
目次
重複したデータを抽出・削除する方法
今回はPythonでデータを操作する際に、「重複」したデータを見つける方法をご紹介します
またそのデータを削除する方法も合わせてご説明します
データによっては全く同じデータが重なって入ってしまい、分析に悪影響を及ぼす場合があります
それを防ぐために「重複」を見つけ出し、消す必要があります
duplicatedを利用することで重複行を見つけることができ、
drop_duplicatesで重複行を削除することが可能です
事前準備
Seabornというライブラリから、タイタニック号のデータを取得しておきます
またPandasも合わせてインポートしておきます
import seaborn as sns
import pandas as pd
df = sns.load_dataset('titanic')
df.head()
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介します 重複行を抽出する(duplicated)
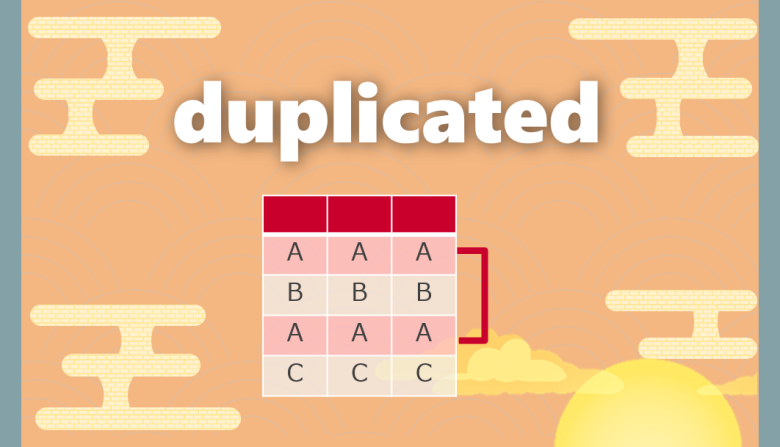
duplicatedをDataFrameに対して実施すると、行全体で同じ項目がある場合に「True」を返します
重複がない場合は「False」となり、重複がある場合の2つ目以降は「True」となります
df.duplicated()
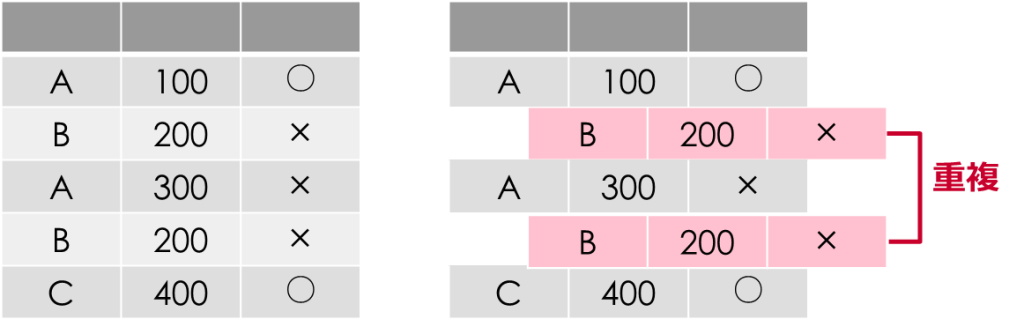
重複したデータを判別するのではく、重複したデータをDataFrameとして抽出することもできます
df[df.duplicated()]![df[df.duplicated()]](https://smart-hint.com/wp-content/uploads/2021/12/image-2-1024x386.png)
さらにsumを続けることで、重複した行を数えることができます
df.duplicated().sum()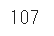
重複行を削除する(drop_duplicates)
drop_duplicatesを利用することで、重複した行を削除することが可能です
重複行が削除された状態のDataFrameが表示されます
df.drop_duplicates()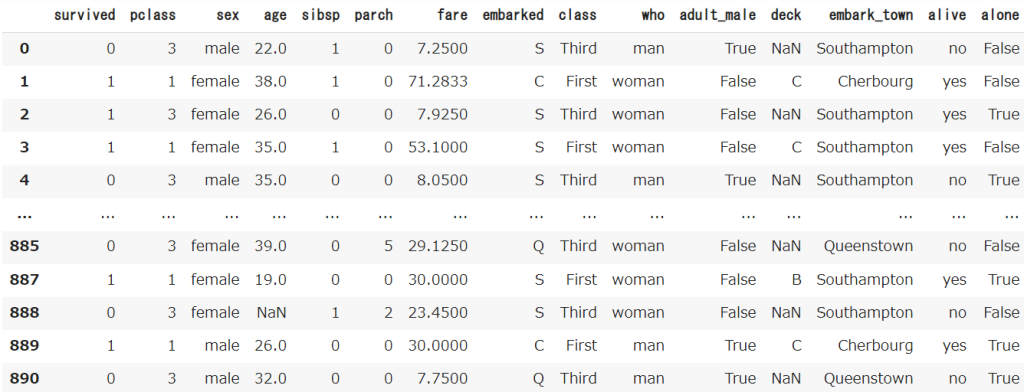
drop_duplicatesで抽出できるのは新しいDataFrameです
元のデータ自体を更新するにはパラメータのinplaceを指定しましょう
df.drop_duplicates(inplace=True)パラメータ
duplicatedとdrop_duplicatesの両方とも同じパラメータを利用できるので、合わせてご紹介します
おすすめ度を判定:★★★=必須|★★☆=推奨|★☆☆=任意
★★☆:subset(列を指定)
subsetで列名を指定することで、重複の対象とする列を指定することができます
※初期設定(指定なし)では、すべての列に対して重複かどうかを判断します
df.duplicated(subset='sex')
「性別」は2種類しかないため、3行目から重複を意味する「True」となります
複数列を指定するにはリスト型で並べます
df.duplicated(subset=['sex','class'])★★☆:keep(残す行を選択)
keepを指定することで、重複行に対して残す行を指定することができます
つまり重複行が2つあった場合、「重複=True」となるのがどの行かを選ぶことができます
- keep = ‘first’(最初の行がFalse、それ以降がTrue)※デフォルト
- keep = ‘last’(最後の行がFalse、それ以前がTrue)
- keep = False(重複した行すべてがTrue)

まとめ
今回はPythonでデータを操作する際に、「重複」したデータを見つける方法をご紹介してきました
メソッドを利用することで、非常に簡単に重複を抽出したり削除したりすることができます
ぜひ使ってみたください


