
目次
特徴量スケーリングとは?
今回は特徴量スケーリング(Feature Scaling)と呼ばれる、「標準化」と「正規化」について説明します
Pythonを利用してデータを変換する方法もご紹介します
特徴量スケーリングとは、大きさの異なるデータ群の範囲を統一することです
理解しやすくするために、例として「身長」と「体重」のデータをもとに説明します
男性の平均身長「162」と平均体重「62」は、数値の大きさが異なります
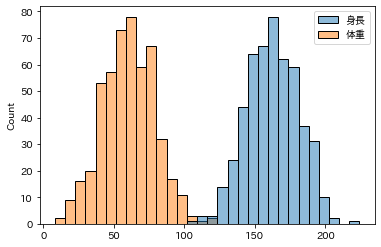
このスケールの違いを合わせるために、特徴量スケーリングの「正規化」を実施します
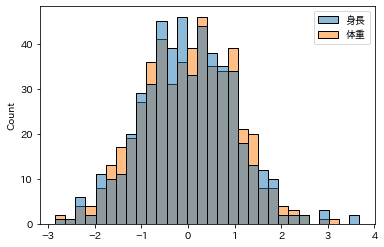
「身長」と「体重」の2つの大きさスケールが異なるデータが重なりました
このようにデータの大小やばらつきを変えずに、データの範囲を合わせることを特徴量スケーリングと呼びます
なぜ特徴量スケーリングを実施するのか?
特徴量スケーリングを行う理由は、機械学習のモデル学習を正しく行うためです
例えば教師ありの線形回帰モデルを、身長と体重のデータに適応させたとします
「身長」の方が数値スケールが大きいため、重要な指標として学習が進んでしまいます
データ間の範囲が異なっていると、間違ったモデルができたり時間がかかりすぎたりします
一方で「データの大小」だけを見る「決定木モデル」やその応用のモデルは必要ありません
- 決定木
- ランダムフォレスト
- XGBoost
- LightGBM
上記のような決定木モデル(ツリー構造)を使った機械学習の場合は、特徴量の尺度の違いが学習モデルに影響を与えないため、特徴量スケーリングの必要はありません
 【機械学習】決定木のPython実践・可視化|Decision Tree
【機械学習】決定木のPython実践・可視化|Decision Tree  【機械学習】ランダムフォレストを分かりやすく解説|RandomForest
【機械学習】ランダムフォレストを分かりやすく解説|RandomForest 標準化と正規化の違い
特徴量スケーリング(Feature Scaling)には様々な手法がありますが
今回はよく利用される「標準化」と「正規化」の2つについてご説明します
- 標準化:データを平均0、標準偏差が1になるように変換
- 正規化:データの最小値を0、最大値を1になるように変換
標準化は平均が0、標準偏差が1になるようにデータを変換するため、下記グラフのように原点が0となります
※横軸をご覧ください。
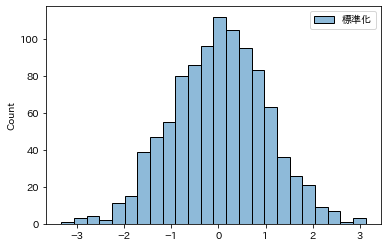
一方で正規化は「0~1」の間にデータが収まるように変換します
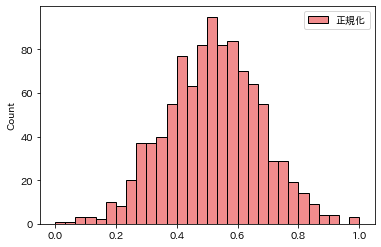
2つの使い分けとして、データの中に外れ値が存在している場合は「標準化」の方を利用します
正規化は外れ値の影響を多く受けるためです
比較的に「標準化」が機械学習の前処理として利用されるケースが多いです
特徴量スケーリングの事前準備
Seabornから、チップ価格のサンプルデータを取得しておきます
またPandasも合わせてインポートしておきます
import seaborn as sns
import pandas as pd
df = sns.load_dataset('tips')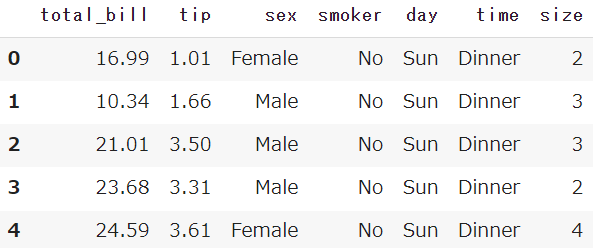
 【Python】チップ価格のサンプルデータをご紹介
【Python】チップ価格のサンプルデータをご紹介今回はチップ価格のサンプルデータから、支払総額(total_bill)とチップ(tip)の2つを利用します
2つのデータをグラフ化してみましょう
col = ['total_bill','tip']
sns.histplot(data=df[col], bins=30)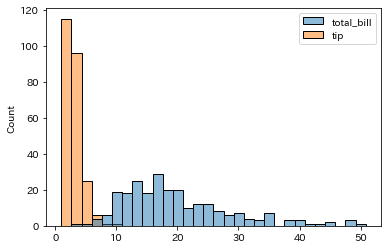
「支払総額」の方がもちろん額が大きく、横軸に長く伸びる棒グラフとなっており
「チップ」の方は金額が小さいため、グラフの左側に固まった棒グラフになっています
ここからデータのスケールを調整していきましょう
標準化:StandardScaler
標準化はデータを平均0、標準偏差が1になるように変換する手法です
sklearnからStandardScalerを使うことで簡単に標準化を行うことができます
変数(scaler)を作成し、fit_transformで変換を行います
from sklearn.preprocessing import StandardScaler
col = ['total_bill','tip']
scaler = StandardScaler()
df_sc = scaler.fit_transform(df[col])
変換したデータをSeabornで可視化します
sns.histplot(data=df_sc, bins=30)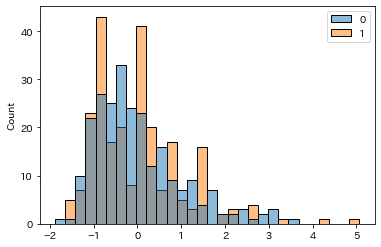
正規化:MinMaxScaler
正規化はデータの最小値を0、最大値を1になるように変換する手法です
標準化と同じくsklearnからMinMaxScalerを使うことで簡単に正規化を行うことができます
変数(scaler)を作成し、fit_transformで変換を行います
from sklearn.preprocessing import MinMaxScaler
col = ['total_bill','tip']
scaler = MinMaxScaler()
df_sc = scaler.fit_transform(df[col])
変換したデータをSeabornで可視化します
sns.histplot(data=df_sc, bins=30)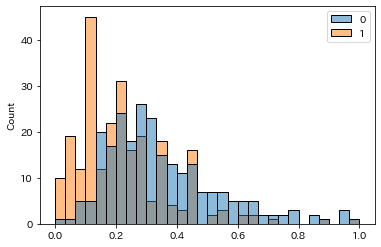
※変換手法の補足
先ほどはfit_transformでモデルの学習と変換を一度の実施しましたが
fitとtransformを分けて変換を実施することも可能です
from sklearn.preprocessing import StandardScaler
col = ['total_bill','tip']
scaler = StandardScaler()
scaler.fit(df[col])
df_sc = scaler.transform(df[col])標準化と正規化の変換を行うと、array形式でデータが出力されます
DataFrameを使いカラム名を指定することで、変換前のカラム名を利用できます
pd.DataFrame(scaler.fit_transform(df[col]),
columns=df[col].columns)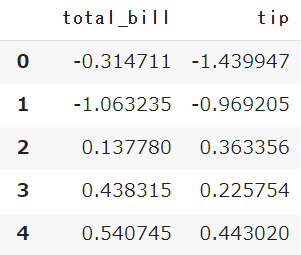
まとめ
今回は特徴量スケーリング(Feature Scaling)と呼ばれる、「標準化」と「正規化」についてご紹介してきました
機械学習で、数値のスケールが処理に影響を与えるモデルに関しては特徴量スケーリングが必要です
sklearnを利用することで簡単に実施できるのでぜひ使ってみてください


