
目次
勾配ブースティング木とは?
勾配ブースティング木(GBDT)は機械学習の手法の一つで、「使いやすさ」と「精度の高さ」から実務やコンペでよく利用されます
英語ではGradient Boosting Decision Treeと呼ばれ、GBDTと略されます
名前の通り「決定木(Decision Tree)」を複数組み合わせる(アンサンブル)ことで予測を行います
「ランダムフォレスト」も似たような手法なので、ぜひこちらの記事を参考にしてください
 【機械学習】決定木のPython実践・可視化|Decision Tree
【機械学習】決定木のPython実践・可視化|Decision Tree  【機械学習】ランダムフォレストを分かりやすく解説|RandomForest
【機械学習】ランダムフォレストを分かりやすく解説|RandomForest 決定木を複数組み合わせる

勾配ブースティング木は「決定木」のモデルをアンサンブルします
アンサンブルとは「二人以上でする歌唱または演奏」を意味しており、機械学習ではモデルを複数使って予測を行うことを指します
複数のモデルが別々の予測を行う中で、最終的に予測を1つに絞るため「バギング」と「ブースティング」のどちらかを利用します
「ランダムフォレスト」はバギングを採用し、「勾配ブースティング木」はブースティング木を採用しています
- バギング:同じモデルを並列に並べ、平均や多数決で予測を実施
- ブースティング:同じモデルを直列に並べ、それまでの決定木の予測差分も学習に利用し予測を実施
ブースティングは単純に並列に並べるだけではなく、予測した結果をも学習に利用するためバギングより精度が高くなる傾向があります
つまり「ランダムフォレスト(バギング)」より「勾配ブースティング木(ブースティング)」の方が精度が高くなります
ランダムフォレストと勾配ブースティング木の違い
言葉で説明しても伝わりにくいため、イメージでそれぞれ説明していきます
シンプルな機械学習の予測として、1人の「女の子の身長」を予測するモデルを作っていきましょう

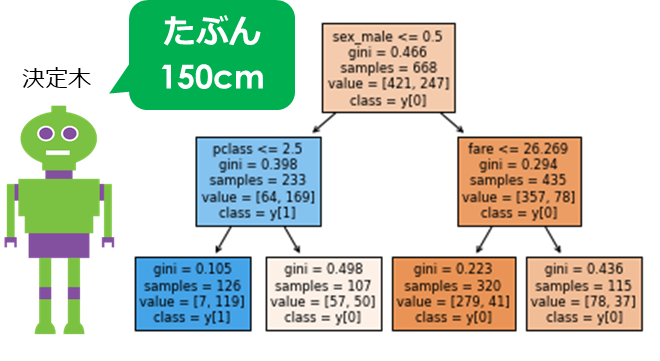
決定木のイメージ
決定木はツリー構造を用いて、条件分岐をさせ予測を行います
「決定木」は1つのモデルのみで予測するので、もちろん精度は高くありません
(正解の158cmから8cmの誤差)
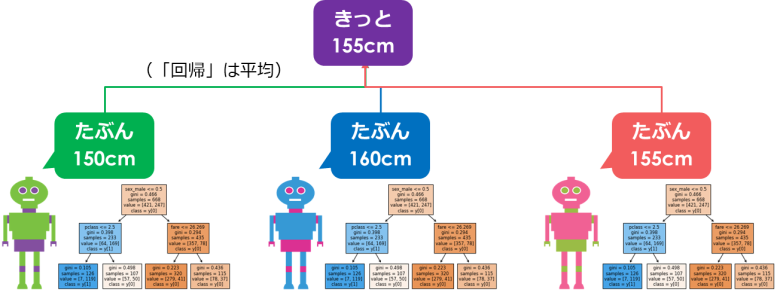
ランダムフォレスト(バギング)
ランダムフォレストは「決定木」の集合体です
全く同じデータでは結果は同じなので、それぞれのモデルに対して利用するデータを制限(サンプリング)します
3人のモデルが予測した結果の平均を取り、全体の予測とします
(正解の158cmから3cmの誤差)
ポイントは、決定木を組み合わせることで色々な人(モデル)の意見を聞くことができるので精度が高まります
勾配ブースティング木
勾配ブースティング木はランダムフォレストとは違い、直列にモデルを作成します
そして最初の予測誤差を次のモデルに活かします
正確には2本目以降の木が、目的変数とそれまでに作成した決定木の予測誤差に対して学習を行います
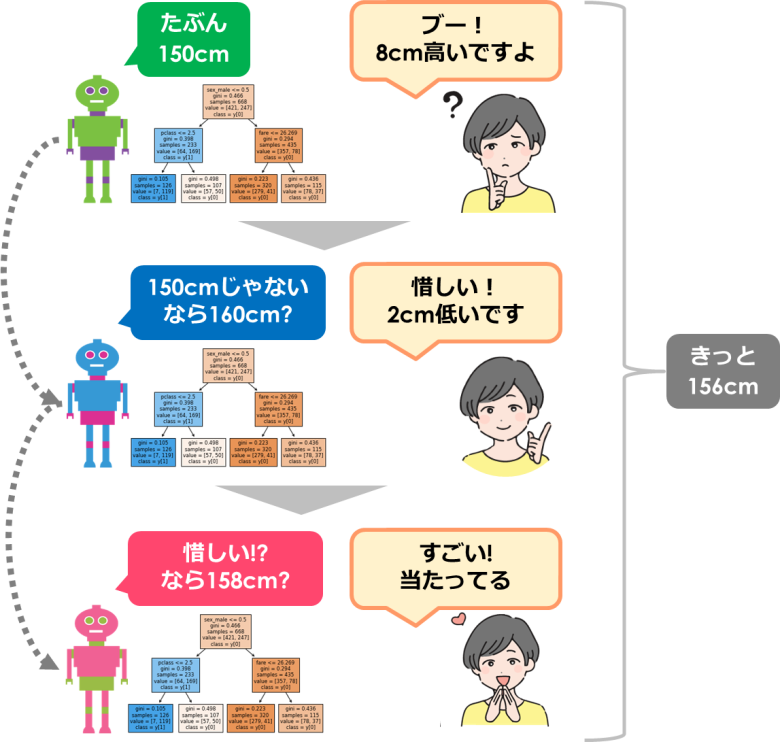
都度、答え合わせをしているので、予測の結果が高くなるのは当然な気がしますよね
(正解の158cmから2cmの誤差)
勾配ブースティング木の種類
ここまで勾配ブースティング木の種類についてご紹介してきました
機械学習のモデルでよく使われる勾配ブースティング木は下記3種類です
- XGBoost
- LightGBM
- Catboost
XGBoostは精度の高さからコンペなどでよく見かけます
また企業の実務でも利用されているほど便利なモデルです
LightGBMはXGBoostに似たアルゴリズムですが、より高速で実施することが可能です
Catboostはカテゴリー変数の処理で上記2つと異なる部分があります
使い方はこちらの記事にてご紹介しています
 【機械学習】XGBoostを分かりやすく実践|XGBoost
【機械学習】XGBoostを分かりやすく実践|XGBoost  【機械学習】高速のLightGBMを実装します|XGBoostと比較
【機械学習】高速のLightGBMを実装します|XGBoostと比較 まとめ
今回は勾配ブースティング木(GBDT)のイメージについてご紹介してきました
決定木やランダムフォレストとの違いについて、想像できましたでしょうか?
より実践で利用されるGBDTについてぜひPythonで実装してみてください



端的な説明ありがとうございました。