Smart-Hint
Smart-Hint 
目次
データをビニング(ビン分割)する方法
今回はPythonのcutを利用して、データをビニング(ビン分割)する方法をご紹介します
「ビニング」は聞きなれないワードかもしれませんが、単純に複数のデータを処理しやすいようにまとめるイメージをしてください
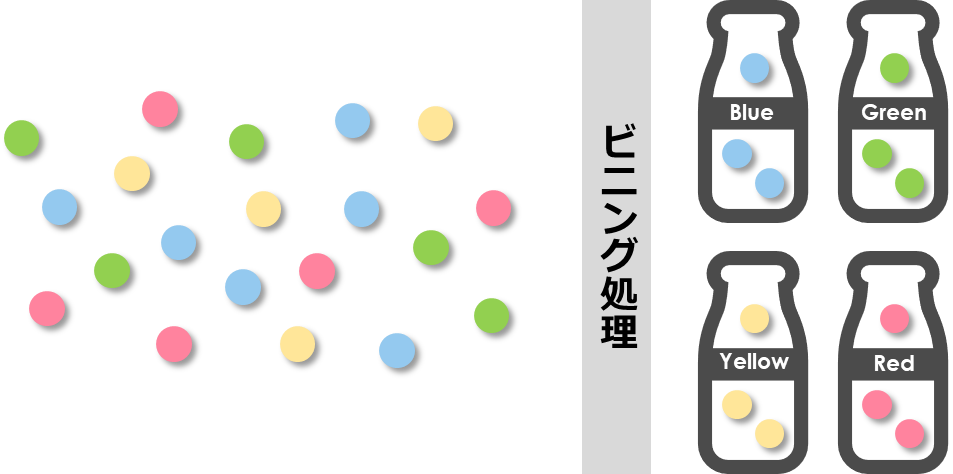
データは「あればあるだけ良い」訳ではなく、機械でも簡単に理解できるようにまとめる処理が必要になる場合があります
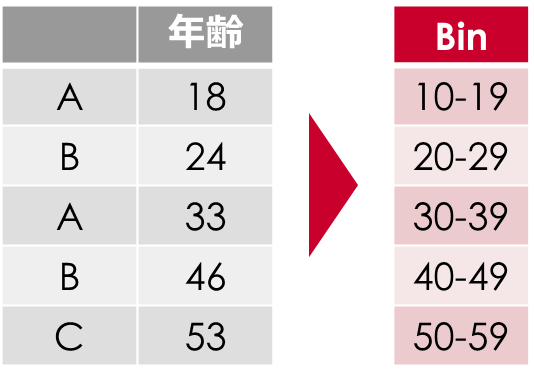
例えば「年齢」のデータでも、「23歳、35歳、48歳」とするより「20代、30代、40代」とまとめることはよくありますよね
Pythonではcutを使い、データをカット(区切る)ことでビニング処理を実施していきます
事前準備
Seabornというライブラリから、タイタニック号のデータを取得しておきます
またPandasも合わせてインポートしておきます
import seaborn as sns
import pandas as pd
df = sns.load_dataset('titanic')
df.head()
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介します
cutの使い方
タイタニック号の「年齢:age」のデータに対してcutを利用してビニング処理を実施します
最低限必要な項目は「対象のデータとなる変数」と「分割数(ビン数)」です
変数に指定されたデータを、最大値と最小値の間を等間隔で分割します
また( ○○より大きく , ○○以下 ] の表示で抽出されます
pd.cut(df['age'], 4)![pd.cut(df['age'], 4)](https://smart-hint.com/wp-content/uploads/2021/12/image-13.png)
value_countsを組み合わせることで、ビンごとの出現回数を算出することができます
pd.cut(df['age'], 4).value_counts()![pd.cut(df['age'], 4)](https://smart-hint.com/wp-content/uploads/2021/12/image-14.png)
パラメータ
パラメータを設定することで、データの区切り方を調整することができます
おすすめ度を判定:★★★=必須|★★☆=推奨|★☆☆=任意
★★★:x(対象のデータ)
第一引数のxはPythonのリストで対象のデータを指定します
※パラメータのxは記述する必要はありません
pd.cut(df['age'])★★★:bins(区切る数)
続いてbinsに区切る数(ビン数)を指定します
※こちらもbinsを記述する必要はありません
pd.cut(df['age'], 4)binsに対して「数値」ではなく「リスト」を指定すると、区切る境界を指定することができます
※リストに指定した範囲外のデータはNaNとなります
pd.cut(df['age'], [0,10,20,30,40,50,60])![pd.cut(df['age'], [0,10,20,30,40,50,60])](https://smart-hint.com/wp-content/uploads/2021/12/image-15.png)
★★☆:labels(ラベル)
labelのパラメータを指定することで、区切ったビンに対して名称を付けることができます
「分割する数」と「ラベルの数」を合わせる必要があります
pd.cut(df['age'], [0,10,20,30,40,50,60],
labels=['0s','10s','20s','30s','40s','50over'])![pd.cut(df['age'], [0,10,20,30,40,50,60],
labels=['0s','10s','20s','30s','40s','50over'])](https://smart-hint.com/wp-content/uploads/2021/12/image-16.png)
labelを「False」で設定すると、「0」始まりの連番が振られます
pd.cut(df['age'], 5, labels=False)![pd.cut(df['age'], 5, labels=False)](https://smart-hint.com/wp-content/uploads/2021/12/image-18.png)
★☆☆:precision(境界の小数点)
precisionに数値を指定すると、区切る境界の小数点以下の桁数を設定できます
pd.cut(df['age'], 10, precision=0)![pd.cut(df['age'], 10, precision=0)](https://smart-hint.com/wp-content/uploads/2021/12/image-17.png)
★☆☆:right(左右どちらに含むか)
デフォルトではright が「True」となっているため、( ○○より大きく , ○○以下 ] の形で表示されます
一方で「False」を指定すると、( ○○以上 , ○○未満 ] の形になります
pd.cut(df['age'], 5, right=False)派生のqcut
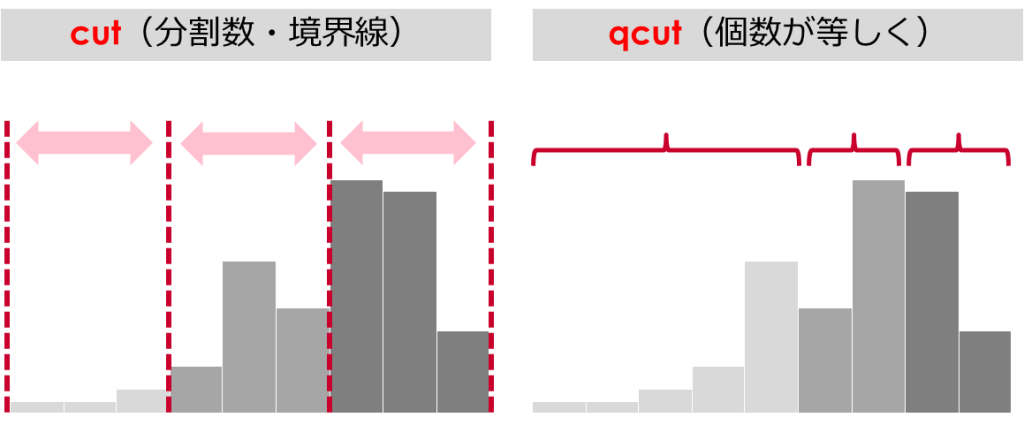
Pythonでビニング処理を実施するにはcutに加えて、qcutという派生も存在しています
cutは値に対して分割数や境界値を指定して分割するのに対して、
qcutは各ビンに含まれる個数が等しくなるように分割を実施します
qcutの使い方
qcutはcutとほぼ同じパラメータを利用することができます
xに対象のデータを指定し、qに分割数を指定します
pd.qcut(df['age'], 2)![pd.qcut(df['age'], 2)](https://smart-hint.com/wp-content/uploads/2021/12/image-20.png)
qcutは個数で分割をするため、qを「2」に設定すると中央値で分割され、「4」に設定すると四分位数で分割されます
まとめ
今回はPythonのcutや派生のqcutを利用して、データをビニング(ビン分割)する方法をご紹介してきました
様々なパラメータが存在していますが、ぜひこの機会に覚えて使ってみてください