 Smart-Hint
Smart-Hint 
目次
XGBoostとは?
XGBoostとは勾配ブースティング木の一種で、精度が高く分析コンペや実務で非常に利用されている機械学習のモデルです
今回はこのXGBoostをPythonで実装する方法をご紹介します
他の機械学習のモデルと若干やり方が異なるため注意が必要です
勾配ブースティング木のイメージについては、分かりやすく解説している記事をご覧ください
 【機械学習】勾配ブースティング木のイメージを図解|GBDT
【機械学習】勾配ブースティング木のイメージを図解|GBDT
事前準備
Seabornから、タイタニック号のデータを取得しておきます
またPandasも合わせてインポートしておきます
import seaborn as sns
import pandas as pd
df = sns.load_dataset('titanic')
df.head()
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介します
XGBoostの前処理
XGBoost(勾配ブースティング木)は以下の特徴があり、事前に前処理をする必要があります
- 特徴量は数値形式(1.2.3…)
- 欠損値を扱うことができる
- 学習-テストデータを指定の構造にする必要がある
事前準備で用意したタイタニック号のデータを使って、XGBoostで生存者の予測のための前処理を行います
説明変数(x)と目的変数(y)に分割
事前準備で用意した変数(df)を説明変数と目的変数に分割します
生存者を示す(survivedとalive)を取り除きましょう
df_x = df.drop(['survived','alive'], axis=1)
df_y = df['survived']![df_x = df.drop(['survived','alive'], axis=1)](https://smart-hint.com/wp-content/uploads/2022/01/image-133-1024x207.png)
ダミー変数処理(文字列→数値)
get_dummiesで文字列型のデータを数値型(0-1)に変換します
df_x = pd.get_dummies(df_x)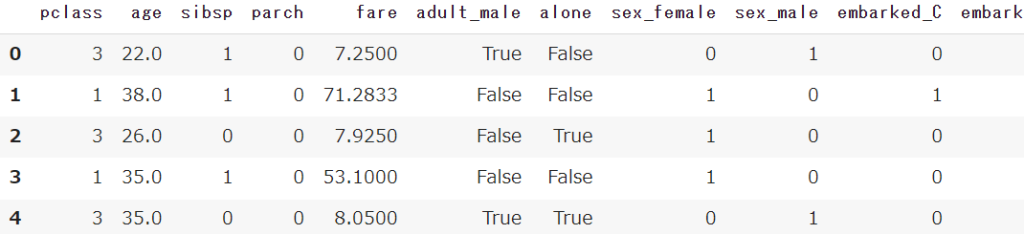
 【Python】カテゴリ変数の数値変換|ダミー処理(one-hot encoding / label encoding)
【Python】カテゴリ変数の数値変換|ダミー処理(one-hot encoding / label encoding)
学習用-テスト用に分割
train_test_splitを使って、学習用とテスト用にデータを分割します
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(df_x, df_y, random_state=1)
 【機械学習】学習-テストデータに分割(hold-out法)|train_test_split
【機械学習】学習-テストデータに分割(hold-out法)|train_test_split
XGBoost用にデータを加工する
xgb.DMatrixを使い、学習用・テスト用データに作成したデータを加工します
labelに対して目的変数を指定しましょう
import xgboost as xgb
dtrain = xgb.DMatrix(train_x, label=train_y)
dtest = xgb.DMatrix(test_x, label=test_y)XGBoostのパラメータとモデル作成
xgb.trainを使いモデルを作成します
その前にパラメータを事前に用意しておきましょう
objectiveで目的変数を指定します
- 「reg:linear」:線形回帰
- 「reg:logistic」:ロジスティック回帰
- 「binary:logistic」:2クラス分類で確率を返す
学習過程を隠すsilentを1に設定し、アウトプットを一定にするためrandom_stateを任意の数値で指定しましょう
学習回数もnum_roundで指定することができます
params = {'objective':'binary:logistic',
'silent':1,
'random_state':1}
num_round = 50続いてXGBoost特有のパラメータも設定します
学習用とテスト用のデータを1つのパラメータにまとめます
watchlist = [(dtrain, 'train'), (dtest, 'test')]xgb.trainでモデルを作成、学習します
事前に設定したパラメータを指定しましょう
- params:事前に設定したパラメータ
- dtrain:学習用のデータ
- num_round:学習回数
- verbose_eval:学習結果のアウトプットを省略する間隔
- watchlist:1つにまとめたデータ群
model = xgb.train(params, dtrain, num_round, verbose_eval=10, evals=watchlist)
XGBoostの評価
今回は2クラス分類のためlog_lossで評価を行います
predictでモデルに対して予測を行い、正解データ(テストデータ)とのスコアを比較します
from sklearn.metrics import log_loss
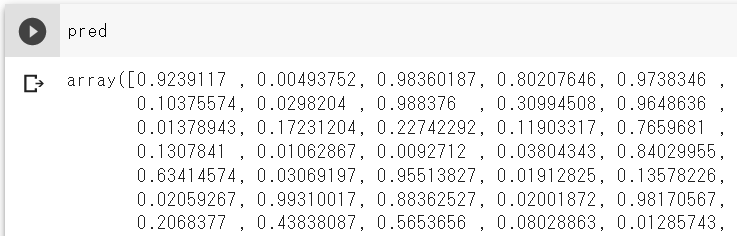
pred = model.predict(dtest)
score = log_loss(test_y.values, pred)
print(f'{score:.4f}')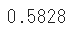
predictではarray形式で予測値が出てくるので、注意しましょう
まとめ
今回は勾配ブースティング木の一種であるXGBoostをご紹介してきました
非常に強力な手法ではあるものの、他の機械学習のモデルと実装方法が異なる部分があります
ぜひ使ってみてください
全てのコード
# 事前準備
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
import xgboost as xgb
from sklearn.metrics import log_loss
# タイタニック号のデータを取得
df = sns.load_dataset('titanic')
# 説明変数と目的変数に分割
df_x = df.drop(['survived','alive'], axis=1)
df_y = df['survived']
# 前処理(ダミー変数化)
df_x = pd.get_dummies(df_x)
# 学習用-テスト用に分割
train_x, test_x, train_y, test_y = train_test_split(df_x, df_y, random_state=1)
# XGBoost専用のデータ処理
dtrain = xgb.DMatrix(train_x, label=train_y)
dtest = xgb.DMatrix(test_x, label=test_y)
# XGBoostのパラメータ設定
params = {'objective':'binary:logistic',
'silent':1,
'random_state':1}
num_round = 50
watchlist = [(dtrain, 'train'), (dtest, 'test')]
# XGBoostのモデル作成と予測
model = xgb.train(params, dtrain, num_round, verbose_eval=10, evals=watchlist)
# XGBoostのモデル評価
pred = model.predict(dtest)
score = log_loss(test_y.values, pred)
print(f'{score:.4f}') 【機械学習】勾配ブースティング木のイメージを図解|GBDT
【機械学習】勾配ブースティング木のイメージを図解|GBDT
 【機械学習】高速のLightGBMを実装します|XGBoostと比較
【機械学習】高速のLightGBMを実装します|XGBoostと比較

