 Smart-Hint
Smart-Hint 
目次
PythonでWikipediaのテーブルを取得する方法
PythonのPandasを利用して、Wikipedia上のテーブルをDataFrameに格納する方法をご紹介します
Wikipediaには非常に有用な情報が存在しており、データ分析にも活用することができます
特に今回はWikipedia上の「テーブル」に限ってデータを取得していきます
Wikipedia APIを利用すればテーブル以外の情報も取得が可能ですが、
本記事ではより難易度の低いread_htmlを利用したデータ取得の方法について言及します
事前準備
データ加工のためPandasもインポートしておきましょう
import pandas as pdデータ取得方法
Wikipediaのテーブルを取得するにはread_htmlという手法を利用します
read_excelやread_csvと似たようなメソッドです
この手法はWikipedia専用の手法ではないため、他のサイトでも同様にテーブルを取得することが可能です
 【Python】read_excel|エクセルをPythonに読み込む方法
【Python】read_excel|エクセルをPythonに読み込む方法
 【Python】read_csv|CSVファイルをPythonに読み込む方法
【Python】read_csv|CSVファイルをPythonに読み込む方法
URLを指定しデータを全て取得する
対象となるurlを設定して、read_htmlで読み取ります
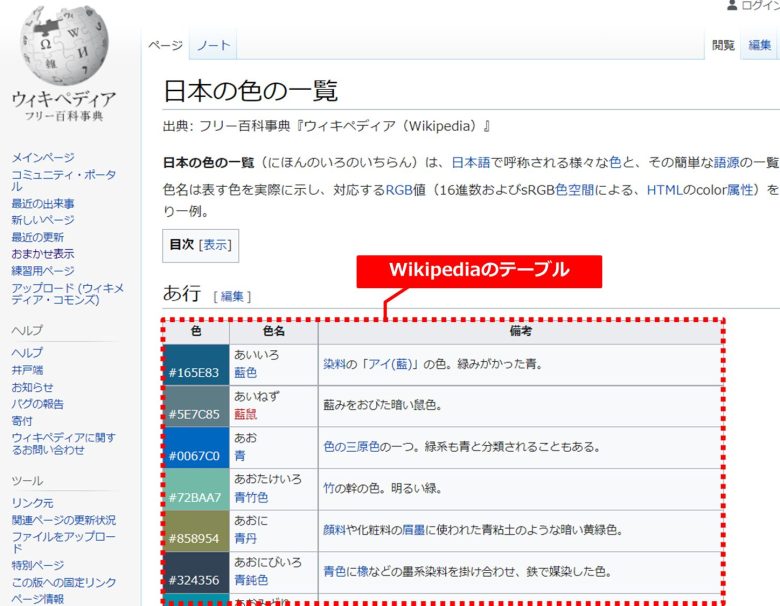
今回は事例として「日本の色の一覧」のデータを取得してみます
※URLが日本語のためエンコード(%E6%97…)されています
url = 'https://ja.wikipedia.org/wiki/%E6%97%A5%E6%9C%AC%E3%81%AE%E8%89%B2%E3%81%AE%E4%B8%80%E8%A6%A7'
dfs = pd.read_html(url)
print(dfs)
実はこのままだと対象のWikipediaに存在するすべてのテーブルがDataFrameに格納されます
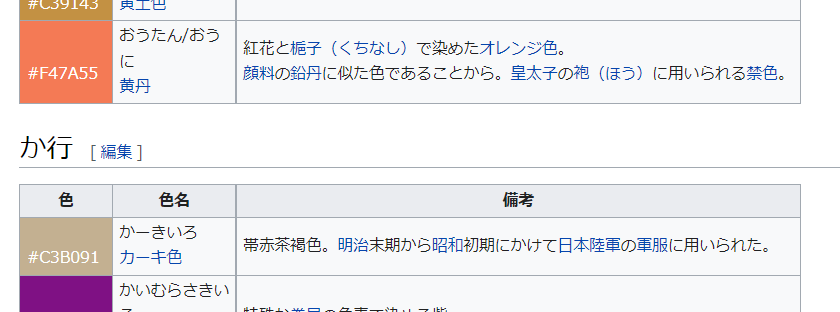
「日本の色の一覧」のデータには「あ」~「わ」まで「行」ごとにテーブルが分かれています
複数のテーブルが入っている変数(dfs)に対して、lenを使ってテーブル数を数えます
len(dfs)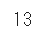
結果的に13個のテーブルが格納されていました
「あ」~「わ」までの10行のテーブルと、関連項目の3つのテーブルが取り出されていました
必要なテーブルのみ取得する
「日本の色の一覧」のデータには不要な3つのテーブルがあることが判明したため、色の情報のみテーブルを取得します
matchというパラメータを利用すれば、指定した文言が含まれているテーブルのみ取得できます
色のテーブルのみに含まれる「#」を指定して、行数を数えてみます
dfs = pd.read_html(url, match='#')
len(dfs)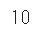
テーブルを指定して表示させる
複数のテーブルが格納された変数(dfs)から、最初の「あ」行のDataFrameを表示させます
変数に続けて[ ]を付けることで、単一のDataFrameを取り出すことができます
dfs[0]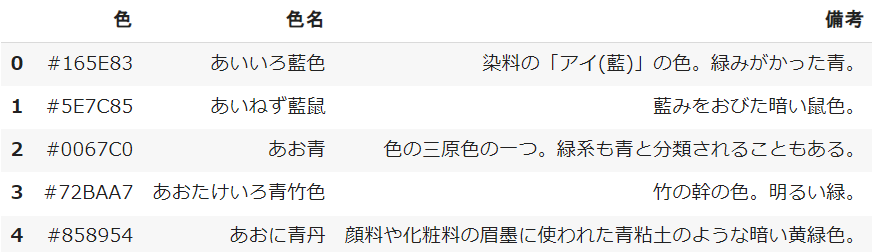
複数のテーブルを結合する
同じ形式のテーブルが分かれている場合、forの繰り返し処理を利用して結合していく必要があります
rangeの中に変数(dfs)のテーブル数を入れることで「あ」~「わ」までの10テーブルを繰り返すことができます
事前に用意している変数(df)にappendでそれぞれ結合していきます
※ignore_indexをTrueで設定することで、統一のインデックスを作成できます
url = 'https://ja.wikipedia.org/wiki/%E6%97%A5%E6%9C%AC%E3%81%AE%E8%89%B2%E3%81%AE%E4%B8%80%E8%A6%A7'
dfs = pd.read_html(url, match='#')
df = pd.DataFrame()
for i in range(len(dfs)):
df = df.append(dfs[i], ignore_index=True)
df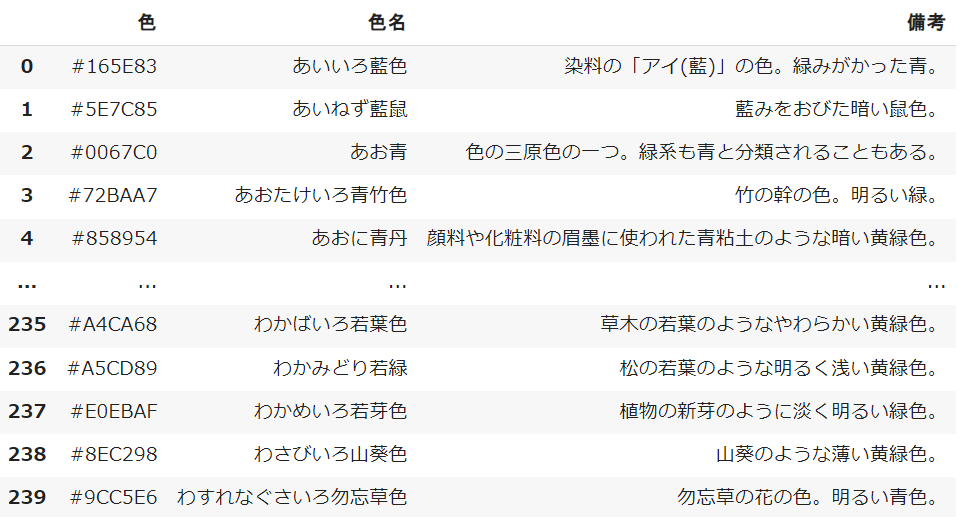
 【Python】for文をイメージ図で完全解説|超分かる!繰り返し処理
【Python】for文をイメージ図で完全解説|超分かる!繰り返し処理
他のWikipediaテーブル
「2020 Summer Olympics」東京オリンピック(2020)の金メダルのデータを取得します
url = 'https://en.wikipedia.org/wiki/2020_Summer_Olympics'
dfs = pd.read_html(url, match='Gold')
dfs[0].head(10).style.background_gradient(cmap='Oranges')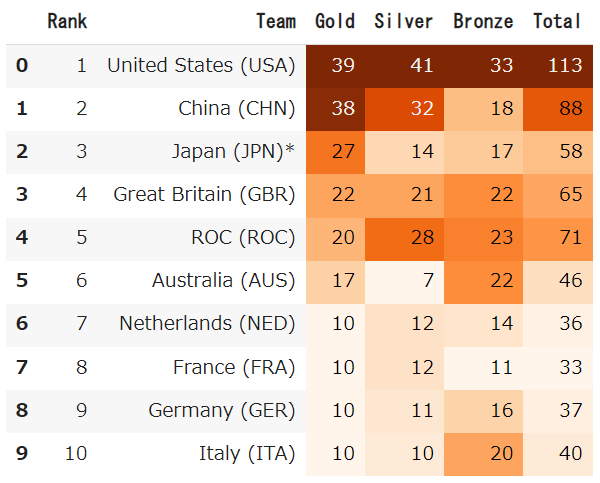
olympic2020 = dfs[0].head(10).sort_values('Total')
olympic2020 = olympic2020.set_index('Team')[['Gold','Silver','Bronze']]
olympic2020.plot.barh(stacked=True
,color=('gold','silver','orange'))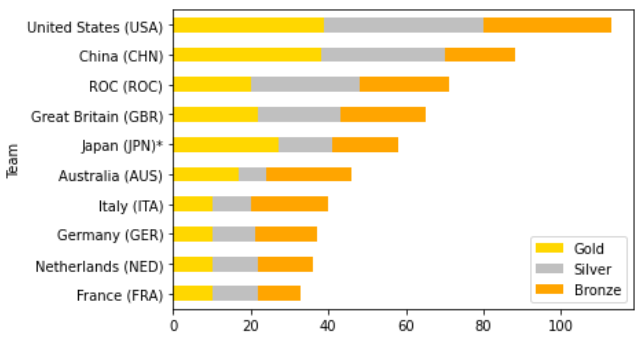
エラーが出る場合の対応
利用されている環境によってはread_htmlでエラーが発生する可能性があります
その場合は下記コードを記入し再実行を試してみてください
import ssl
ssl._create_default_https_context = ssl._create_unverified_contextまとめ
今回はPythonでWikipediaのテーブルを取得する方法をご紹介しました
read_htmlはあくまでもWeb上のテーブルを取得する方法なので、Wikipedia以外でも活用できます
マスターデータとしてWikipediaからデータテーブルを取得することはよくあるので、ぜひ使ってみてください


