pd.read_excel('サンプル.xlxs')
sample.head()- read_excel()でエクセルを読み、sampleという変数として格納
- head()でsampleに入っているデータの最初の行を抽出
初心者は毎回使おう!
Pythonでは変数の入力や集計をしても、アウトプットがすぐに見えません
初心者にとってこれほど「不安」なことはありません

何をしているか”分からない”
特にエクセルに慣れている方は、「コード」しか見えない状況に混乱してしまう可能性があります
ここで止まってしまう人が多いので、データ処理を行うたびに、head()を使って可視化することをお勧めします
集計処理のたびにデータを抽出する
head()のパラメータ
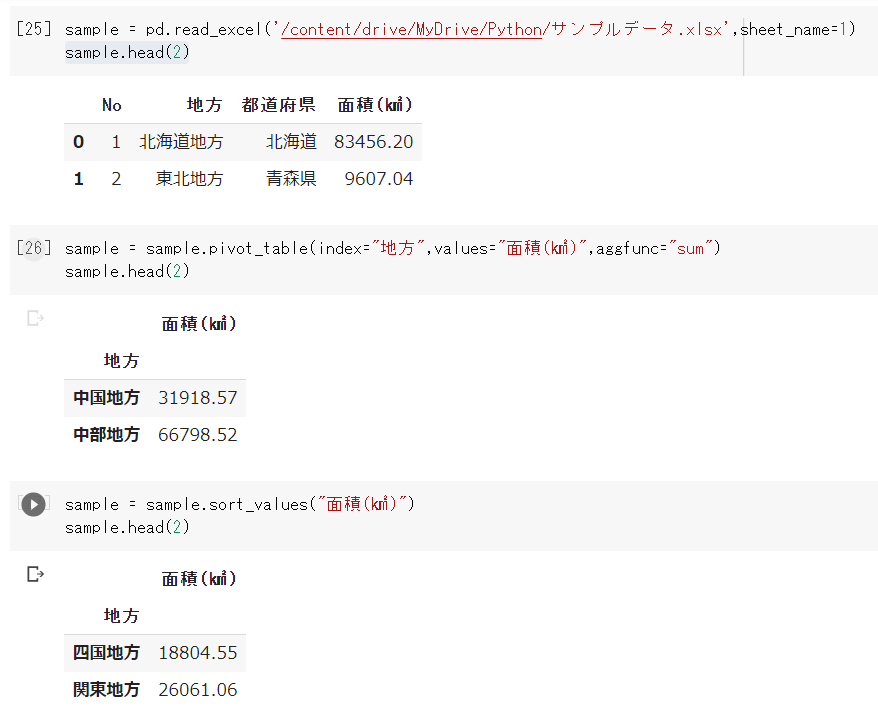
sample.head()基本的には()カッコの中には、何も入れなくても大丈夫です
デフォルトでは「上から5行」が取得され、可視化されます
()カッコの中に数字を入れれば、その分の行が抽出されます
.head():(上から5行を抽出)
.head(3):(上から3行を抽出)
.head(100):(上から100行を抽出)
.head(-5):(下から5行目以外を全て抽出)
sample.head(3)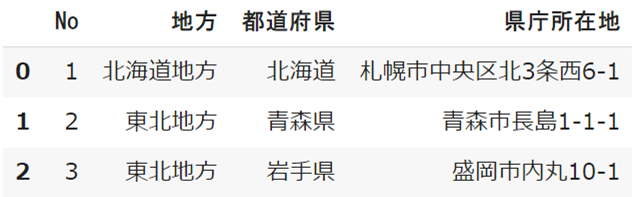
tail()のパラメータ
sample.tail()head()と同じで、()カッコの中にい何も入れないと下から5行が抽出されます
.tail():(下から5行を抽出)
.tail(3):(下から3行を抽出)
.tail(100):(下から100行を抽出)
.tail(-5):(上から5行目以外を全て抽出)
sample.tail(3)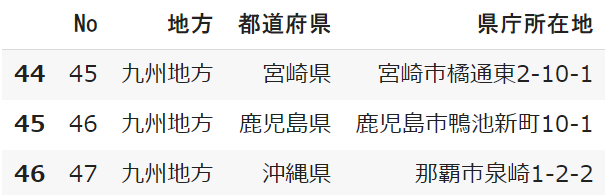
まとめ
今回はPythonでの基本操作であるhead()とtail()をご紹介してきました
初心者の方は、迷子になったらすぐにデータを可視化する癖をつけておきましょう
またランダムにデータを抽出したい場合はsample()を使いましょう
 【Python】sample|ランダムにデータを抽出する
【Python】sample|ランダムにデータを抽出する