 Smart-Hint
Smart-Hint 

目次
おさらい:データを読み取ってみる

今回はさっそくデータを分析していきます!

はい!頑張ります!

では前回のおさらいで、Excelのデータを読み取ってみましょう
Pandasのインポートも忘れずに!
import pandas as pd
df = pd.read_excel('/content/drive/MyDrive/***/student.xlsx')
df.head()
read_excelでExcelのデータを読み取って、変数の「df」に入れるんですよね!できました!
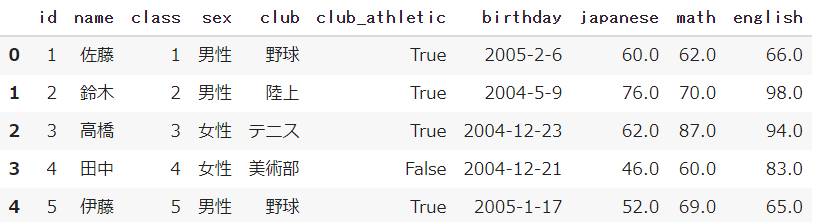
read_excelでデータを読み取って、最初の5行を出すheadで確認する
この流れは鉄板なので覚えておきましょう!
はい!分かりました!
ちなみにExcelを使わないでデータを読み取る方法もあるのでご紹介します!
そのまま貼り付けて実行すればデータを取得できます!
import pandas as pd
df = pd.read_html('https://smart-hint.com/student-data/')[0]
df.head()
急に分からなくなりました・・・

混乱させて申し訳ない・・・
read_htmlを使うとWeb上にあるデータを取得することができます
今回は本サイトにあるデータにアクセスしていますよ
もしかして「read_〇〇」でいろいろなファイルを読み取ることができるんですか?

その通り!他にもCSVファイルを読み取るread_csvもあります
 【Python】read_csv|CSVファイルをPythonに読み込む方法
【Python】read_csv|CSVファイルをPythonに読み込む方法
これからはExcelのデータを準備するのが大変なので、read_htmlを使っていきます
分かりました!!
さて、今回はどういう作業をするんですか?
Pythonが使えるようになったので、もうデータ分析に入りましょう!

さっそく実践ですね!やった!
では分析のテーマを発表しましょう!
テストの平均点を算出する
平均ですか!?さすがにこれくらいExcelでもできますよ
時間もかかりません・・・
もちろん単純に平均点を出すのは簡単です!せっかくPythonで分析するので、「教科ごと」や「部活ごと」に平均点を出してみましょう!
はい!分かりました!
必要なデータに絞りたい
まず最初に必要なのは、使うデータに絞ること!
テストの平均点データなので「国語・数学・英語」に絞るんですよね!
そう!点数のデータに絞ってみましょう
Pythonでは変数の隣に[ ]を付けて、カラム名(列名)を記述します
英語の点数に絞るにはこうですか??
df[english]![df[english]](https://smart-hint.com/wp-content/uploads/2022/03/image-7.png)

あれあれ!?エラーが出ました・・・
カラム名には‘ ‘シングルクォーテーションを付けましょう!
データが出ました!!
あれ、でも前と雰囲気が違う・・・前は「表」だったのに、今回は「数値」が並んでる!?
df['english']![df['english']](https://smart-hint.com/wp-content/uploads/2022/03/image-8.png)
SeriesとDataFrameの違い!?
良いところに目を付けましたね!これはデータ構造の違いです
1次元のSeries(シリーズ)と、2次元のDataFrame(データフレーム)があります。
しりーず?でーたふれーむ???
難しいことは考えず、複数の列があるDataFrameと、単一の列だけのSeriesと覚えましょう
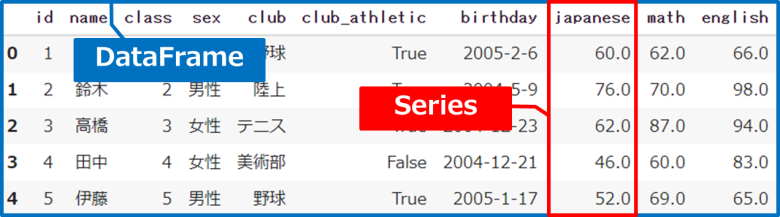
はい、分かりました!複数のデータフレームと、単一のシリーズ
英語の点数をSeries形式で取り出すことができたので、平均点をさっそく出しましょう
新しい変数「df_english」に英語の点数を格納してください
変数は名前の付いた箱だから、こうですか??
df_english = df['english']平均を出すmean関数
完璧!英語の点数だけが「df_english」に入りました!
平均を出すためにmean関数を利用しましょう!使い方は最初に.ピリオド・最後に( )を忘れずに
これで合ってますか?
df_english.mean()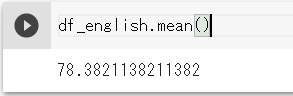
おおー!78点と平均点ができてました!
英語の平均点が分かりましたね!
では続いて「国語・数学・英語」の3教科の平均点を出してみましょう
3つの教科の平均点だから、こう書けばいいんだ!
df_english = df['english']
df_english.mean()
df_japanese = df['japanese']
df_japanese.mean()
df_math = df['math']
df_math.mean()もちろんこのコードでも正解です!
ただ今回は3教科まとめて出してみましょうか!?
,カンマで並べて書いてみてください
df_testという変数を作って、3つを,カンマで並べてみました!
あれ、でもエラーが出たぞ・・・!?
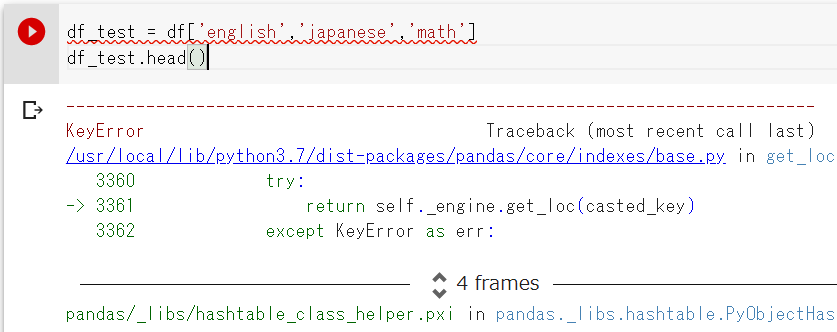
複数のカラムを抽出する場合はDataFrameの方になるので、[]角括弧を二つ並べましょう
df_test = df[['english','japanese','math']]
df_test.mean()そうか、複数のカラムの場合は[[ ]]こうやって書くんですね!覚えておきます
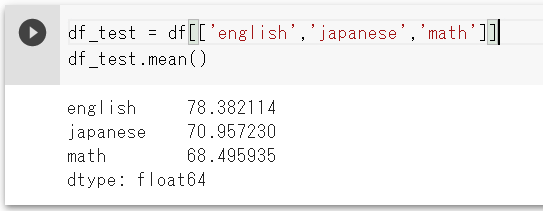
3つのテストの平均点が出ましたね!
英語が一番高くて、数学が一番低いです!
私も数学は苦手だったな・・・
項目”ごと”に平均点を出してみる
今までは単純にテストの点数の平均を出しましたが、より分析っぽくするために項目に分けて平均を出してみましょう
項目ごとってことは「部活」とか「性別」ごとの平均ってことですね!
確かに運動部は勉強が苦手ってイメージがあったりしますw
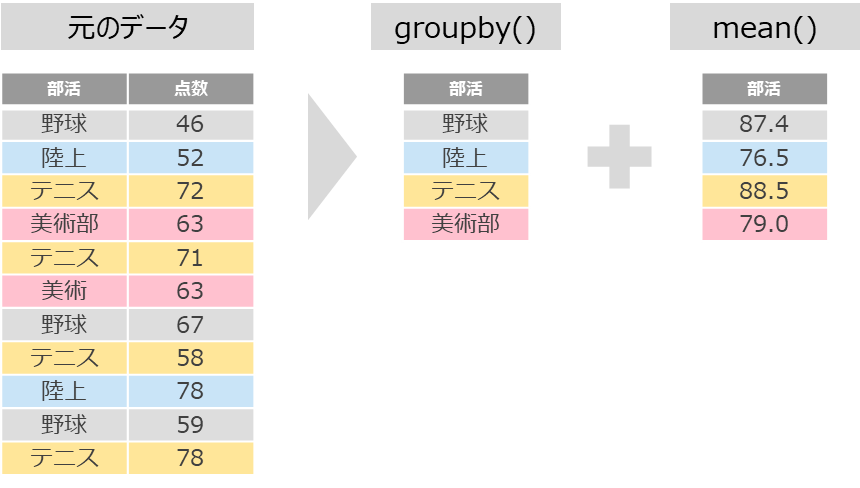
項目ごとに集計(平均や合計)するにはgroupby(グループバイ)を使います
平均のように.ピリオドと( )括弧を記述し、( )括弧の中に分けたい項目を入れましょう
できました!でも何も出てこなかったです・・・

groupbyはあくまでもまとめるだけ!
後ろに続けてmeanを付けてあげてください
groupbyとmeanを続けて書けるんですか!?
df.groupby('club').mean()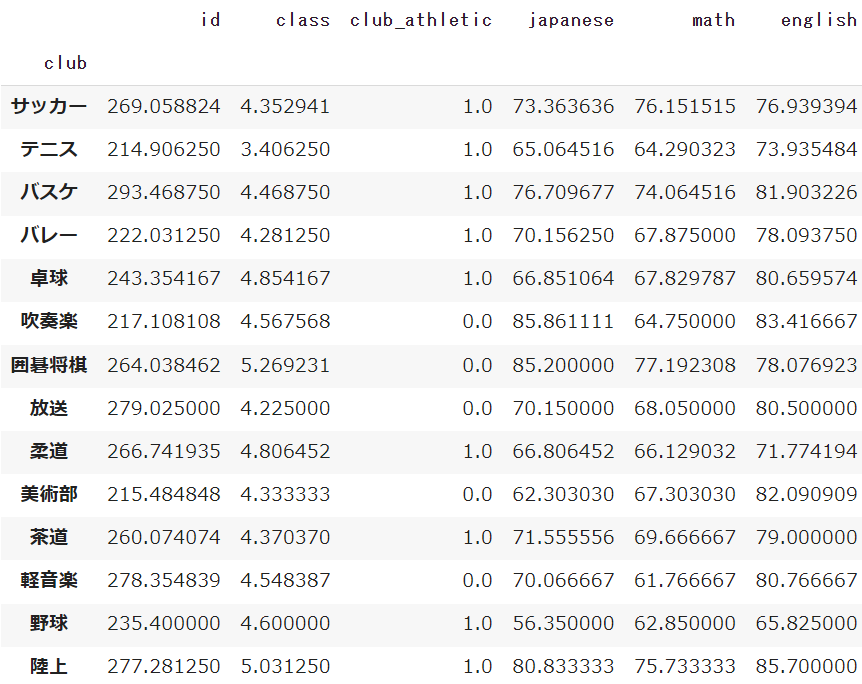
確かに平均は出ましたが、生徒番号やクラスなども平均が出ました!
groupbyとmeanを組み合わせると、数値型のデータ全てで平均が算出されます
[[ ]]を後ろに付けると、カラム(列)を限定することができますよ
おおーうまく出ました!
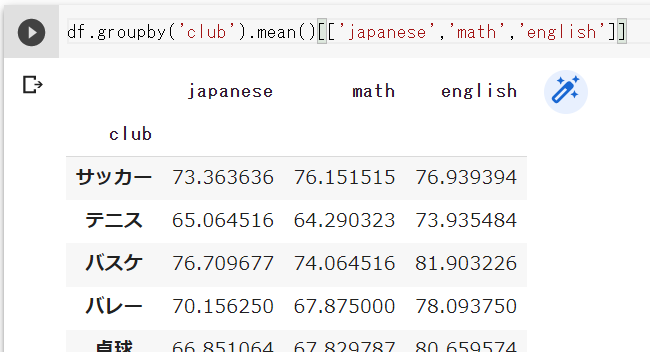
ちなみにこの書き方だとエラーが出たんですが・・・?

Pythonでは一つのコードが左から順番に適応されるんです
つまり最初のdf[[‘japanese’,’math’,’english’]]で、3つのカラムに限定しているので、後ろのgroupbyで指定しているclubが見つからないエラーが出てるんですよ
なるほど!だから最後でカラム(列)を指定しているんですね
メソッドの使い方のコツ
groupbyなどのメソッドと呼ばれる機能は、変数に続けて書くことでデータを思いのままに変形することができます
様々なメソッドが登場するので、使い方を覚えましょう!
Excelの関数みたいなやつですか?
そう!そのイメージ!ポイントは4つです
- 変数の後ろに続けて記述する
- .ピリオドで始める
- ()括弧を後ろに付ける
- パラメータ(引数)を指定する
パラメータ?引数?初めて聞きました・・・
パラメータは詳細設定みたいなイメージかな・・?
必須で設定しないといけないものと、任意で設定するものがあります!
うーん、分かったような・・分からないような・・
今後、また教えていきますね!
やった、ありがとうございます!
まとめ
- [ ]でカラム(列)を指定して、データを限定する
- meanで平均が出る
- groupbyで項目ごとに分析ができる

