Smart-Hint
Smart-Hint 
目次
文字列の全角・半角を変換する方法
Pythonを利用し、文字列の全角と半角を変換する方法をご紹介します
文字列には全角・半角があり内容は同じですが、機械では別の文字列として扱われてしまいます
つまりテキストデータの解析の際に、エラーが出てしまう可能性があるということです
全角・半角の区別をなくすために、どちらかに変換する方法を解説します
- 「Python」と「Python」
- 「パイソン」と「パイソン」
- 「123」と「123」
事前準備
今回はmojimojiというライブラリを利用し、全角・半角を変換していきます
!pip install mojimoji
import mojimojiまた事前に全角・半角の文字列を準備しておきます
text_zen = 'Python パイソン 123'
text_han = 'Python パイソン 123'全角→半角に変換する方法
まずは全角(Python)を半角(Python)に変換する方法をご紹介します
zen_to_hanという非常に分かりやすい関数を利用します
テキストを引数に設定すると、簡単に全角→半角の変換を実装できます
print(mojimoji.zen_to_han(text_zen))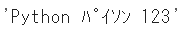
半角→全角に変換する方法
続いて半角(Python)を全角(Python)に変換する方法をご紹介します
han_to_zenというこちらも分かりやすい関数を利用します
print(mojimoji.han_to_zen(text_han))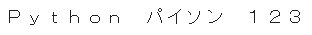
一部の変換を無効化する
zen_to_hanとhan_to_zenの2つの関数は「英字・カタカナ・数字」を全て変換しますが
特定の文字種類の変換を無効化することもできます
どちらも同じパラメータを利用します
英字の変換を無効化する
ascii=Trueとすることで、英字の全角・半角変換を無効化することができます
print(mojimoji.zen_to_han(text_zen))
print(mojimoji.zen_to_han(text_zen, ascii=False))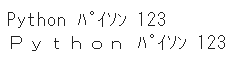
カタカナの変換を無効化する
kana=Trueとすることで、カタカナの全角・半角変換を無効化することができます
print(mojimoji.zen_to_han(text_zen))
print(mojimoji.zen_to_han(text_zen, kana=False))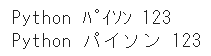
数字の変換を無効化する
digit=Trueとすることで、数字の全角・半角変換を無効化することができます
print(mojimoji.zen_to_han(text_zen))
print(mojimoji.zen_to_han(text_zen, digit=False))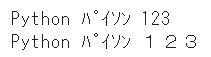
DataFrame(Series)に適応させる
最後にこの全角・半角の変換をDataFrame/Seriesに適応させる方法をご紹介します
Seabornというライブラリから、mpgという車のデータを取得しておきます
import seaborn as sns
df = sns.load_dataset('mpg')
df['name']![import seaborn as sns
df = sns.load_dataset('mpg')
df['name']](https://smart-hint.com/wp-content/uploads/2021/12/image-9.png)
この車のデータにある車名を意味している「name」のカラムに対して、半角→全角の変換を実施します
han_to_zenをDataFrame(Series)に適応させるにはapplyというメソッドを利用します
df['name'].apply(mojimoji.han_to_zen)
 【Python】作った関数を適応させるには?|apply
【Python】作った関数を適応させるには?|apply
まとめ
今回はPythonで文字列の全角・半角を変換する方法についてご紹介してきました
テキスト解析の際に、文字列統一のために必要になるのでぜひ使ってみてください