 Smart-Hint
Smart-Hint 
目次
Pythonで独自に作った関数を適応させる
Pythonではsumやmax、lenなど、よく使われる計算式は埋め込みの関数として自由に使うことができます
一方でdefやlambdaを使い、独自に関数を作成(定義)することも可能です
複雑な計算式を作り出すのはもちろん、データの特色に合わせて関数を作成することによって、自由自在にデータ加工することができます
今回はapply・applymapを使い、独自に作成した関数をSeriesやDataFrameに対して「適応」させる方法をご紹介していきます
事前準備
Pandasというデータ解析を実施できるライブラリをインポートします
import pandas as pd※サンプルデータ:学校のテストの点数

df.head()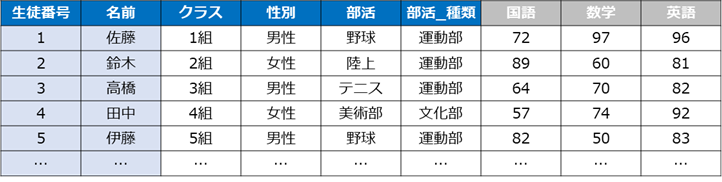
事前準備:defで関数を作る
事前準備としてdefを使い関数を作成しておきます
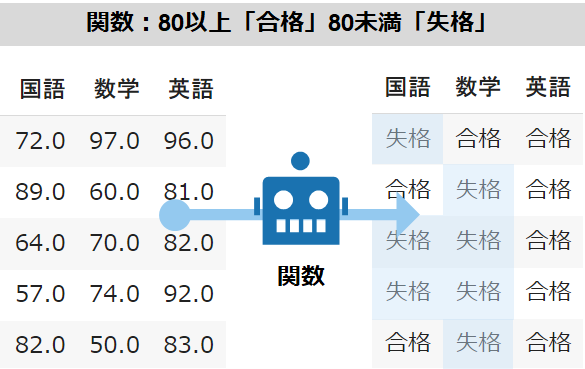
学校のテストを仕分ける関数(func)を下記の条件で作成します
テストの点数が80点以上なら「合格」、80点未満なら「失格」
def func(x):
if x >= 80:
return '合格'
elif x < 80:
return '失格'関数の作成方法についてはこちらの記事をご覧ください
 【Python】関数で独自の計算式を作る方法とは?|def
【Python】関数で独自の計算式を作る方法とは?|def
applyはSeriesに適応
まずはSeries(DataFrameの単一列)の各要素に対して関数を適応させる方法をご紹介します
applyを記述し、事前に作成した関数を引数として渡します
※最初のコードは準備のため英語の点数をSeriesの形式で取り出しています
# Seriesとして英語の点数を用意してます
English = df['英語']
English.apply(func)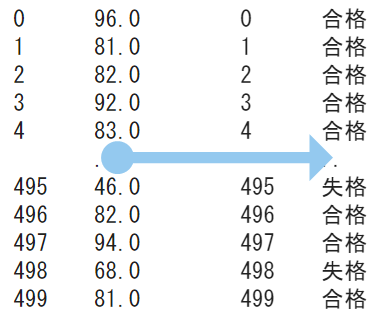
また無名関数のlambdaも利用することが可能です
English.apply(lambda x: '合格' if x>=80 else '失格')applymapはDataFrameに適応
続いてapplymapを使うことでDataFrameに対して関数を適応することができます
使い方はapplyと同じで、事前に作った関数を渡します
df[['国語','数学','英語']].applymap(func)![df[['国語','数学','英語']].applymap(func)](https://smart-hint.com/wp-content/uploads/2021/09/image-34.png)
関数を適応する際の注意点
注意点①:変数の更新
apply・applymapはともに関数を適応した結果を出しますが、元のオブジェクトが変更されるわけではありません
元の変数を更新する形で適応させる必要があります
df['英語'] = df['英語'].apply(func)注意点②:データ型
DataFrameの中にデータ型が混在している場合は、関数が適応できずエラーになる可能性があります
例えば今回defで定義したfuncという関数は、数値型に対して「合格・失格」を振り分けるものでした
つまりその他の文字列型や日付型が対象の場合はエラーが出てしまいます
df.applymap(func)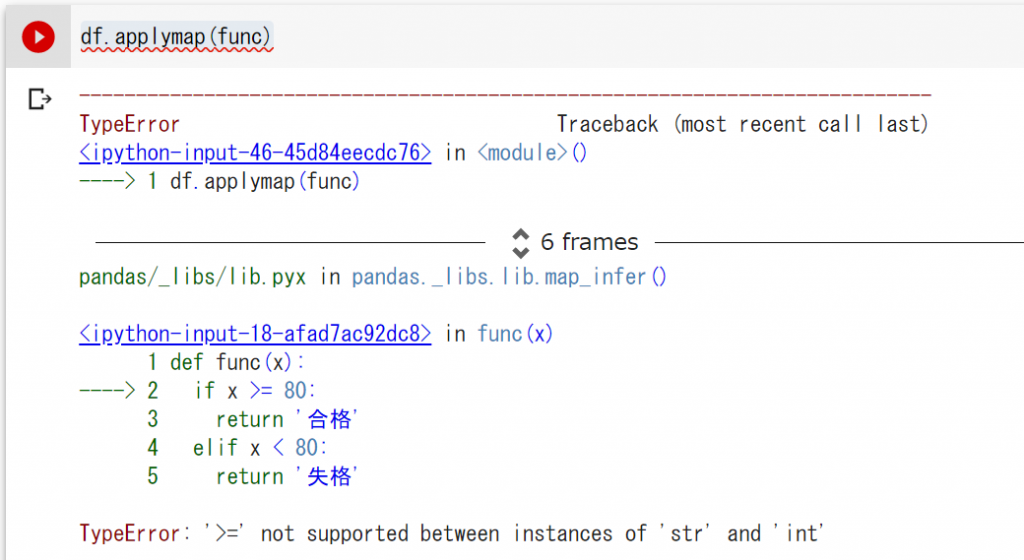
事前にDataFrameのデータ型を確認します
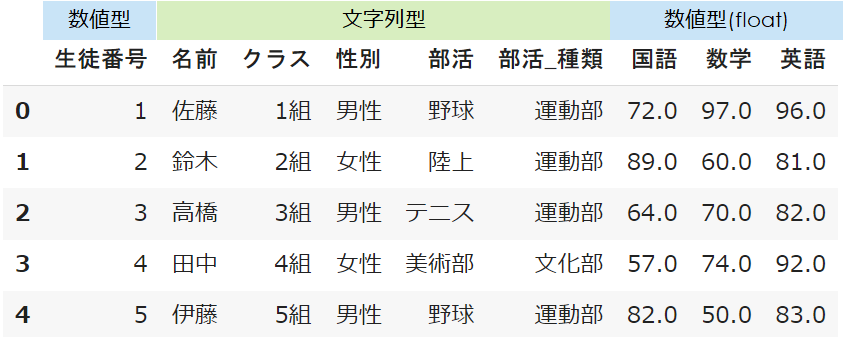

applymapを利用するのは数値型(float)の国語・数学・英語の点数のみなので、抽出したうえで関数を当てはめましょう
まとめ
今回は独自に作成した関数をSeries・DataFrameに適応させる方法をご紹介しました
apply・applymapは柔軟なデータ分析に必須なスキルなので、ぜひ覚えて使ってみてください
【Python】関数で独自の計算式を作る方法とは?|def


