 Smart-Hint
Smart-Hint 
目次
ランダムフォレストとは
今回は機械学習の一種であるランダムフォレスト(RandomForest)をご紹介します
フォレストは「森」のことで、決定木の「木」を集めたものを示しています
ツリー構造の条件分岐を使って予測を行う決定木を、いくつも使って精度を高める手法です
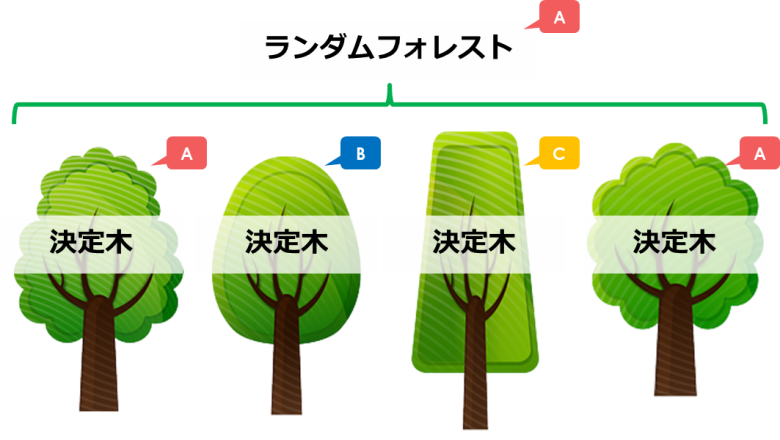
決定木の作り方に関しては下記記事をご覧ください
 【機械学習】決定木のPython実践・可視化|Decision Tree
【機械学習】決定木のPython実践・可視化|Decision Tree
同じ決定木をいくつも用意しても、結果が同じになってしまいますよね…
そこでランダムフォレストは単純に決定木の寄せ集めではなく、より精度を高められるように調整を行っています
- 元データから一部のレコードを抽出し利用する(ブーストラップサンプリング)
- 分岐ごとに一部の特徴量のみを利用する
- 決定木それぞれの「平均」や「多数決」で予測を行う(バギング)
それぞれイメージしやすいように図を用いて解説します
①一部のレコードのみ利用する(ブーストラップサンプリング)
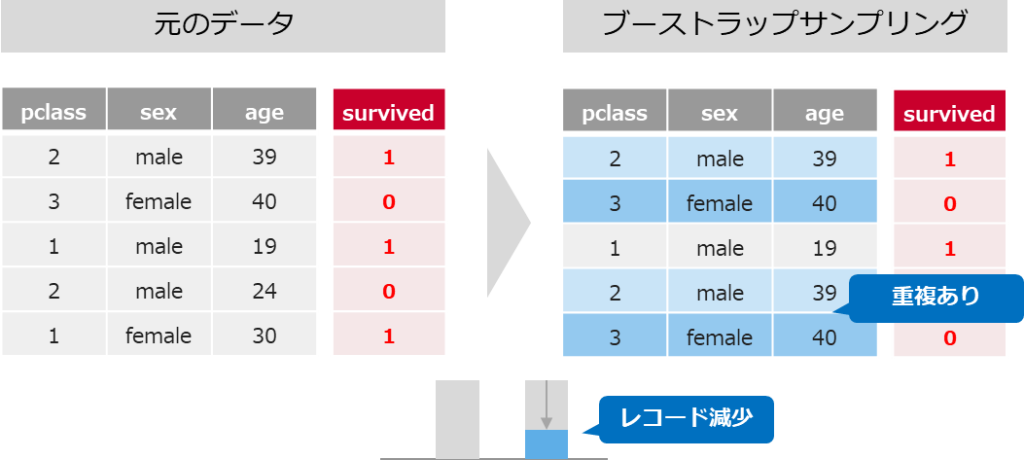
機械学習に利用する元データから、重複ありでデータをサンプリングします
元データ全体の1/3程度しか利用しないため、一見精度が下がるように思ってしまいます
しかし一部のデータを使った決定木を複数作ることで、過学習を防ぎ予測精度を高めることができます
②分岐ごとに一部の特徴量のみを利用する
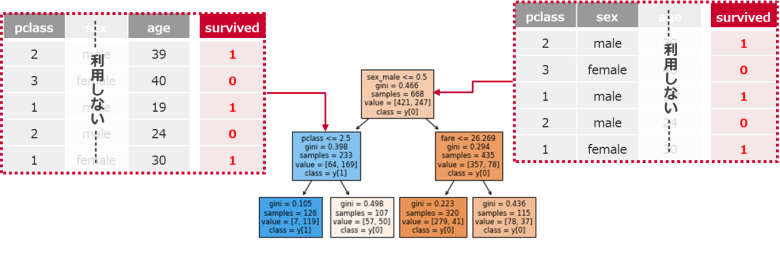
決定木の分岐で全ての特徴量を使わず、一部の特徴量のみで分岐を行います
利用する特徴量の個数は、平方根の個数だけ抽出して候補とします(特徴量が9個なら3個)
※回帰タスクではサンプリングせず全てを候補とします
③決定木それぞれ「平均」や「多数決」で予測を行う(バギング)
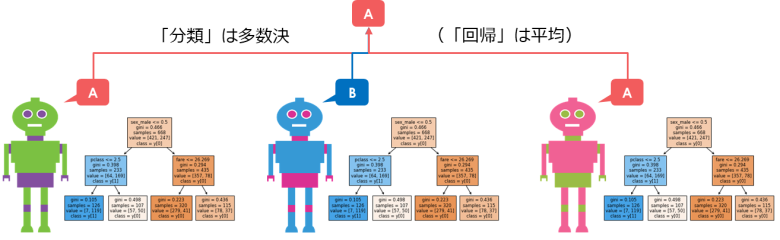
「レコード」と「特徴量」を限定したうえで、複数の決定木を作成します
最終的にそれぞれの決定木が予測した結果をまとめて1つの予測とします
分類タスクの場合は「多数決」で、回帰タスクの場合は「平均」を採用します
※上記例では3つの決定木モデルのみですが、ランダムフォレストでは100個以上の木を作成します
事前準備
Seabornから、タイタニック号のデータを取得しておきます
またPandas/ sklearnも合わせてインポートしておきます
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
df = sns.load_dataset('titanic')
df.head()
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介します
ランダムフォレストの前処理
欠損値の処理
ランダムフォレストでは欠損値(NaN)を取り扱えないため、変換を行います
まずは欠損値が存在しているかを確認します
df.isnull().sum()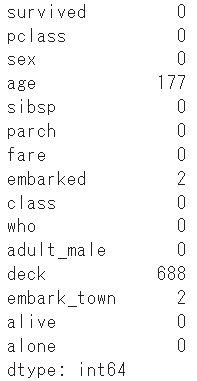
ageやdeck、embarked(embark_town)に欠損値が見られますが、後程ダミー変数処理を行うため文字列(カテゴリー)以外のageのみ対応します
年齢は平均で置き換えましょう
age_mean = df['age'].mean()
df['age'] = df['age'].fillna(age_mean)説明変数(x)と目的変数(y)に分割
事前準備で用意した変数(df)を説明変数と目的変数に分割します
生存者を示す(survivedとalive)を取り除きましょう
df_x = df.drop(['survived','alive'], axis=1)
df_y = df['survived']ダミー変数処理(文字列→数値)
get_dummiesで文字列型のデータを数値型(0-1)に変換します
df_x = pd.get_dummies(df_x)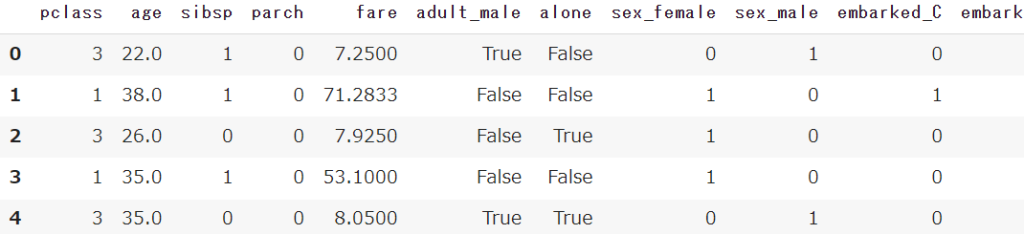
 【Python】カテゴリ変数の数値変換|ダミー処理(one-hot encoding / label encoding)
【Python】カテゴリ変数の数値変換|ダミー処理(one-hot encoding / label encoding)
学習用-テスト用に分割
train_test_splitを使って、学習用とテスト用にデータを分割します
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(df_x,df_y,random_state=1) 【機械学習】学習-テストデータに分割(hold-out法)|train_test_split
【機械学習】学習-テストデータに分割(hold-out法)|train_test_split
ランダムフォレストモデルの作成と予測
ランダムフォレストの分類モデル(RandomForestClassifier)を作成します
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=200,random_state=1)上記で前処理を実施したデータをfitメソッドで学習を行います
model.fit(train_x, train_y)モデルのスコアを算出します
print(model.score(test_x,test_y))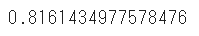
パラメータ:n_estimators(決定木の数)
n_estimatorsでは利用する決定木の数を指定することができます
デフォルト設定では10です(10本の決定木の平均・多数決)
多ければ多いほど良いですが、処理の時間もかかってしまうため100~300ほど指定しましょう
パラメータ:max_depth(決定木の深さ)
max_depthでは決定木の深さを設定することができます
決定木と同じパラメータですね
デフォルトではNoneなので、深さの指定はありません
細かくし過ぎると過学習となるため、調整する必要があります
パラメータ:max_features(利用する特徴量)
max_featuresではランダムに抽出する特徴量の数を変更できます
デフォルトでは特徴量の平方根(全体が9個であれば、3個)
決定木との比較
最後に決定木単体とランダムフォレストを比較してみます
from sklearn.ensemble import RandomForestClassifier
model_randomforest = RandomForestClassifier(n_estimators=300,random_state=1)
model_randomforest.fit(train_x,train_y)
from sklearn import tree
model_tree = tree.DecisionTreeClassifier(max_depth=5, random_state=1)
model_tree.fit(train_x, train_y)
print('ランダムフォレスト:',model_randomforest.score(test_x,test_y))
print('決定木:',model_tree.score(test_x,test_y))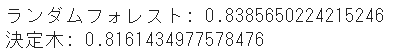
ランダムフォレストの方が若干精度が高い結果となりました
理論上、ランダムフォレストの方が精度が上がるので、こちらを使いたいですね
まとめ
今回は「決定木」を集合させた「ランダムフォレスト」をご紹介してきました
精度も高く、簡単に実施できるためぜひ使ってみてください
全てのコード
# 事前準備
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# タイタニック号のデータ読み取り
df = sns.load_dataset('titanic')
# 欠損値の確認
df.isnull().sum()
# 年齢のみ欠損値の処理
age_mean = df['age'].mean()
df['age'] = df['age'].fillna(age_mean)
# 目的変数と説明変数の分割
df_x = df.drop(['survived','alive'], axis=1)
df_y = df['survived']
# 目的変数のダミー変数化
df_x = pd.get_dummies(df_x)
# 学習用-テスト用のデータに分割
train_x, test_x, train_y, test_y = train_test_split(df_x,df_y,random_state=1)
# ランダムフォレストモデルの作成
model = RandomForestClassifier(n_estimators=200,random_state=1)
model.fit(train_x,train_y)
# ランダムフォレストモデルのスコア
print(model.score(test_x,test_y))
