 Smart-Hint
Smart-Hint 
目次
回帰の評価指標
今回は機械学習のモデル評価についてご紹介します
特に「回帰」と呼ばれる機械学習モデルの精度の高さを検証する方法をご説明します
回帰とは収益の予測や株価などの、「数値」を予測します
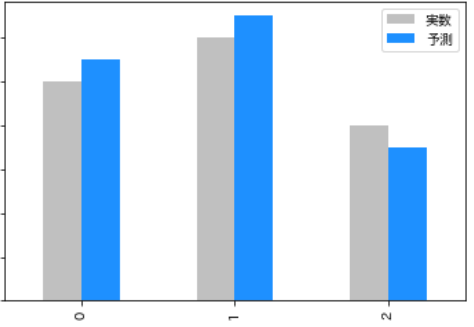
数値を予測する回帰モデルですが、どのくらい予測値が正しいか評価する必要があります
手法として「RMSE:Root Mean Squared Error」と呼ばれる指標についてご説明していきます
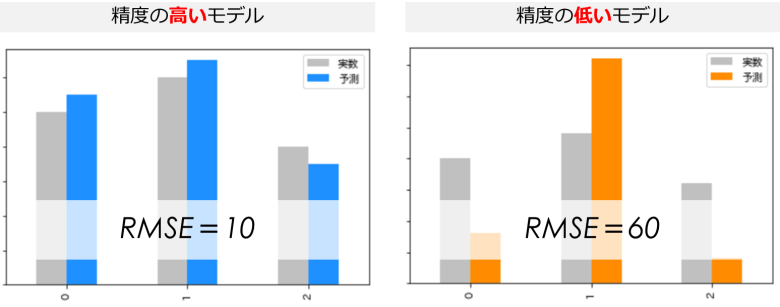
RMSEを使うと予測した値が実際の値(真の値)とどれくらい乖離しているかを、定量的把握することができます
数式からPythonでの実装方法までご説明します
RMSE(平均平方二乗誤差)
RMSEは回帰タスクで最も代表的な指標で、「Root Mean Squared Error」の略です
平均平方二乗誤差とも呼ばれる指標で、各レコードの「真の値」と「予測値」の差分を二乗して、平均を取った後に平方根を取ると算出できます
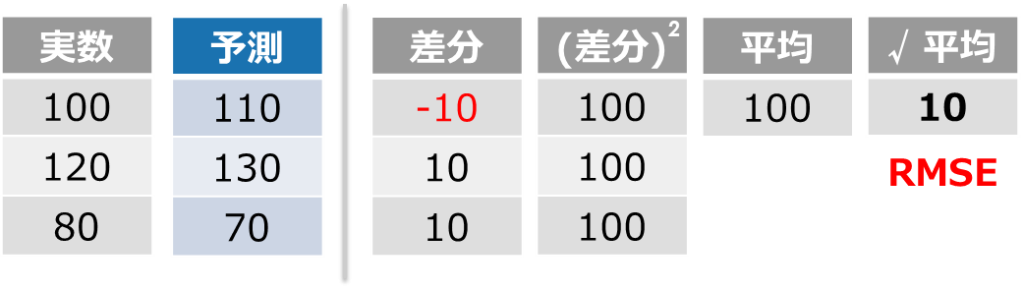
RMSEは最小値=0で、小さければ小さいほど良い指標です
正解の値と予測の値の差分を小さくするように機械学習モデルを修正します
Pythonでの算出方法
PythonでRMSEを算出するにはsklearnでmean_squared_errorを利用します
実はRMSE単体の関数ではなく、平方根(Root)が無い数値が算出されるため、Numpyで平方根を付ける必要があります
from sklearn.metrics import mean_squared_error
import numpy as np実数値と予測値の2つを用意して、mean_squared_errorに代入します
そこからsqrtを利用して、平方根を取ります
y_test = [100,120,80]
y_pred = [110,130,70]
rmse = np.sqrt(mean_squared_error(y_test,y_pred))
rmse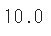
機械学習モデルでの実践
最後に機械学習モデルを使ってRMSEを算出する流れをご紹介します
事前準備
SeabornのTipsデータソースを使います
外国の食文化の一つである「チップ」についてのデータで、総額や性別、曜日やタバコの有無などから「チップ」の額を予測します
import seaborn as sns
import pandas as pd
df = sns.load_dataset('tips')
df.head()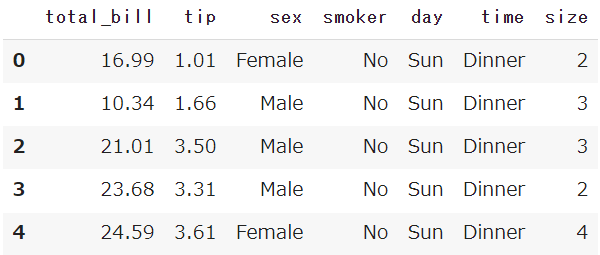
続いて説明変数(df_x)と目的変数(df_y)に分けて、get_dummiesで前処理をしておきます
df_x = df.drop('tip', axis=1)
df_x = pd.get_dummies(df_x)
df_y = df['tip']機械学習の予測
ランダムフォレスト(RandomForestRegressor)を使ってチップの額を予測します
変数pred_mlにチップの予測金額を代入します
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
train_x, test_x, train_y, test_y = train_test_split(df_x, df_y,random_state=1)
model = RandomForestRegressor(n_estimators=100,random_state=1)
model.fit(train_x,train_y)
pred_ml = model.predict(test_x)そして比較対象のため、もう一つチップの予測を行います
慣習としてチップの額は「食事の総額の20%」と言われているため、単純にtotal_bill(総額)を20%した数値を変数pred_tipとします
pred_tip = test_x['total_bill']*0.2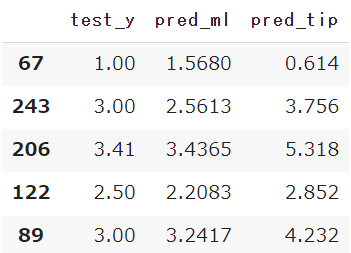
RMSEで精度を比較
テスト用の実数test_yを正解として、この2つをRMSEで比較します
from sklearn.metrics import mean_squared_error
rmse_ml = np.sqrt(mean_squared_error(test_y,pred_ml))
rmse_tip = np.sqrt(mean_squared_error(test_y,pred_tip))
print('rmse_ml',rmse_ml)
print('rmse_tip',rmse_tip)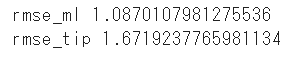
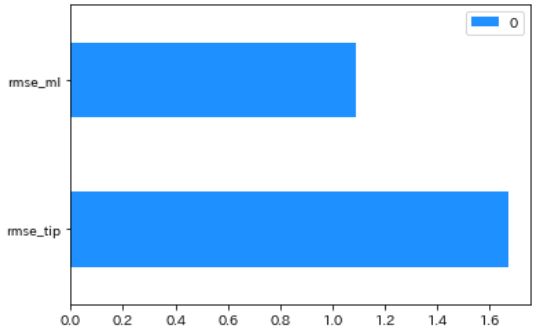
前述したとおり、RMSEは小さければ小さいほど良い指標です
機械学習モデルで予測した方が、雑に20%した方よりRMSEの値が小さい=精度が高いことが分かりました
まとめ
今回は機械学習モデルの回帰タスクを評価する指標であるRMSEについてご紹介してきました
回帰タスクで代表的な指標なので、ぜひ覚えて使ってみてください
分類タスクにおける指標についてはこちらで解説しています
 【機械学習】分類の評価指標を一番分かりやすく解説|confusion-matrix
【機械学習】分類の評価指標を一番分かりやすく解説|confusion-matrix


