 Smart-Hint
Smart-Hint 
目次
クラスタリングとは?
今回は機械学習のクラスタリングをPythonで実装する方法をご紹介します
クラスタリングとは「似たようなデータ同士をまとめる」ことができる手法です
データは膨大になればなるほど、取り扱うに手間や時間がかかってしまいます
クラスタ(群)ごとに分けることで、データの中身を理解しやすくしたり、群ごとに施策を行うことができます
- 顧客(1000)人に対して、新商品の広告メールを打ちます
- 全員に同じ内容を送るのではなく、購入履歴や個人情報をもとに似たような群に分けて、それぞれコミュニケーションをとる
- 顧客データに対して「クラスタリング」を行い、5つの群に分けて広告メールを送信する
機械学習としてのクラスタリング
機械学習には「教師あり学習」と「教師なし学習」の2種類が存在しています
「教師」とは先生のことではなく、正解とする情報のことです
- 「教師あり学習」である「回帰」や「分類」は、未知のデータに対して正解を予測する手法です
- 「教師なし学習」であるクラスタリングには、これが正解!という答えがありません
Pythonでの実装方法や解釈の仕方が異なるので注意してください
そして今回は機械学習のクラスタリングで最も有名なk-meansについてご紹介します
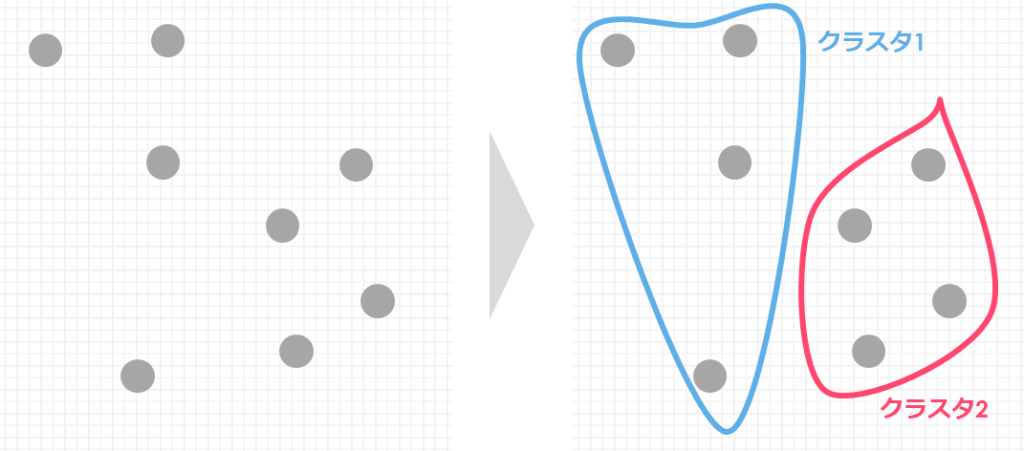
k-meansの処理イメージ
k-meansの処理イメージについて、シンプルなデータを用いて解説します
kはクラスタリングで分割する個数を表し、事前にいくつのクラスタに分けるか決めておきます
今回はイメージしやすいように、特徴量を2つ(x軸とy軸の散布図で書ける)に限定し、データ数も9個とします
そして2つのクラスタに分類しましょう

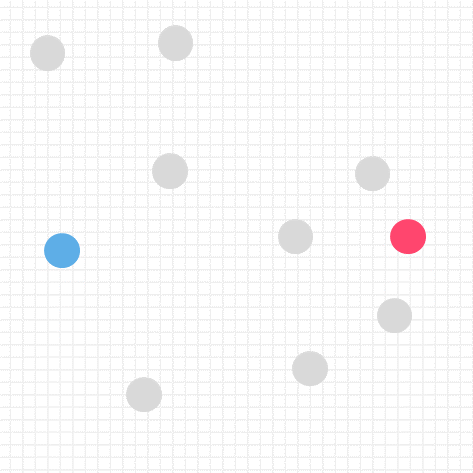
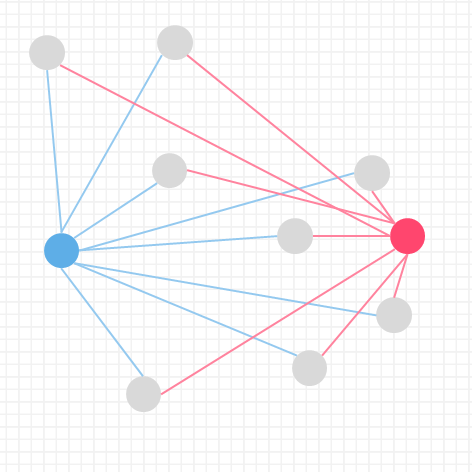
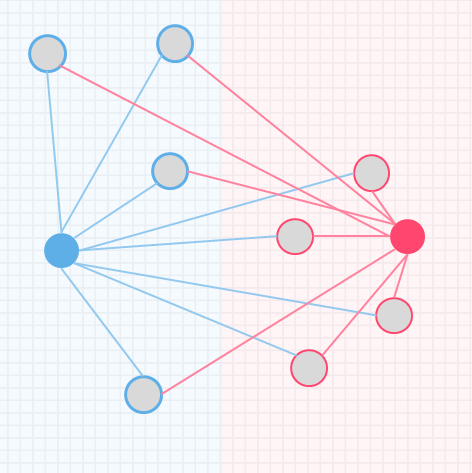
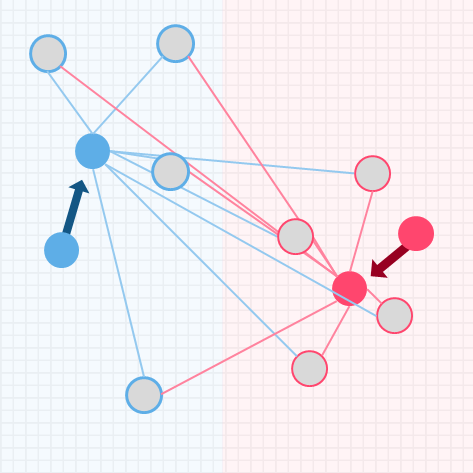
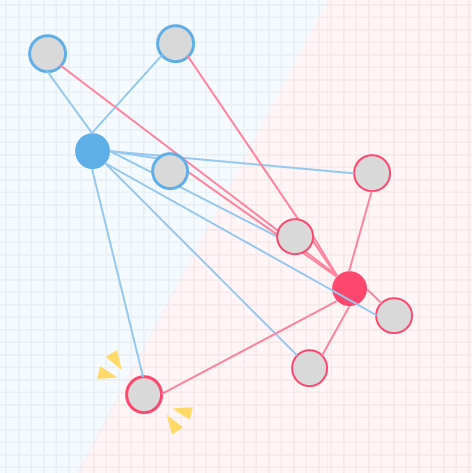
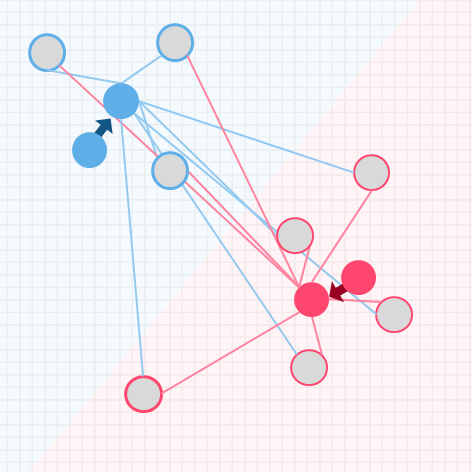

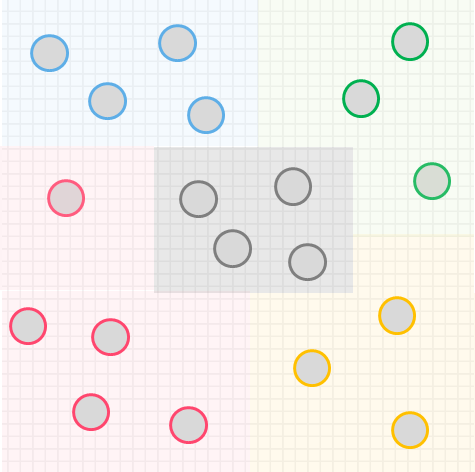
イメージしやすいように2つの特徴量のみで散布図を作り説明しましたが、
実際は様々な情報に対してクラスタを割り振ります
人間では複雑すぎて分かりにくいので、機械(AI)に任せましょう
事前準備
Seabornから、タイタニック号のデータを取得しておきます
またPandasも合わせてインポートしておきます
import seaborn as sns
import pandas as pd
df = sns.load_dataset('titanic')
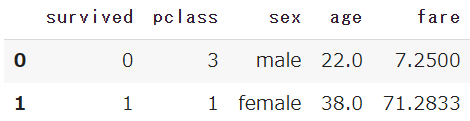
df.head()
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介します
k-meansの前処理
k-meansで処理するにはデータの欠損や、大小のスケールを合わせる処理が必要です
また今回は特別にタイタニック号のデータから、理解しやすい項目のみに絞ります
データを限定する
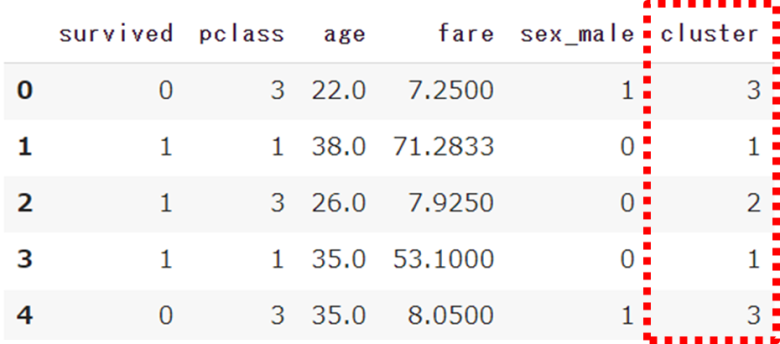
タイタニック号のデータから、「生存」「チケットクラス」「性別」「年齢」「運賃」のみに絞ります
columns = ['survived','pclass','sex','age','fare']
df = df[columns]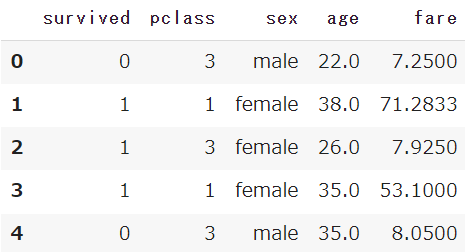
欠損値を処理する
まずはisnullとsumを組み合わせて、欠損値を確認します
df.isnull().sum()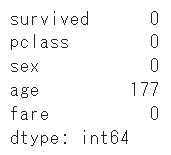
「年齢」に177件の欠損が確認できたので、今回は平均で補いましょう
fillnaを使います
mean = df['age'].mean()
df['age'] = df['age'].fillna(mean) 【Python】欠損値の扱い方大全
【Python】欠損値の扱い方大全
ダミー変数処理(文字列→数値)
データに文字列(male/female)が含まれており、k-meansでは文字列を処理することができないため
ダミー変数処理を行います
df = pd.get_dummies(df, drop_first=True)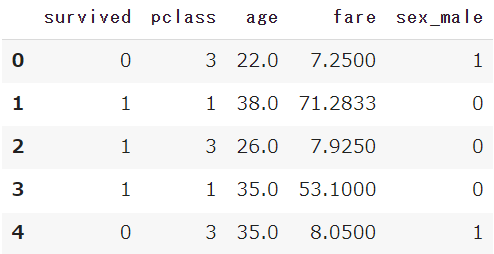
「性別:sex」の項目が、男性を表す「sex_male」の「0/1」に変換されました
 【Python】カテゴリ変数の数値変換|ダミー処理(one-hot encoding / label encoding)
【Python】カテゴリ変数の数値変換|ダミー処理(one-hot encoding / label encoding)
データを標準化する
k-meansではデータの大小が影響してしまうため、標準化を実施する必要があります
※「年齢:age」は「22-38-26…」の大きさで、「チケットクラス:pclass」は「1-2-3」と数値の大きさが圧倒的に異なります
sklearnのStandardScalerを使うことで、簡単に数値の大小のスケールを合わせることができます(標準化)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
df_sc = sc.fit_transform(df)
df_sc = pd.DataFrame(df_sc, columns=df.columns)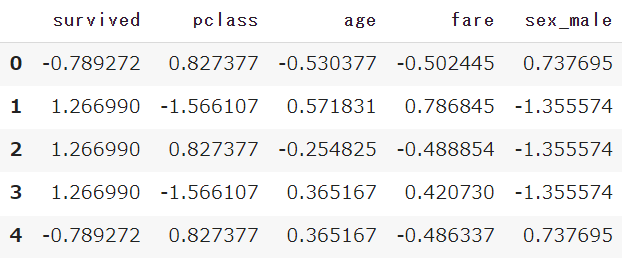
 【機械学習】標準化と正規化をPythonで実施する|特徴量スケーリング
【機械学習】標準化と正規化をPythonで実施する|特徴量スケーリング
k-meansのクラスタリングを実行
前処理が完了したので、k-meansのクラスタリングを行います
sklearnからKMeansをインポートし、モデルを作成します
n_clustersは分割するクラスタ数です
from sklearn.cluster import KMeans
model = KMeans(n_clusters=4, random_state=1)
model.fit(df_sc)モデルの作成、適応が終わったので、クラスタ番号を取得するためlabels_を利用します
cluster = model.labels_
事前に処理していたDataFrameの新しいカラムとして、クラスタ番号を追加しましょう
df['cluster'] = cluster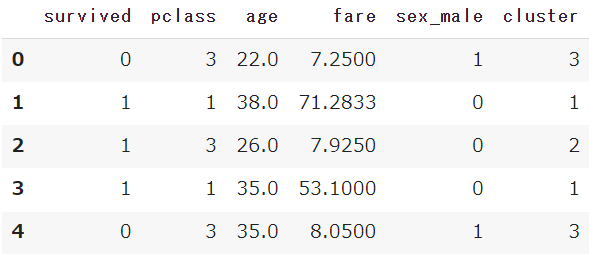
クラスタリングの結果を確認する
さて今回はk-meansを活用したクラスタリングで、「0-3」までのクラスタに分割しました
機械学習のAIモデルはどのような分割を実施したのでしょうか?
読み込ませたデータの平均値を、クラスタごとに確認してみます
df.groupby('cluster').mean().style.bar(axis=0)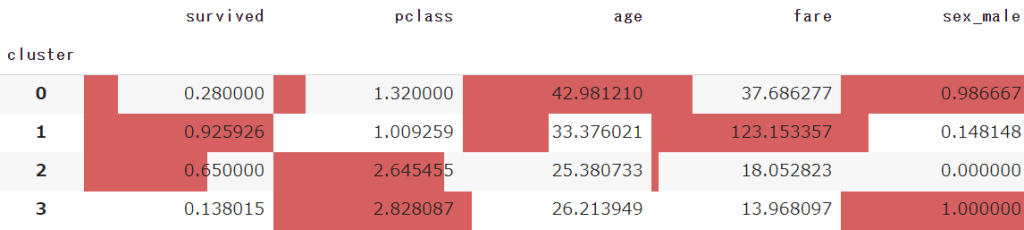
style.barを使うと、DataFrameにカラーバーを追加することができます
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2,3, figsize=(14, 6))
sns.barplot(ax=axes[0,0], data=df, x='cluster', y='survived')
sns.barplot(ax=axes[0,1], data=df, x='cluster', y='pclass')
sns.barplot(ax=axes[0,2], data=df, x='cluster', y='age')
sns.barplot(ax=axes[1,0], data=df, x='cluster', y='fare')
sns.barplot(ax=axes[1,1], data=df, x='cluster', y='sex_male')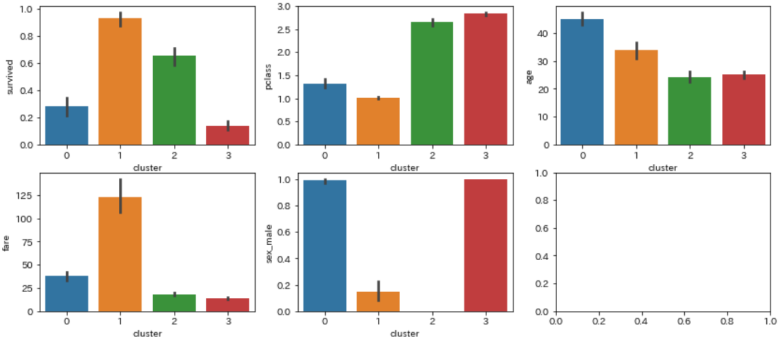
- クラスタ⓪:男性で高齢。よい客室に泊まっており、生存率が低い
- クラスタ①:女性でよい客室に泊まり運賃が最も高く、生存率も一番高い
- クラスタ②:女性で安い客室に泊まっている
- クラスタ③:男性で若年。安い客室に泊まっており、一番生存率が低い
今回のクラスタリングでは「性別:age」と「チケットクラス:pclass」「運賃:fare」が色濃く差が出たようでした
主成分分析でグラフ化する
特徴値が5つしかなかったためそれぞれグラフで可視化しましたが、より複雑なデータの場合は主成分分析による可視化が便利です
詳細な説明は割愛しますが、一つの散布図にデータを置き、クラスタごとに色を変えて確認します
まず標準化したDataFrame(df_sc)に対して、クラスタ番号を付与します
df_sc['cluster'] = cluster続けてPCAをインポートし、学習させます
n_componentsは必要な主成分を指定することができ、散布図(x軸/y軸)に利用するため2を指定します
 【Python】主成分分析(PCA)の実装方法を分かりやすく解説|PCA
【Python】主成分分析(PCA)の実装方法を分かりやすく解説|PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=2, random_state=1)
pca.fit(df_sc)
feature = pca.transform(df_sc)
上記で作成したデータを散布図で可視化します
import matplotlib.pyplot as plt
plt.figure(figsize=(6, 6))
plt.scatter(feature[:, 0], feature[:, 1], alpha=0.8, c=cluster)
plt.xlabel('principal component 1')
plt.ylabel('principal component 2')
plt.show()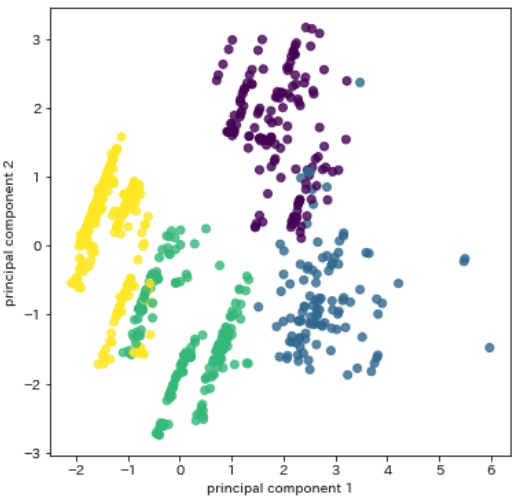
4色で綺麗に分割することができました
まとめ
今回はk-meansを利用したクラスタリングをPythonで実装する方法をご紹介しました
マーケティングの世界では非常によく利用されている手段です
分割する手法のイメージを掴んでいただき、Pythonでトライしてみてください
全てのコード
# 事前準備
import seaborn as sns
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# タイタニック号のデータを取得
df = sns.load_dataset('titanic')
# タイタニック号のデータから必要なカラムに限定
columns = ['survived','pclass','sex','age','fare']
df = df[columns]
# 欠損値の確認と変換
df.isnull().sum()
mean = df['age'].mean()
df['age'] = df['age'].fillna(mean)
# ダミー変数化
df = pd.get_dummies(df, drop_first=True)
# 標準化の実施
sc = StandardScaler()
df_sc = sc.fit_transform(df)
df_sc = pd.DataFrame(df_sc, columns=df.columns)
# k-meansの学習
model = KMeans(n_clusters=4, random_state=1)
model.fit(df_sc)
# k-meansのクラスタ番号の取得
cluster = model.labels_
df['cluster'] = cluster
# 主成分分析の可視化
df_sc['cluster'] = cluster
pca = PCA(n_components=2, random_state=1)
pca.fit(df_sc)
feature = pca.transform(df_sc)
plt.figure(figsize=(6, 6))
plt.scatter(feature[:, 0], feature[:, 1], alpha=0.8, c=cluster)
plt.xlabel('principal component 1')
plt.ylabel('principal component 2')
plt.show()

コードについて質問させていただきます。
散布図の色をc=clusterと指定しているのはなぜですか?
色のコードや数値を指定しないとエラーかえってくると思いますが・・・
ご質問ありがとうございます。scatterメソッドの引数cにclusterを指定することで、各データポイントの色をクラスターに基づいて設定することができます。色をあえて指定することなく、設定ができるためこのように記述しています。