

目次
LightGBMとは?
LightGBM(ライト・ジービーエム)は勾配ブースティング木の一種で、マイクロソフトが開発した非常に精度の高い機械学習のモデルです
勾配ブースティング木で最も有名なXGBoostのアルゴリズムに非常に似ていますが、LightGBMはその名の通り「Light(軽くて速い)」のが支持され、最も人気のあるモデルです
今回は2つのモデルの違いや実装方法についてご紹介していきます
 【機械学習】勾配ブースティング木のイメージを図解|GBDT
【機械学習】勾配ブースティング木のイメージを図解|GBDT  【機械学習】XGBoostを分かりやすく実践|XGBoost
【機械学習】XGBoostを分かりやすく実践|XGBoost LightGBMとXGBoostの違い
勾配ブースティング木のLightGBMとXGBoostの大まかな違いはコチラです
- 精度はどちらも同じ
- LightGBMの方が高速
- LightGBMの方が大量のデータの処理に優れている
上記の理由から、近年はLightGBMの方がコンペや実務で利用される機会は多いです
ではどうして処理の速さに差分が出るのでしょうか?
理由はアルゴリズムに2つの差分があるためです
深さ単位ではなく、葉単位での分岐する
勾配ブースティング木では「決定木」のモデルを複数つなげることにより精度を高めます
この決定木の分岐を深さ単位(Level-Wise)で行う方法と、葉単位(Leaf-Wise)で行う方法があります
XGBoostは深さ単位で、LightGBMが葉単位で分岐を行います
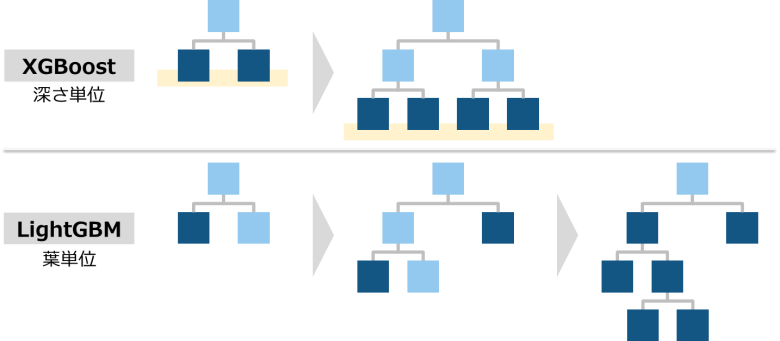
LightGBMでは図の下側のように、葉単位で最も目的関数を減少させる分割を行います
深さ単位の分岐より利用する情報を限定できるため、素早く処理することが可能です
数値をヒストグラムベースで分岐する
LightGBMは決定木の分岐をする際、全ての数値を見るのではなくヒストグラムを作って数値をまとめて分岐させます
そのおかげで細かい数値を見る必要が無いため、高速で処理できます
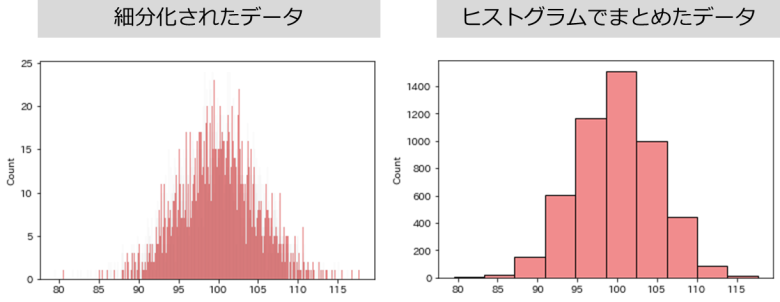
XGBoostでもtree_methodを「hist」とすることで、LightGBMのような処理が可能です
ここからはPythonでの実装方法についてご紹介していきます
事前準備
Seabornから、タイタニック号のデータを取得しておきます
またPandasも合わせてインポートしておきます
import seaborn as sns
import pandas as pd
df = sns.load_dataset('titanic')
df.head()
 【Python】初心者向けタイタニック号のサンプルデータをご紹介します
【Python】初心者向けタイタニック号のサンプルデータをご紹介しますLightGBMの前処理
LightGBM(勾配ブースティング木)は以下の特徴があり、事前に前処理する必要があります
- 特徴量は数値形式(1.2.3…)
- 欠損値を扱うことができる
- 学習-テストデータを指定の構造にする必要がある
事前準備で用意したタイタニック号のデータを使って、LightGBMで生存者の予測のための前処理を行います
説明変数(x)と目的変数(y)に分割
事前準備で用意した変数(df)を説明変数と目的変数に分割します
生存者を示す(survivedとalive)を取り除きましょう
df_x = df.drop(['survived','alive'], axis=1)
df_y = df['survived']![df_x = df.drop(['survived','alive'], axis=1)](https://smart-hint.com/wp-content/uploads/2022/01/image-133-1024x207.png)
ダミー変数処理(文字列→数値)
get_dummiesで文字列型のデータを数値型(0-1)に変換します
df_x = pd.get_dummies(df_x)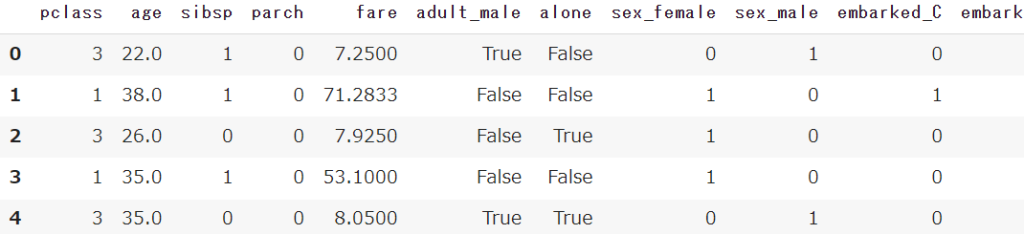
 【Python】カテゴリ変数の数値変換|ダミー処理(one-hot encoding / label encoding)
【Python】カテゴリ変数の数値変換|ダミー処理(one-hot encoding / label encoding)学習用-テスト用に分割
train_test_splitを使って、学習用とテスト用にデータを分割します
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(df_x, df_y, random_state=1)
 【機械学習】学習-テストデータに分割(hold-out法)|train_test_split
【機械学習】学習-テストデータに分割(hold-out法)|train_test_splitLightGBM用にデータを加工する
lgb.Datasetを使い、学習用・テスト用データに作成したデータを加工します
import lightgbm as lgb
lgb_train = lgb.Dataset(train_x, train_y)
lgb_test = lgb.Dataset(test_x, label=test_y)LightGBMのパラメータとモデル作成
モデル学習の前に、パラメータを事前に設定しておきましょう
objectiveで目的変数を指定します
- 「regression」:回帰
- 「binary」:2クラス分類で確率を返す
metricで最小化する評価指標を指定します
- 「binary_logloss」:logloss
- 「rmse」:平均二乗偏差
- 「auc」:AUC
アウトプットを一定にするためrandom_stateを任意の数値で指定しましょう
学習回数もnum_roundで指定することができます
params = {'objective':'binary',
'metrics':'binary_logloss',
'random_state':1}
num_round = 50lgb.trainでモデルを作成、学習します
事前に設定したパラメータを指定しましょう
- params:上記で設定したパラメータ
- lgb_train:学習用のデータ
- valid_sets:学習-テストデータ
- verbose_eval:学習結果のアウトプットを省略する間隔
- num_boost_round:最大の分岐回数
- valid_names:ラベル
model = lgb.train(params,
lgb_train,
valid_sets=[lgb_train, lgb_test],
verbose_eval=10,
num_boost_round=num_round,
valid_names=['train','test'])
LightGBMの評価
今回は2クラス分類のためlog_lossで評価を行います
predictでモデルに対して予測を行い、正解データ(テストデータ)とのスコアを比較します
from sklearn.metrics import log_loss
pred = model.predict(test_x)
score = log_loss(test_y, pred)
print(f'{score:.4f}')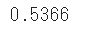
2値分類におけるpredictは予測結果を確率(0.85)で返しますが、「0」か「1」かで表現したい場合はこのように変換してください
import numpy as np
np.where(pred > 0.5, 1, 0)まとめ
今回は勾配ブースティング木の一種であるLightGBMについてご紹介してきました
その名の通り(Light:軽い)非常に高速で実装できるため、実務でも大活躍します
ぜひご活用ください
全てのコード
# 事前準備
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from sklearn.metrics import log_loss
# タイタニック号のデータを取得
df = sns.load_dataset('titanic')
# 説明変数と目的変数に分割
df_x = df.drop(['survived','alive'], axis=1)
df_y = df['survived']
# 前処理(ダミー変数化)
df_x = pd.get_dummies(df_x)
# 学習用-テスト用に分割
train_x, test_x, train_y, test_y = train_test_split(df_x, df_y, random_state=1)
# LightGBM専用のデータ処理
lgb_train = lgb.Dataset(train_x, train_y)
lgb_test = lgb.Dataset(test_x, label=test_y)
# LightGBMのパラメータ設定
params = {'objective':'binary',
'metrics':'binary_logloss',
'random_state':1}
num_round = 50
# LightGBMのモデル作成と予測
model = lgb.train(params,
lgb_train,
valid_sets=[lgb_train, lgb_test],
verbose_eval=10,
num_boost_round=num_round,
valid_names=['train','test'])
# LightGBMのモデル評価
pred = model.predict(test_x)
score = log_loss(test_y, pred)
print(f'{score:.4f}')

