 Smart-Hint
Smart-Hint 
目次
ポケモンのデータで学ぶPython
Python(パイソン)というプログラミング言語を、ポケモンという誰もが知っているコンテンツで学んでいく企画です
今回はPythonのDataFrameにあるデータがどのような構成になっているかを、一問一答形式で学んでいきます
- 基本統計量を調べる
- データの形式を調べる
「基本統計量」とはデータの基本的な特徴を表す値のことで、今回は平均や最大値・最小値、標準偏差などをの指数のことです
データの概要を知るには必須の指標のため、それぞれの抽出方法と一度に取得することができるdescribeメソッドをご紹介します
今回利用するデータについてや、Pythonのセットアップは下記記事をご覧ください
 ポケモンで学ぶデータ分析|データの中身を知ろう
ポケモンで学ぶデータ分析|データの中身を知ろう
 ポケモンで学ぶPython|#1 セットアップを始めよう
ポケモンで学ぶPython|#1 セットアップを始めよう
事前準備
Pandasを事前にインポートしておきます
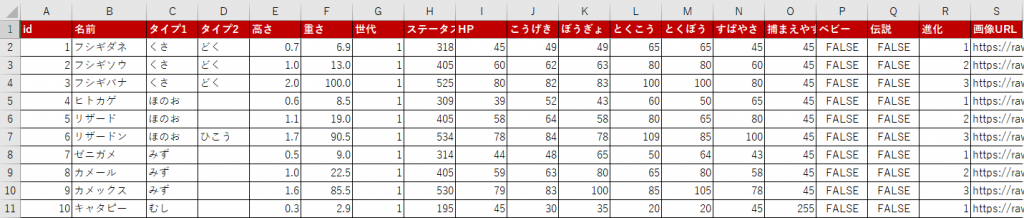
import pandas as pdポケモンのデータ(Excel:105 KB)をダウンロードし、Pythonで読み取ってください
# Pokemon_1のシートを変数(df)に格納する
df = pd.read_excel('pokemon_data.xlsx', sheet_name='Pokemon_1')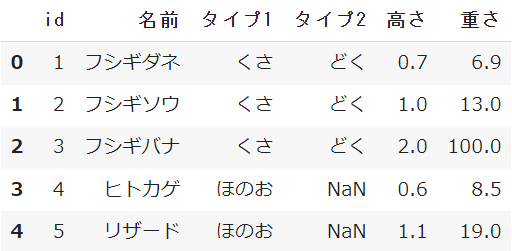
基本統計量を調べる
今回、ご紹介する基本統計量は下記5つです
- 平均:mean
- 中央値:median
- 最大値:max
- 最小値:min
- 標準偏差:std
もちろんこれ以外の分散や最頻値なども算出できますが、今回は割愛します
では基本的なデータの個数から始めていきましょう
データの行数を数えてください
len(df)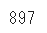
lenを使うことでデータの行数を算出することができます
 【Python】len|データ数を数える方法
【Python】len|データ数を数える方法
データの行数・列数を数えてください
df.shape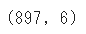
shapeを利用することで( 行数 , 列数 )を算出することができます
 【Python】DataFrameで行数・列数を確認する方法|shape
【Python】DataFrameで行数・列数を確認する方法|shape
カラムごとにデータ数(行数)を数えてください
df.count()
count関数を利用することで、カラム(列)ごとにデータの数を数えることができます
Null(データが無い)値は無視されてカウントされます
ポケモンの高さの「合計値」を取り出してください
df['高さ'].sum()![df['高さ'].sum()](https://smart-hint.com/wp-content/uploads/2021/11/image-64.png)
数値データに対してsum関数を実施することで、合計値を算出することができます
ポケモンの高さの「平均値」を取り出してください
df['高さ'].mean()![df['高さ'].mean()](https://smart-hint.com/wp-content/uploads/2021/11/image-65.png)
mean関数を使うことで、平均値を算出することができます
※AVERAGE(アベレージ)ではないので注意が必要です
ポケモンの高さの「中央値」を取り出してください
df['高さ'].median()![df['高さ'].median()](https://smart-hint.com/wp-content/uploads/2021/11/image-66.png)
中央値はmedian関数で算出することができます
ポケモンの高さの「最大値」を取り出してください
df['高さ'].max()![df['高さ'].max()](https://smart-hint.com/wp-content/uploads/2021/11/image-67.png)
最大値はmax関数を利用します
ポケモンの高さの「最小値」を取り出してください
df['高さ'].min()![df['高さ'].min()](https://smart-hint.com/wp-content/uploads/2021/11/image-68.png)
最小値はmin関数を利用します
ポケモンの高さの「標準偏差」を取り出してください
df['高さ'].std()![df['高さ'].std()](https://smart-hint.com/wp-content/uploads/2021/11/image-69.png)
標準偏差はstd関数を利用します
英語で標準偏差は「standard deviation」なので、その略称が関数になっています
基本統計量を取得してください
df.describe()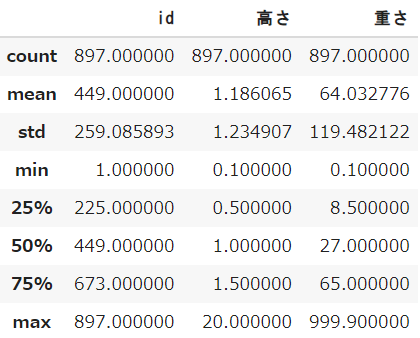
今まで算出してきた基本統計量を「一度に」取得する方法があります
describeを利用することで、表形式で必要な指標をまとめて算出することができます
指定が無い場合は「数値型データ」の全てが表示されます
 【Python】describe|全ての統計情報を一瞬で把握する方法
【Python】describe|全ての統計情報を一瞬で把握する方法
数値型以外の統計情報を取得してください
df.describe(include='object')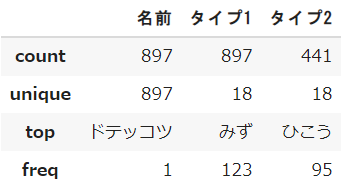
describeのincludeというパラメータを指定することで、数値型以外の情報を取得することができます
もちろん数値型ではないので「平均値」などは算出できませんが、その代わりにユニーク(重複無し)の個数や、出現が多い値とその出現回数が分かります
データの形式を調べる
続いてデータ型と呼ばれるデータの形式や、Null(データが無い)値を調べる方法です
データ型を取得してください
df.dtypes
dtypesを利用することで、カラムごとのデータ型を調べることができます
Pythonでは見た目からデータ型が分からないことがあるため、調べる癖を付けておきましょう
※他と違い( )括弧を付ける必要が無いので気を付けてください
カラムごとにデータが無い(Null)個数を数えてください
df.isnull().sum()
isnullを使うと、各データのNull値を「True・False」で判定することができます
そこからsumを合わせて組み合わせることで、Null値の数を数えることができます
 【Python】欠損値の扱い方大全
【Python】欠損値の扱い方大全
データ型とデータが存在している個数を一度に取得してください
df.info()
infoを利用するだけで、データ型とデータが存在している(Nullではない)数を数えることができます
先ほどのdescribeと同様に、まとめて調べることができるのでぜひ覚えて利用してください
まとめ
- 基本統計量を調べる
- データの形式を調べる
今回はデータの概要を知るというテーマで、基本統計量とデータの形式を調べる方法を一問一答形式でご紹介してきました
それぞれに関数が存在していますが、describeとinfoだけで十分に概要を知ることができるため、ぜひ使いこなして見てください


