目次
Pythonで対応分析(コレスポンデンス分析)を実施する
今回はPythonを使って対応分析(コレスポンデンス分析)を実施する方法を分かりやすくご紹介します
そもそも対応分析(コレスポンデンス分析)とは、多変量解析法の一つでデータを理解しやすいように加工・可視化する分析手法です
クロス集計表など、行と列からなるデータの特徴をグラフ化することによって、項目間の関係を視覚的に把握することができます
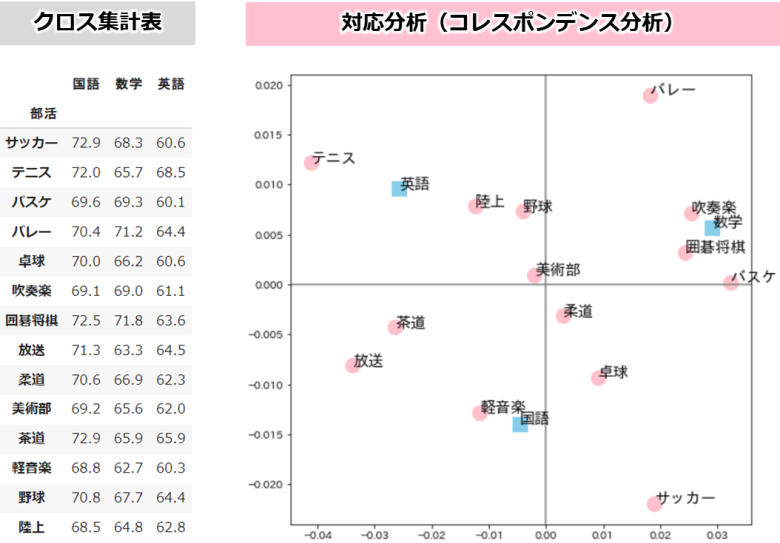
今回の記事は対応分析の説明ではなく、Pythonを使ったデータの加工や可視化をご説明します
詳しい定義に関してはこちらのサイトで説明されているのでご覧ください
 対応分析(コレスポンデンス分析)を徹底解説
対応分析(コレスポンデンス分析)を徹底解説 事前準備
Seabornというライブラリから、タイタニック号のデータを取得しておきます
また加工のためにPandasと対応分析のためにmcaも合わせてインポートしておきます
import seaborn as sns
import pandas as pd
! pip install mca
import mca
import matplotlib.pyplot as plt
df = sns.load_dataset('titanic')
df.head()
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介します 対応分析のためのデータ加工
それではPythonで対応分析を実施する方法を、順を追って説明していきます
事例として「タイタニック号」のデータを活用しますが、お手元の調査データでも同様の処理ができるので試してみてください
下記3ステップで調査を実施していきます
- 元データからクロス集計表を作成
- mcaを利用してデータを加工
- matplotlibを利用してデータを可視化
① 元データからクロス集計表を作成
まずは元のデータ(タイタニック号)からクロス集計表を作成します
今回は乗船していたデッキdeckと、性別・子供を示すwhoの2つの項目の個数でテーブルを作成します
平均や合計を集計する場合はpivot_tableを利用し、個数を集計する場合はcrosstabを利用しましょう
df_mca = df.pivot_table(index='deck',
columns='who',
values='survived',
aggfunc='count')
df_mcapd.crosstab(df['deck'],df['who'])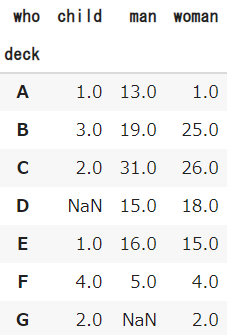
 【Python】Pythonピボットテーブルを完全攻略|pivot_table
【Python】Pythonピボットテーブルを完全攻略|pivot_table  【Python】crosstab|カテゴリーごとの出現回数を算出する
【Python】crosstab|カテゴリーごとの出現回数を算出する 欠損値nullがある場合はfillnaを利用して補完して下さい
今回利用する手法は欠損値を読み取れないため、「0」で代替するか、平均などを入れましょう
df_mca = df_mca.fillna(0)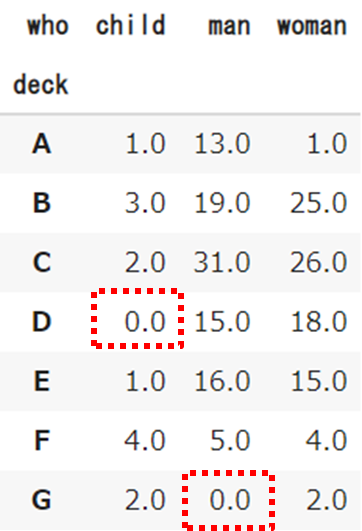
 【Python】欠損値の扱い方大全
【Python】欠損値の扱い方大全② mcaを利用してデータを加工
続いてmcaを利用してクロス集計表のデータを加工します
エラーが出ないようにbenzecriのパラメータをFalseで設定します
細かいロジックは省略しますが、行と列を2次元のリストを取得します
変数名を(df_mca)で設定していますが、ここはご自由に変えてください
mca_counts = mca.MCA(df_mca, benzecri=False)
rows = mca_counts.fs_r(N=2)
cols = mca_counts.fs_c(N=2)③ matplotlibを利用してデータを可視化
最後にmatplotlibの散布図を利用して、データを可視化します
# グラフサイズの設定
fig, ax=plt.subplots(figsize=(8,8))
# インデックスの処理
ax.scatter(rows[:,0], rows[:,1], c='pink', marker='o', s=200)
labels = df_mca.index.values
for label,x,y in zip(labels,rows[:,0],rows[:,1]):
ax.annotate(label,xy = (x, y),fontsize=15)
# カラムの処理
ax.scatter(cols[:,0], cols[:,1], c='skyblue', marker='s', s=200)
labels = df_mca.columns.values
for label,x,y in zip(labels,cols[:,0],cols[:,1]):
ax.annotate(label,xy = (x, y),fontsize=15)
# 原点(0,0)を引く
ax.axhline(0, color='gray')
ax.axvline(0, color='gray')
plt.show()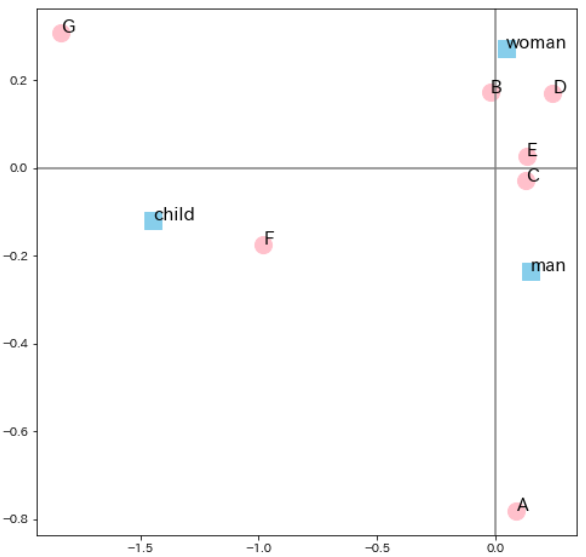
ax.scatterのパラメータを調整することで、散布図のプロットの色や形を変更することができます
- c = ‘pink’(色)
- marker = ‘o’(マーカーの形)
- s = 200(マーカーの大きさ)
まとめ
今回はPythonを利用して対応分析(コレスポンデンス分析)を実施する方法をご紹介しました
mcaを使うと簡単に分析を実施することができるため、ぜひ試してみてください
対応分析(コレスポンデンス分析)を徹底解説