

目次
事前準備
「Pandas」というデータ解析を実施できるライブラリをインポートします
import pandas as pdread_csvの使い方
read_csvはCSVファイル(.csv)をPythonに読み込むことができます
※Pandasの機能を使うために頭に「pd.」を付けましょう(事前準備でPandasをpdと名付けています)
pd.read_csv('/content/drive/MyDrive/python/ファイル名.csv')pd.read_csv('ファイル名.csv')CSVファイルが置いてあるファイルパス(もしくはファイル名)を指定することで、Pythonに読み込むことができます
またパラメータを指定することで、文字コードや区切り文字の指定、ヘッダーは必要かなども設定することができます
ちなみにTSVファイル(タブ区切り.tsv)のファイルも読み込むことができます
このようなCSVファイルを「Python」で読み込みます
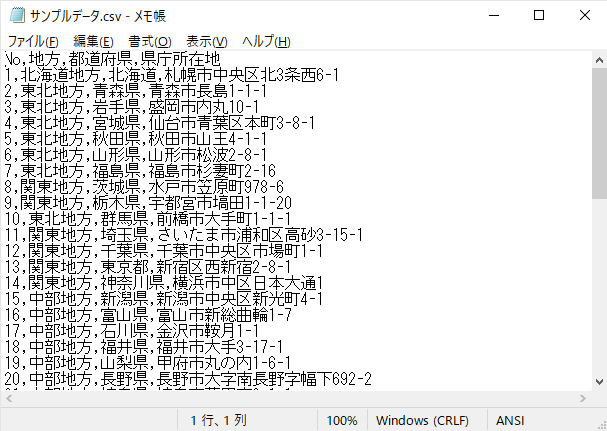
sample = pd.read_csv('ファイル名.csv')
sample.head()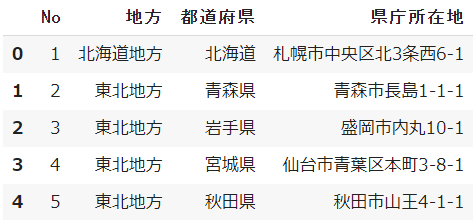
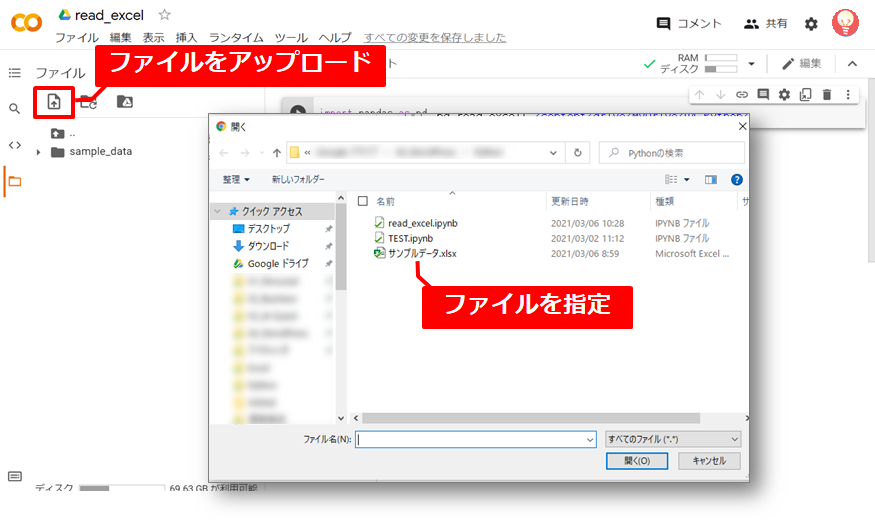
※Google Colaboratoryにファイルをアップロードする方法
※Google Driveと連携する方法
 【Python】Google ColaboratoryとGoogle Driveを連携する方法
【Python】Google ColaboratoryとGoogle Driveを連携する方法 パラメータ
おすすめ度を判定:★★★=必須|★★☆=推奨|★☆☆=任意
★★★:ファイルパス/ファイル名
pd.read_csv('ファイル名.csv')
pd.read_csv('/content/drive/MyDrive/python/ファイル名.csv')「”」シングルクォーテーションか「””」ダブルクォーテーションを付けて
ファイル名やファイルパスを記載します
拡張子(.csvなど)を忘れずに記載してください
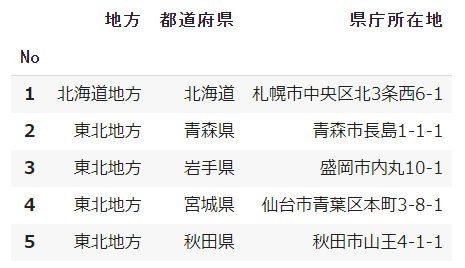
★★☆:index_col(インデックス/先頭列)
pd.read_csv('ファイル名.csv', index_col=None)インデックスを指定します
何も設定しないと自動的にインデックスが作成されます(0始まりの連番)
- index_col = None(0始まりの連番が作成される)※デフォルト
- index_col = 0(1列目がインデックスになる)
- index_col = 1(2列目がインデックスになる)
- index_col = 1, 2(2,3列目がマルチインデックスになる)
初期設定ではインデックスが自動的に設定されてしまうため、
「index_col = 0」の設定を推奨します
★★☆:encoding(文字コード)
pd.read_csv('ファイル名.csv', encoding = utf-8)CSVでは文字コードというのが設定されていて、Pythonで読み込むためにはその種類を指定する必要があります
エクセルを読み込む際には無い指定方法なので、気をつけてください
初期設定は「utf-8」になっていて、違う文字コードのCSVを読み込もうとした場合は
このようなエラーが出てしまいます
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x92 in position 0: invalid start byte
- encoding = ‘utf-8’ ※デフォルト
- encoding = ‘shift-jis’
もちろんCSV側で文字コードを変更することも可能です
★★☆:sep(区切り文字)
pd.read_csv('ファイル名.csv', sep=',')CSVとは「Comma Separated Value」の略で(,)カンマで区切られたファイルのことです
テキストファイルで見ると、図のようにカンマ出区切られているのが分かります
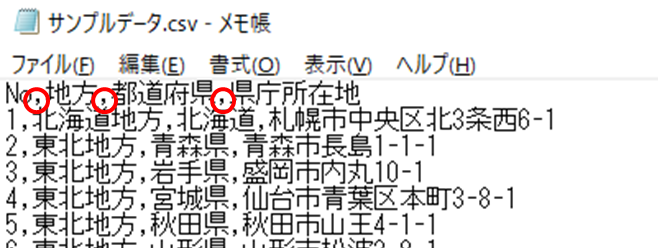
read_csvではデフォルトが(,)カンマ区切りになっているので、特に指定は必要ありません
もし「TSV」ファイルを読み込みたい場合は「タブ」を表す「\t」を指定します
- sep = ‘,’(カンマ区切り・CSV)※デフォルト
- sep = ‘\t’(タブ区切り・TSV)
★☆☆:header(ヘッダー/先頭行)
pd.read_csv('ファイル名.csv', header=0)ヘッダーの位置を指定します
何も設定しないと1行目がヘッダーになります
- header = 0(1行目がヘッダーになる)※デフォルト
- header = 1(2行目がヘッダーになる)
- header = 1, 2(1,2行目がマルチカラムとしてヘッダーになる)
- header = None(ヘッダー無し、0からの連番)
CSVファイルにはヘッダーが無い、いわゆる「データだけ」の形式の場合があります

もしヘッダーが無い場合は、「names」のパラメータを指定しましょう
★☆☆:names(カラム名を付ける)
pd.read_csv('ファイル名.csv', names={'A','B','C'})その名の通りカラム名を自分で設定することができます
ヘッダーが無いCSVファイルの場合、「names」でカラム名を指定します
ヘッダーが既にあり、カラム名を指定したい場合は、「header=0」を明示する必要があります(ヘッダーは1行目だけど、名前を変えるよ!という指令)
- names = {‘A’,’B’,’C’}(カラム名がA,B,Cになる)
- names = {‘No’,’地方’,’都道府県’,’県庁所在地’}(カラム名が指定のカラム名になる)
pd.read_csv('サンプルデータ.csv', header=0, names={'A','B','C')
★☆☆:usecols(使う列)
pd.read_csv('ファイル名.csv', usecols=None)使う列をパラメータで指定することができます
- usecols = None(すべての列)※デフォルト
- usecols = [1](2列目のみ)※一列でも[]リストを使う
- usecols = [1, 2, 3](2,3,4列)
- usecols = [‘都道府県’](都道府県というカラムのみ)
- usecols = [‘都道府県’,’地方’](都道府県と地方というカラムのみ)
★☆☆:skiprows(読み込まない行)
pd.read_csv('ファイル名.csv', skiprows=1)読み込まない行を選択します(※読み込まない設定なので注意!)
- skiprows = 2(先頭から2行を読み込まない)
- skiprows = [2, 4](2,4行目を読み込まない)
★☆☆:skipfooter(読み込まない最後の行)
pd.read_csv('ファイル名.csv', skipfooter=1)「skiprows」と似たようなパラメータですが、最後の行(フッター)で読み込まない行を指定できます
例えば最終行に「集計」がある場合があったりします
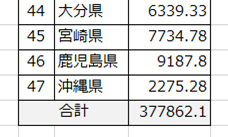
Pythonでこのまま集計してしまうと、この「合計欄」まで計算してしまいます…
- skiprows = 1(最後から1行を読み込まない)
まとめ
今回は「CSV」をPythonで読み込む方法をご紹介してきました。
エクセルを読み込む方法もあるのでご覧ください



いつもお世話になっております。
業務で活用させていただきました。
パラメータの優先順位が分かりやすいですね!