

目次
ポケモンのデータで学ぶPython
Python(パイソン)というプログラミング言語を、ポケモンという誰もが知っているコンテンツで学んでいく企画です
今回はPythonで「文字列」を扱う方法をご紹介します
- 文字数を数える
- 文字列を変換する
- 文字列を分割する
- 大文字-小文字変換する
- 半角-全角変換する
今回利用するデータについてや、Pythonのセットアップは下記記事をご覧ください
 ポケモンで学ぶデータ分析|データの中身を知ろう
ポケモンで学ぶデータ分析|データの中身を知ろう  ポケモンで学ぶPython|#1 セットアップを始めよう
ポケモンで学ぶPython|#1 セットアップを始めよう 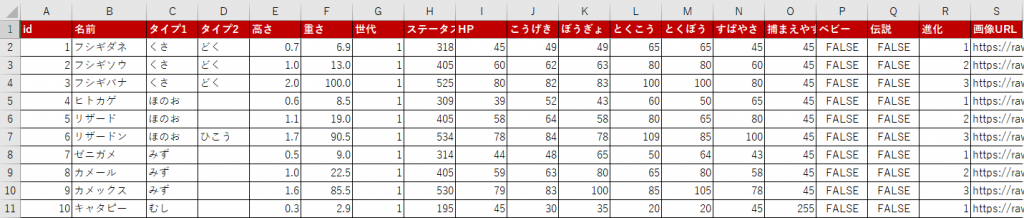
事前準備
Pandasを事前にインポートしておきます
import pandas as pdポケモンのデータ(Excel:105 KB)をダウンロードし、Pythonで読み取ってください
# Pokemon_Englishのシートを変数(df)に格納する
df = pd.read_excel('/content/drive/MyDrive/Python/API/pokemon_data.xlsx',
sheet_name='Pokemon_English')
df.head()
文字数を数える
名前の文字数を数えてください
df['名前'].apply(lambda x: len(x))![df['名前'].apply(lambda x: len(x))](https://smart-hint.com/wp-content/uploads/2022/01/image-45.png)
lenと関数lambdaを組み合わせて、文字数を数えます
名前に「ギ」が入っている数を数えてください
df['名前'].str.count('ギ')![df['名前'].str.count('ギ')](https://smart-hint.com/wp-content/uploads/2022/01/image-46.png)
countを活用して特定の文字列を数えます
文字列として扱うためにstrも忘れずに付けてください
名前に「ギ」か「ス」が入っている数を数えてください
df['名前'].str.count('ギ|ス')![df['名前'].str.count('ギ|ス')](https://smart-hint.com/wp-content/uploads/2022/01/image-47.png)
指定の文字列に|を使うと、OR条件で検索することができます
英語名のアルファベット(a~z)をそれぞれ数えてください【高難度】
df_alphabet = pd.DataFrame()
for i in [chr(ord("a")+i) for i in range(26)]:
temp = df['name'].str.count(i)
df_alphabet[i] = temp
df_alphabet = pd.concat([df[['名前','name']],df_alphabet], axis=1)
df_alphabet.head(10).style.background_gradient()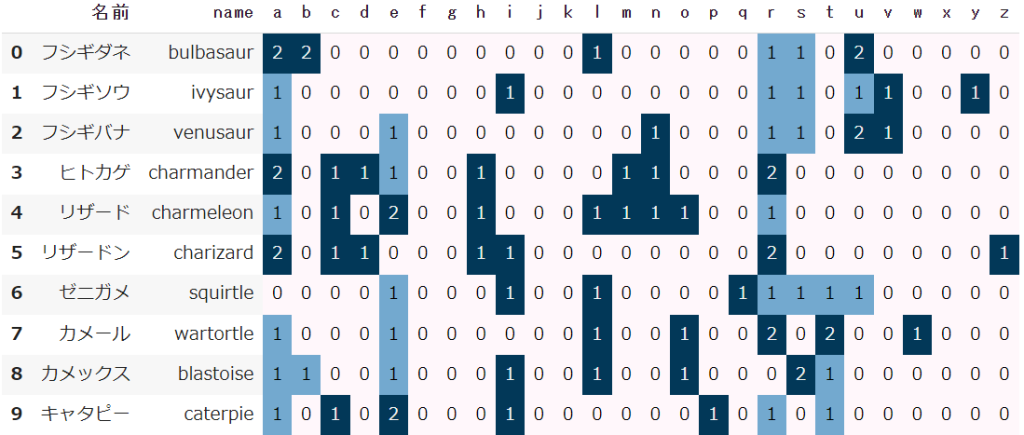
「a」から「z」までのアルファベットをリストで用意し、繰り返し処理で26文字分をcountで数えます
別の変数に格納しておき、名前とアルファベットの文字数をconcatで結合します
最後にstyleで色付けすると、非常に見やすくなります
 【Python】concat|複数のデータを連結する
【Python】concat|複数のデータを連結する  【Python】DataFrameを見やすくする方法|style
【Python】DataFrameを見やすくする方法|style 文字列を変換する
名前の「ヒトカゲ」を「***」に変換してください
df['名前'].replace('ヒトカゲ','***')![df['名前'].replace('ヒトカゲ','***')](https://smart-hint.com/wp-content/uploads/2022/01/image-49.png)
replaceを使うと文字列を変換することができます
 【Python】replace|データ内容を別の内容で置き換える(置換)
【Python】replace|データ内容を別の内容で置き換える(置換)名前の「ギ」を「*」に変換してください
df['名前'].replace('ギ','*',regex=True)![df['名前'].replace('ギ','*',regex=True)](https://smart-hint.com/wp-content/uploads/2022/01/image-56.png)
replaceのパラメータregexをTrueとすることで、一部の文字のみを変換することができます
文字列を分割する
名前の「ギ」をもとに文字列を分割してください
df['名前'].str.split('ギ')![df['名前'].str.split('ギ')](https://smart-hint.com/wp-content/uploads/2022/01/image-50.png)
splitを活用すると文字列を「分割」することができます
ただこのままだとリスト形式で使いにくいため、次の問題で列を増やします
 【Python】区切り文字で文字列を分割する方法|split
【Python】区切り文字で文字列を分割する方法|split名前の「ギ」をもとに文字列を分割し、列を増やしてください
df['名前'].str.split('ギ', expand=True)![df['名前'].str.split('ギ', expand=True)](https://smart-hint.com/wp-content/uploads/2022/01/image-51.png)
splitのパラメータexpandをTrueとすることで、分割結果を列として増やすことができます
大文字-小文字変換する
英語名を全て大文字にしてください
df['name'].str.upper()![df['name'].str.upper()](https://smart-hint.com/wp-content/uploads/2022/01/image-52.png)
初期値のポケモンの名前(name)はすべて小文字なので、upperを設定して大文字に変換します
strを前に付けないとエラーが出る可能性があるので注意です
 【Python】英語の大文字・小文字を変換する方法
【Python】英語の大文字・小文字を変換する方法英語名を全て小文字にしてください
df['name'].str.lower()![df['name'].str.lower()](https://smart-hint.com/wp-content/uploads/2022/01/image-53.png)
すでに全て小文字なので、特に作業は必要ありませんがlowerを使うことで小文字変換ができます
英語名を先頭だけ大文字にしてください
df['name'].str.capitalize()![df['name'].str.capitalize()](https://smart-hint.com/wp-content/uploads/2022/01/image-54.png)
capitalizeを使うと最初の文字だけを大文字に変換ができます
半角-全角変換する
半角-全角を変換するにはmojimojiを利用するため、事前にインストール・インポートしておきましょう
!pip install mojimoji
import mojimoji名前を半角に変換してください
df['名前'].apply(mojimoji.zen_to_han)![df['名前'].apply(mojimoji.zen_to_han)](https://smart-hint.com/wp-content/uploads/2022/01/image-55.png)
zen_to_hanを使うと半角-全角の変換を実施することができます
 【Python】文字列の全角・半角を変換する方法|mojimoji
【Python】文字列の全角・半角を変換する方法|mojimojiまとめ
今回は文字列をPythonで扱う方法についてご紹介してきました
- 文字数を数える
- 文字列を変換する
- 文字列を分割する
- 大文字-小文字変換する
- 半角-全角変換する
機械学習モデルの作成で、人の名前から特徴量を算出することがあります
ぜひ覚えて使ってみてください


