

目次
KFoldでクロスバリデーション
機械学習のモデル評価で行うクロスバリデーションで利用するKFoldをご紹介します
「クロスバリデーション」とは、モデルの良し悪しを判断する「バリデーション(検証)」の中で、学習用-テスト用データに交互に分割する手法です
バリデーション(検証)についてはこちらの記事でご紹介しているので割愛します
 【機械学習】バリデーション(検証)をグラフィック解説
【機械学習】バリデーション(検証)をグラフィック解説事前準備
今回の主役であるKFoldをインポートしておきます
またSeabornから、タイタニック号のデータを取得しておきます
またPandas/ Numpyも合わせてインポートしておきます
from sklearn.model_selection import KFold
import seaborn as sns
import pandas as pd
import numpy as np
df = sns.load_dataset('titanic')
df.head()
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介します KFoldの基本的な使い方
kfを事前に定義しておき、splitに変数を代入することで分割を行います
この際、forを使って繰り返し処理を実施する必要があります
「0」~「4」までの5つの連番のリストを、交互に学習用-テスト用に分割します
x = np.arange(5)
kf = KFold()
for i in kf.split(x):
print(i)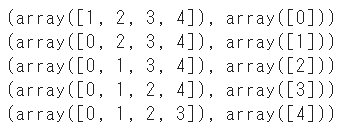
DataFrameはインデックスが返される
KFoldで注意が必要なのは、分割した後に「インデックス」がリストとして返される点です
kf = KFold()
for train_index, test_index in kf.split(df):
print(train_index)
ilocを組み合わせることで、データそのままを取得することも可能です
kf = KFold()
for train_index, test_index in kf.split(df):
print(df.iloc[train_index])![kf = KFold()
for train_index, test_index in kf.split(df):
print(df.iloc[train_index])](https://smart-hint.com/wp-content/uploads/2022/01/image-22.png)
パラメータ
パラメータを設定することで、データの区切り方を調整することができます
おすすめ度を判定:★★★=必須|★★☆=推奨|★☆☆=任意
★★★:n_splits(分割個数)
n_splitsはクロスバリデーションの分割回数を指定することができます
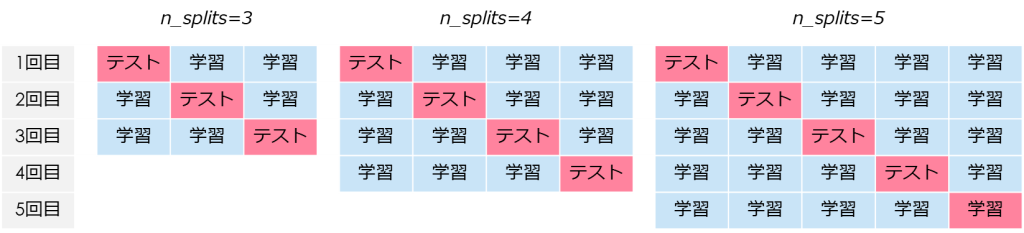
理論上、何分割もできますが「3」~「5」分割することを推奨します
分割する個数が増えれば増えるほど、システム負荷が高まり時間がかかりすぎてしまうためです
★★☆:shuffle(シャッフル)
shuffleを「True」に指定するとデータをランダムに抽出して学習用-テスト用に分割します
何も指定しないと「False」となっているので、指定が推奨です
x = np.arange(10)
kf = KFold(n_splits=5, shuffle=True)
for i in kf.split(x):
print(i)
★★☆:random_state(乱数シード)
random_stateに数値を指定すると、分割するときのランダム性を固定することができます
一方で指定しない場合は、毎回ランダムで分割が実施されます
kf = KFold(n_splits=5, shuffle=True, random_state=1)実際に機械学習のモデルで実施してみる
KFoldを実際に機械学習のモデルを使って実施していきます
① 前処理の実施
上記のタイタニック号のデータには、機械学習のモデル(ランダムフォレスト)で読み込めないものがあるので除外していきます
また説明変数(df_x)と目的変数(df_y)の2つの変数を準備しておきます
df_x = df.drop(['survived','alive'], axis=1)
df_x = pd.get_dummies(df_x)
df_x = df_x.fillna(0)
df_y = df['survived']ダミー変数化や欠損値処理はこちらを参照ください
 【Python】カテゴリ変数の数値変換|ダミー処理(one-hot encoding / label encoding)
【Python】カテゴリ変数の数値変換|ダミー処理(one-hot encoding / label encoding)  【Python】欠損値の扱い方大全
【Python】欠損値の扱い方大全 ② 機械学習モデルと評価指標をインポート
今回はランダムフォレスト(RandomForestRegressor)を機械学習として利用し、AUC(roc_auc_score)を評価とします
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import roc_auc_score③ 分割ごとにスコアを算出
説明変数のみKFoldに代入し、学習用-テスト用に分割します
このインデックスを目的変数の変数(df_y)に対しても利用します(※インデックスは同じなので)
ランダムフォレストで予測をした結果のスコアを、「scores」に格納していきます
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import KFold
kf = KFold(n_splits=4, shuffle=True, random_state=1)
scores = []
for train_index, test_index, in kf.split(df_x):
train_x = df_x.iloc[train_index]
test_x = df_x.iloc[test_index]
train_y = df_y.iloc[train_index]
test_y = df_y.iloc[test_index]
model = RandomForestRegressor(n_estimators=100,random_state=1)
model.fit(train_x,train_y)
pred = model.predict(test_x)
score = roc_auc_score(test_y, pred)
scores.append(score)
print(score)
print('平均スコア',np.mean(scores))
4回分のスコアと、その平均を算出することができました
cross_val_scoreでスコア算出
最後にKFoldによるスコアを算出を、sklearnのcross_val_scoreを活用して算出する方法をご紹介します
※こちらの方がコードを短く記述できます
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100,random_state=1)
score = cross_val_score(model, df_x, df_y, scoring='roc_auc', cv=4)
print(score)
print(np.mean(score))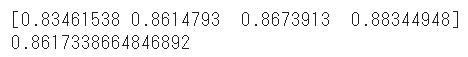
cross_val_scoreに対してモデル、説明変数、目的変数、スコアリング手法、分割回数を指定するだけでスコアが算出されます
簡単にスコア算出可能なのでぜひ試してみてください
まとめ
今回は機械学習のモデル評価で行うクロスバリデーションで利用するKFoldをご紹介してきました
モデル検証に必須のスキルなのでぜひ覚えて使ってみてください
またバリデーション(検証)についてはこちらをご覧ください
 【機械学習】バリデーション(検証)をグラフィック解説
【機械学習】バリデーション(検証)をグラフィック解説 

