

目次
機械学習の評価指標を算出する
機械学習の分類における評価指標を、sklearnを使い算出する方法をご紹介します
機械学習の分類モデルには二値分類(0 / 1)を予測する場合と、正である場合の確立(0.85等)を予測する場合があります
今回は前者の「0」か「1」を予測するモデルを評価する指標を算出します
- 混同行列(Confusion Matrix)
- 正解率(Accuracy)
- 適合率(Precision)
- 再現率(Recall)
- F値(F-measure)
そもそも評価指標の定義については下記サイトで解説しているのでご参照ください。
 【機械学習】分類の評価指標を一番分かりやすく解説|confusion-matrix
【機械学習】分類の評価指標を一番分かりやすく解説|confusion-matrix 事前準備
目的変数のテスト用データ(正解データ)y_testと、モデルで予測したデータy_predを用意します
※機械学習を想定して、慣例的に使われている変数にしています
今回は分類タスクの中でも、「0」か「1」を予測するため確率ではなく整数を準備します
y_test = [1,1,1,1,1,0,0,0,0,0]
y_pred = [1,0,1,1,1,1,0,1,0,1]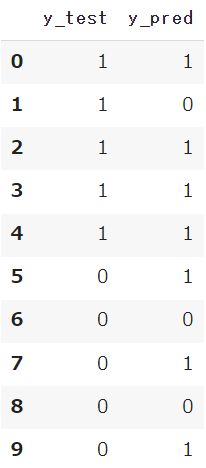
混同行列(Confusion Matrix)
まずは「実際」のPositive / Negativeと、「予測」のPositive / Negativeを4象限に分けた混同行列(Confusion Matrix)を作成します

sklearn.metricsからconfusion_matrixをインポートします
事前準備で用意した実際の値(y_test)と予測値(y_pred)を代入します
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred)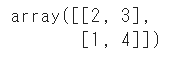
0(Negative)から1(Positive)の順で並んだ、混同行列が算出されます
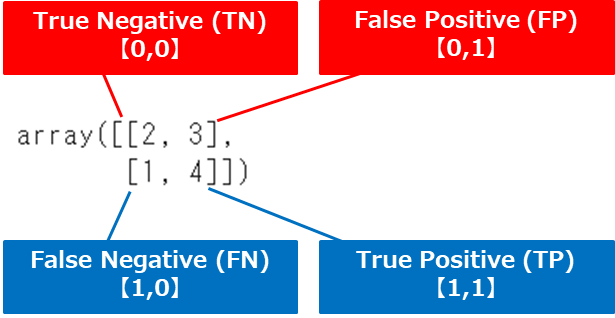
このままだと分かりにくいので、seabornを使ってヒートマップを作成しましょう
混同行列のヒートマップ
seabornのheatmapを利用すれば、数値の大小をカラーリングで表現することができます
import seaborn as sns
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True)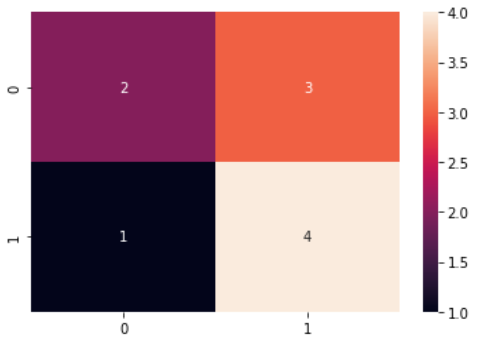
seabornの詳しい使い方については下記をご覧ください
 【Python】seabornで綺麗なグラフ作成を!たった1行で書けます
【Python】seabornで綺麗なグラフ作成を!たった1行で書けます 正解率(Accuracy)

from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)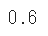
accuracy_scoreをインポートして、実際の値と予測値を代入すると正解率を算出することができます
適合率(Precision)

from sklearn.metrics import precision_score
precision_score(y_test, y_pred)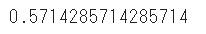
precision_scoreをインポートして、実際の値と予測値を代入すると適合率を算出することができます
再現率(Recall)

from sklearn.metrics import recall_score
recall_score(y_test, y_pred)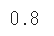
recall_scoreをインポートして、実際の値と予測値を代入すると再現率を算出することができます
F値(F-measure)

from sklearn.metrics import f1_score
f1_score(y_test, y_pred)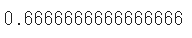
f1_scoreをインポートして、実際の値と予測値を代入するとF値(F-measure)を算出することができます
まとめ
今回は機械学習の分類における評価指標を、sklearnを使って算出する方法をご紹介してきました
単純に2つのリストを代入するだけでスコアを算出することが可能です
指標のイメージについては、グラフィックを用いて分かりやすく解説しているのでぜひご覧ください
【機械学習】分類の評価指標を一番分かりやすく解説|confusion-matrix 

